This chapter leaves the setting of scalar measures on a common ambient
space. Vector- and matrix-valued OT transports mass with internal degrees of
freedom, Gromov--Wasserstein compares metric-measure spaces without a
prescribed correspondence, and quantum OT replaces scalar couplings by
positive operators. In each case, the transport plan must also encode
structure carried by the support, the fibers, or the non-commutative state
space.
from pathlib import Path
import sys
from IPython.display import Image as DisplayImage
from IPython.display import display
here = Path.cwd()
myst_dir = None
for candidate in [here, here.parent, here / "myst", here.parent / "myst", here.parent.parent / "myst"]:
if (candidate / "ot4ml_web.py").exists():
myst_dir = candidate.resolve()
sys.path.insert(0, str(myst_dir))
break
if myst_dir is None:
raise RuntimeError("Could not locate myst/ot4ml_web.py")
repo_root = myst_dir.parent
thumbnails = repo_root / "notebooks-figures" / "thumbnails"
def show_book_figure(name, width=760):
display(DisplayImage(filename=str(thumbnails / f"{name}.png"), width=width))
Scalar OT transports a nonnegative density. In imaging, color processing,
spectral analysis, diffusion tensor imaging and quantum-inspired models, the
object attached to a point can instead have several nonnegative components or
a positive semidefinite matrix. The first step beyond scalar OT is the
positive vector-valued case: the fiber remains linear and commutative, but
the transport cost may couple its channels.
The simplest way to keep internal structure in transport is to attach several
nonnegative masses to each spatial point and to decide whether these channels
move independently or interact through the cost.
This models multi-channel densities such as color histograms, spectral bins
or several species transported on the same domain. In a conservative model
the mass of each channel is preserved, so one assumes
α0k(X)=α1k(X) for every k. The natural vector-valued extension
therefore starts from the positive cone R+m.
For the dynamic formulas below, assume that X is either Rd, the flat
torus, or a bounded convex domain in Rd equipped with no-flux boundary
conditions. First suppose that the endpoints and the curve have densities.
The direct analogue of Benamou--Brenier fixes a vector
density ut(x)∈R+m and a spatial flux
Vt(x)=(Vt,1,…,Vt,d)∈(Rm)d, where Vt,ℓk is the
momentum of channel k in spatial direction ℓ. The conservative vector
transport cost associated with an action density Φ is
Thus each component satisfies its own continuity equation, but the cost may
still couple the components. Singular curves are handled as in scalar dynamic
OT by replacing densities and fluxes by measures and using the lower
semicontinuous perspective recession convention.
A simple quadratic family is obtained from a mobility matrix
M(u)∈S+m:
with the usual convention that the value is finite only when each Vℓ
belongs to the range of M(u). If u↦M(u) is linear
and takes values in S+m, this action is jointly convex and
positively one-homogeneous in (u,V). Indeed, the matrix fractional map
(M,z)↦z⊤M†z is jointly convex on its effective domain,
and M(su)=sM(u) for s>0. For m=1 and
M(u)=u, one
recovers exactly the scalar Benamou--Brenier action. For
the channels move independently. Non-diagonal mobilities are the simplest way
to couple the coordinates while keeping the same componentwise conservation
law. For instance, with q=m−1/2(1,…,1) and κ≥0,
increases the mobility in the common channel direction q while leaving
transverse directions controlled by the diagonal part. The local cost of
moving one component can therefore depend on the densities and momenta of the
other components, even though each component mass remains conserved.
Proof
For Mdiag(u)=diag(u1,…,um), the
action separates as
where Vk=(V1k,…,Vdk) is the spatial momentum of channel k. The
constraint (3) also separates into
∂tuk+∇⋅Vk=0. The minimization therefore splits into
m independent scalar Benamou--Brenier problems. If mk>0, normalizing
ρtk=utk/mk and ptk=Vtk/mk factors the channel action as
mk∫∣ptk∣2/ρtk, hence the scalar value is the displayed
mkW22 term. If mk=0, nonnegativity and conservation force the
whole channel to vanish. Summing over all channels proves the claim.
The conservative positive-cone model above is the basic extension of
Benamou--Brenier. Adding a source term
∂tu+∇⋅V=S and a convex perspective penalty in S gives
unbalanced or reaction--transport variants
Maas et al., 2015Maas et al., 2016Dolbeault et al., 2009Mielke, 2013.
These generalized transport models include dissipation and density
modulation. The figure below contrasts the exact diagonal case
κ=0, where each positive channel is transported by its quantile map,
with a large-κ illustrative common-mode interpolation in which the
channels move more coherently. The endpoints are two-mode mixtures: at each
spatial mode the two channels have Gaussian profiles with the same center
but different amplitudes.
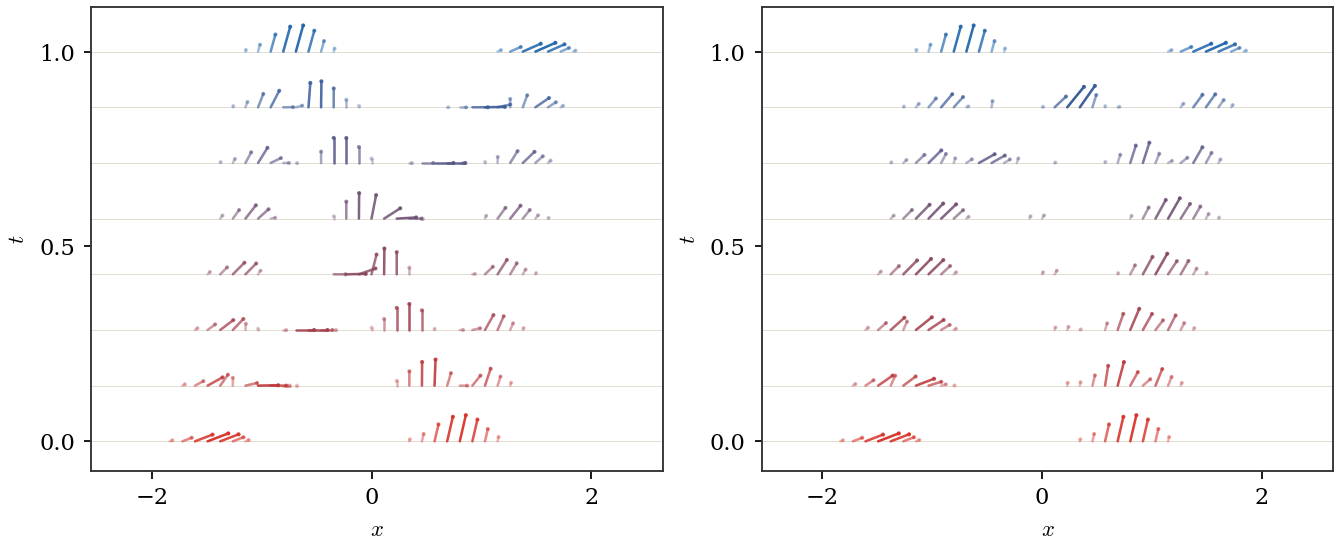
Figure Div contrasts the exact diagonal case κ=0, where each positive channel is transported by its quantile map, with a large-κ illustrative common-mode interpolation in which the channels move more coherently.
One-dimensional positive R+2-valued transport displayed by arrow
glyphs at eight time levels. Each endpoint is a mixture of two localized
Gaussian modes, and, inside each mode, both channel profiles have the same
center. Each arrow is proportional to the local fiber value
(ut1(x),ut2(x)), and time runs vertically from the red source to the
blue target. Left: for κ=0, the diagonal mobility gives two
independent scalar quantile geodesics. Right: a large-κ common-mode
interpolation bends the display toward q=2−1/2(1,1), illustrating the
effect of a mobility that favors coherent channel motion while keeping the
same componentwise continuity equation.
The interactive demo keeps the same glyph idea and lets the coupling strength bend
the fibers toward a common channel direction.
Interactive panel. Use the coupling and mixture controls to see how vector-valued mass transports both location and channel composition.
The next simplest fiber is the positive matrix cone. This is the simplest
tensor-valued model beyond vectors: the diagonal entries behave like positive
channels, while the eigenvectors encode local orientations.
Equivalently, A is a symmetric matrix of finite signed measures
such that A(E)⪰0 for every Borel set E. If A
has density A(x)⪰0, then trA(x) is
the scalar amount of mass at x, while, wherever trA(x)>0,
the normalized matrix A(x)/trA(x) records an internal
covariance or orientation. This is the matrix analogue of the positive vector
case: diagonal matrices encode nonnegative vector components, and
non-diagonal matrices add a local eigenbasis.
The conservative Benamou--Brenier model fixes a matrix density
At(x)∈S+m and symmetric matrix fluxes
Pt(x)=(Pt,1,…,Pt,d)∈(Sm)d. With no flux through the
boundary of X, the full matrix mass ∫XAt(x)dx is conserved, so
the endpoints must have the same total matrix. The model minimizes the
matrix-perspective action
Here A† denotes the Moore--Penrose inverse, with the usual
lower-semicontinuous perspective convention: the action is finite only when
the columns of each Pt,ℓ belong to the range of At. The matrix
fractional map (A,P)↦tr(P⊤A†P) is jointly
convex on this effective domain and positively one-homogeneous in (A,P).
This gives the simplest
non-trivial matrix-valued transport model: spatial motion is conservative,
but the fiber carries orientation through the eigenvectors of At(x).
Proof
The continuity equation (11) is diagonal entry by
diagonal entry and gives ∂tuk+∇⋅Vk=0. Moreover,
with the same scalar perspective convention as before. The admissible set and
the action are therefore exactly those of the diagonal vector model.
The restriction to a fixed diagonal basis gives eigenvalue transport; it
should be read as a commuting submodel, not as a claim that non-diagonal
excursions can never change the unrestricted value. The genuinely
matrix-valued case starts when the eigenspaces vary with x or along the
interpolation, so that the transported object carries both mass and
orientation. Static matrix-valued Monge--Kantorovich problems and dual
test-function metrics were developed in
Ning & Georgiou, 2014Jiang et al., 2012Ning et al., 2015; dynamic versions and
related non-commutative geometries appear in
Chen et al., 2016Chen et al., 2020Carlen & Maas, 2014Peyré et al., 2019. The figure below
shows the analogous independent/coupled contrast for positive 2×2
matrix fibers, using two localized matrix modes whose eigenvalue profiles
share a common center at each mode.
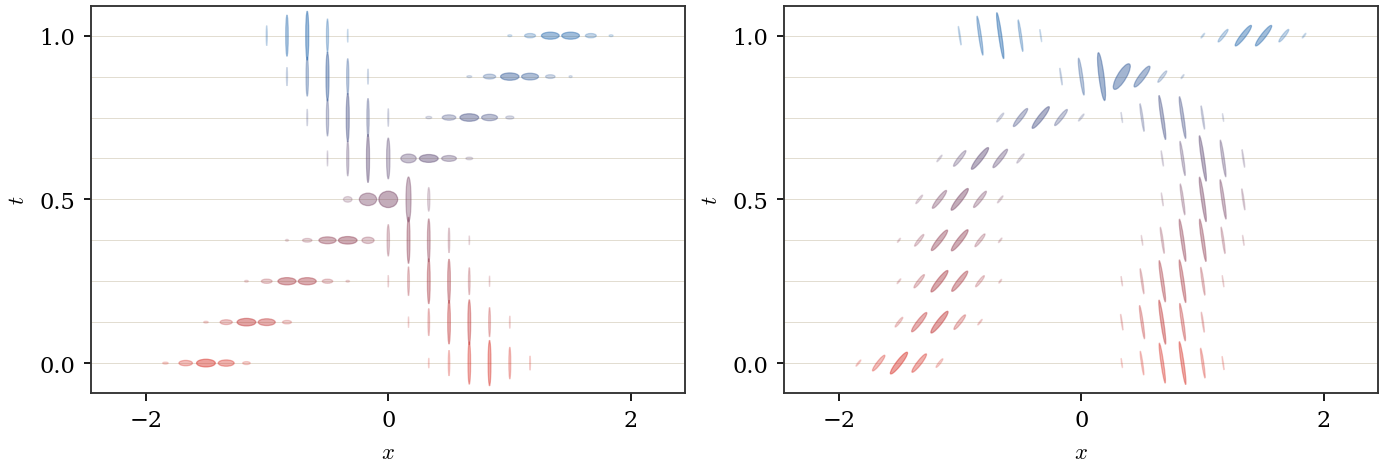
Figure Div shows the analogous independent/coupled contrast for positive 2×2 matrix fibers, using two localized matrix modes whose eigenvalue profiles share a common center at each mode.
Positive 2×2 matrix-valued transport on a one-dimensional base. Each
endpoint is a mixture of two localized matrix modes; within one mode, both
eigenvalue profiles are Gaussian bumps with the same center. Each ellipse is
the glyph of a positive semidefinite matrix At(x), with axes given by
eigenvectors and eigenvalues. Left: the matrices are diagonal in a fixed
basis, giving the commuting tensor analogue of independent vector channels.
Right: a coupled illustrative interpolation bends packet motion toward the
trace-density transport and uses non-commuting eigendirections; the
superposition remains positive semidefinite and produces spatially varying
orientations.
Interactive panel. Use the coupling and rotation controls to compare matrix-valued transport of anisotropic local structure.
The construction can be iterated. Once (X,d) is a metric space, the set of
probability measures on X becomes a metric space through Wp. It can
therefore serve as a new ground space. This is useful whenever the objects to
compare are themselves random probability measures, or mixtures whose
components are meaningful objects rather than only a collapsed density.
The standard setting is that of Polish spaces, introduced in
Definition: Polish Metric Space. These assumptions provide separability,
completeness, tightness criteria and regular conditional probabilities. The
next proposition shows that Wasserstein spaces preserve this well-behaved
structure.
Proof
From a Wp-Cauchy sequence, extract a subsequence (αk)k such
that ∑kWp(αk,αk+1)<∞. Gluing optimal couplings
of consecutive terms produces random variables (Xk)k with laws
αk and
∑k∥d(Xk,Xk+1)∥Lp<∞. Hence (Xk)k converges almost
surely and in Lp to an X-valued random variable, whose law is the
Wp limit. Separability follows by approximating measures with finitely
supported measures on a countable dense subset and rational weights. If
X is compact, Prokhorov compactness and Wasserstein metrization of weak
convergence give compactness.
Fix 1≤p<∞. Elements of Pp(Pp(X)) are probability laws
over probability measures, or random probability measures. A measurable
parametric family gives
For p=2, Gaussian mixtures provide an explicit example with two geometries.
A mixture can be viewed
as a collapsed density on X, or as a component law over Gaussian atoms in
the Bures--Wasserstein space. For two component laws
If P⋆ is an optimal coupling between the weights a and b, and if
Aij is the Brenier linear part from Σi to Λj, each active
pair follows the Gaussian geodesic
This component-level interpolation generally differs from the true W2
interpolation between the collapsed mixture densities.
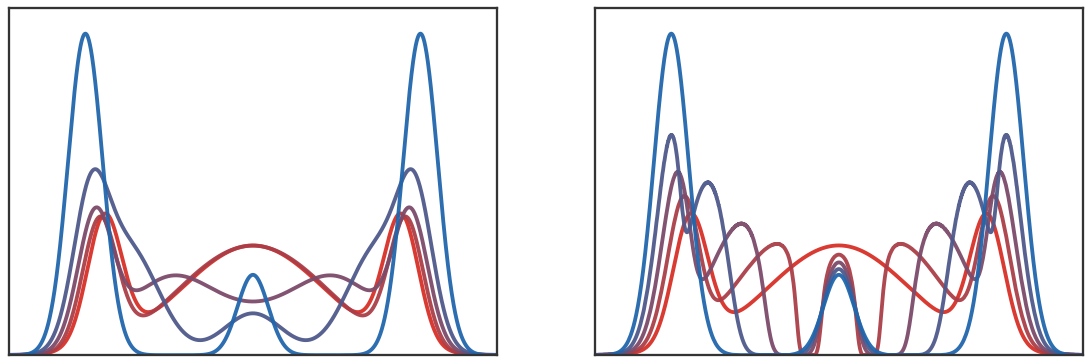
Figure Div contrasts this component-level geodesic with the true one-dimensional Wasserstein interpolation of the collapsed mixtures, making the internal mass splitting absent from the former visible.
show_book_figure("kantorovich-wow-mixtures")
Two interpolations between the same asymmetric three-component
one-dimensional Gaussian mixtures. The red endpoint has a broad central
component carrying most of the mass, while the blue endpoint has two dominant
sharp side modes. Left: Gaussian components are transported as atoms using
their Bures--Wasserstein distance. Right: the collapsed densities are
interpolated by the true one-dimensional quantile formula for W2. The
central mass is split and recombined in the collapsed geometry, making the two
paths visibly distinct.
The interactive comparison keeps both geometries side by side: component-level
transport moves Gaussian atoms, while collapsed transport rearranges the full
density.
Interactive panel. Use the mixture and blur controls to compare transport between ordinary measures with transport between distributions of measures.
Proof
Fix a coupling Π between A and B and η>0.
A measurable-selection theorem gives a measurable kernel
πα,β∈Π(α,β) whose cost is at most
Wp(α,β)p+η. Integrating this kernel against Π gives a
coupling between the collapsed mixtures. Its cost is at most the
Π-average of Wpp(α,β) plus η. Letting
η↓0, taking the infimum over Π, and then taking the
p-th root proves the claim.
This viewpoint also clarifies lower bounds for Gromov--Wasserstein distances:
a metric-measure space can be mapped to a law of local distance profiles, and
these laws can be compared by Wasserstein-over-Wasserstein.
Gromov--Wasserstein compares spaces through their internal distance
structures rather than through a fixed ambient ground cost. This is the right
extension for graphs, shapes and point clouds whose points are not
pre-aligned.
Optimal transport needs a ground cost C to compare histograms (a,b), and
thus cannot be used directly if the histograms are not defined on the same
underlying space, or if one cannot pre-register these spaces to define a
ground cost. Instead, assume that two matrices
D∈Rn×n and D′∈Rm×m represent relationships
between points. A typical scenario is when these matrices are powers of
distance matrices. Define the quadratic distortion and its minimum by
where p≥1 and Δ is usually Δ(u,v)=∣u−v∣. This is a
non-convex quadratic problem over the transport polytope. In the uniform
case with m=n and P constrained to be a permutation matrix, it becomes a
Quadratic Assignment Problem, already NP-hard in full generality
Loiola et al., 2007. The relaxed coupling formulation can therefore be
read as a soft graph-matching model Lyzinski et al., 2016.
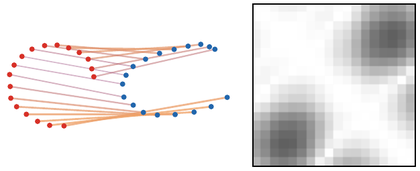
Figure Div shows this intrinsic matching principle under progressively stronger deformations: correspondences are selected from within-space distance patterns rather than an ambient cross-space cost.
show_book_figure("gromov-isometry-matching")
Gromov--Wasserstein correspondences under increasing deformation. The red
and blue point clouds are not compared through an ambient Euclidean
cross-cost; instead, the GW coupling compares their internal pairwise
distances. A perfectly isometric copy admits a clean structural match, while
mild and deliberately stronger deformations progressively bend the
correspondence.
The interactive demo uses a fixed structural correspondence and lets the deformation
change the pairwise-distance residual. This isolates the quantity minimized by
the GW objective.
Interactive panel. Use the deformation and point controls to inspect correspondences when only within-space distances are meaningful.
When D,D′ are genuine distance matrices, the construction below defines a
distance between metric spaces equipped with a probability distribution, up to
measure-preserving isometries
Mémoli, 2011Sturm, 2012Schmitzer & Schnörr, 2013. The same construction
also explains why GW satisfies the triangle inequality after quotienting by
isometries, and its relation to Hausdorff and Gromov--Hausdorff distances is
discussed at the end of the section.
The continuous formulation abstracts the discrete distance matrices into
metric-measure spaces, so that GW compares intrinsic geometries independently
of labels, parametrizations or ambient coordinates.
Compactness is often assumed below to avoid additional tightness and
integrability arguments.
For metric-measure spaces X=(X,dX,α) and
Y=(Y,dY,β), define
Taking the Lp norm and using Minkowski gives a bound by
2(∫dX(x,y)pdπ)1/p. Optimizing over π proves the claim.
Proof
Compactness makes the coupling set compact and the distortion continuous, so
an optimal coupling exists. A measure-preserving isometry induces a graph
coupling with zero distortion; symmetry and non-negativity are immediate.
If GW(X,Y)=0 and π is optimal, then
dX(x,x′)=dY(y,y′) holds π⊗π-almost everywhere. By
continuity, this equality holds on supp(π)2. Both
X and Y are isometric to the support space
(supp(π),dπ,π), where
The first projection is measure-preserving and distance-preserving on
supp(π), and compactness gives surjectivity onto
supp(α); the same argument applies to the second
projection.
For the triangle inequality, glue optimal couplings between
X,Y and between Y,Z. The projected
X×Z marginal is feasible, and the pointwise triangle inequality
together with Minkowski gives
This proves the triangle inequality and completes the metric proof.
Proof
Apply the GW triangle inequality in both directions. Each error term compares
the same underlying metric space equipped with two different measures, so
Proposition: Fixed-Space GW Is Controlled by Wasserstein bounds it by twice the corresponding
ordinary Wasserstein distance. Taking expectations yields the empirical
bound; the rates are therefore those developed in
Sample Complexity.
The metric structure also gives geodesics. Sturm’s construction allows one to
speak about interpolation, barycenters and gradient flows directly on the
space of metric-measure spaces, even though the intermediate space lives on a
product support and is therefore expensive numerically Sturm, 2012.
Proof
For s<t, couple Xs and Xt by the diagonal coupling on
Z. The distance difference is exactly
so GW(Xs,Xt)≤(t−s)D, where
D=GW(X0,X1). Applying the triangle
inequality to
X0,Xs,Xt,X1 gives the reverse bound.
Figure Div complements the global GW objective with local diagnostics, displaying where a mildly non-isometric correspondence creates the largest pairwise-distance residuals.
Local distortion in a mildly non-isometric GW match. The left panel colors
transport segments by the average residual induced by the displayed hard
correspondence. The right panel shows the pairwise-distance residual matrix
∣dX(xi,xi′)−dY(yσ(i),yσ(i′))∣, with darker entries
marking larger local distortion. This matrix is the local contribution
minimized by the discrete GW objective for the displayed correspondence.
Interactive panel. Use the deformation and shift controls to see where a Gromov-Wasserstein correspondence preserves or distorts pairwise distances.
Proof
Fix any π∈Π(α,β). It induces a coupling
(x,y)↦(αx,βy) between the profile laws, hence
For fixed (x,y), the map
(x′,y′)↦(dX(x,x′),dY(y,y′)) pushes the same coupling π to a
coupling between αx and βy. Integrating the resulting
one-dimensional OT bound over (x,y) gives the GW objective for π.
Taking the infimum over π proves the claim.
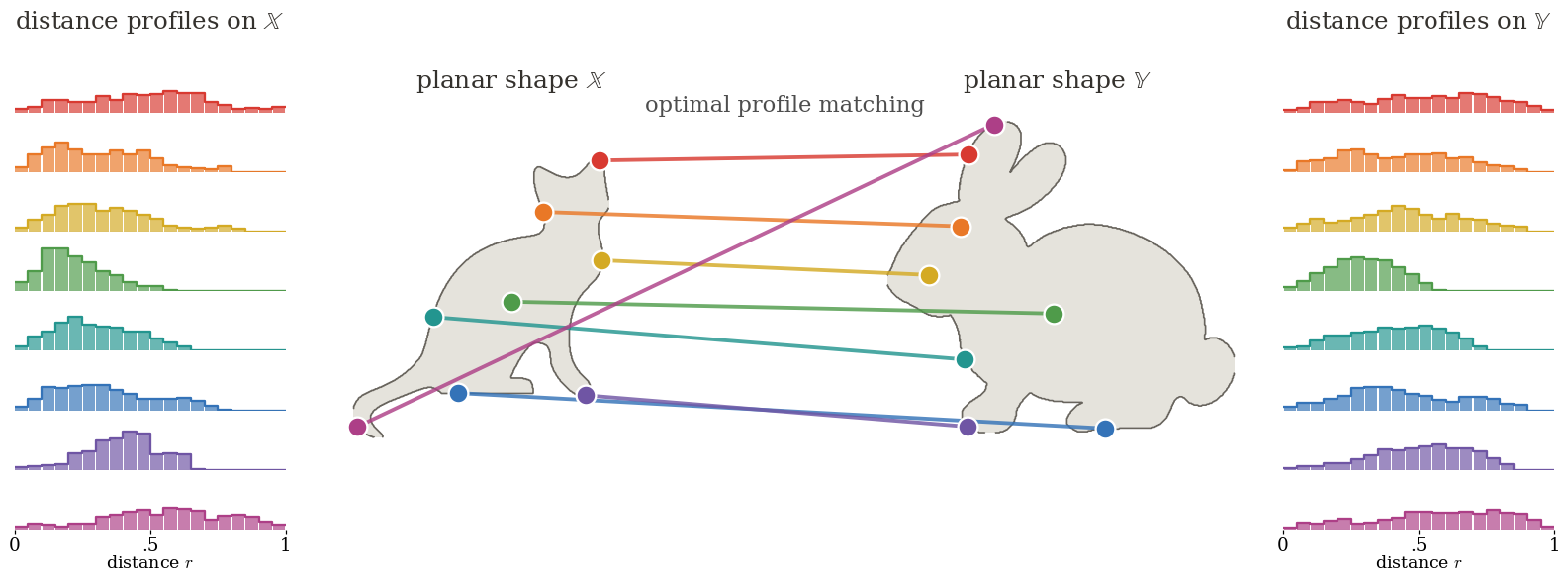
The next figure exposes the two nested transport problems for the planar shapes
X and Y: sorting each distance profile computes the
one-dimensional costs, then an outer assignment couples the resulting profile
laws.
Figure Div makes the two transport levels explicit for the planar shapes X and Y: sorting each distance profile computes the one-dimensional costs, then an outer assignment couples the resulting profile laws.
# Exact sorted profiles; the histograms are display summaries only.
show_book_figure("gromov-memoli-distance-profiles")
Mémoli distance profiles expose a computable lower bound for intrinsic GW
comparison. The planar shapes X and Y are represented by
cat and bunny silhouettes, centered and normalized to unit diameter. Matching
colors identify representative anchor pairs selected by the optimal profile
assignment with Cij=W22(αxi,βyj), their connecting
segments and their two side histograms. The histograms are display summaries
only: every profile cost is computed by sorting the complete distance profiles.
The resulting outer assignment realizes the Mémoli profile lower bound.
This lower bound is useful computationally because the profile cost matrix
Cij=Wp(αxi,βyj)p is an ordinary OT cost between
points. Solving this easier OT problem gives a geometry-aware initialization
for the non-convex GW iterations.
The profile lower bound is intrinsic. In Euclidean applications, it is naturally
paired with an extrinsic upper certificate obtained by registering the two
measures before applying the ordinary Wasserstein distance.
Proposition Proposition: Wasserstein-Procrustes Upper Certificate, proved in
Quotient Wasserstein and Wasserstein-Procrustes, supplies exactly this certificate.
The converse need not hold, because a small GW value may be achieved by an
intrinsic correspondence that is not induced by any ambient rigid motion.
Combining the profile lower bound with the Procrustes upper certificate gives
the sandwich
The factor ϵ/2 is essential because C(P) is one half of
the quadratic gradient. Each update is an ordinary entropic OT problem and
can therefore be solved with Sinkhorn iterations. If the iterates converge to
a positive fixed point, it satisfies the stationarity conditions of the
regularized GW objective. The basic fixed-point iteration is not a descent
method in general and has no global guarantee for this non-convex problem;
line searches or proximal variants are needed when monotone decrease is
required.
Fused Gromov--Wasserstein augments the structural term with a feature
transport cost Vayer et al., 2019. In the discrete
case, given a cross-feature cost M∈Rn×m and a parameter
λ∈[0,1], one minimizes
The endpoints λ=0 and λ=1 recover feature-only OT and pure GW
respectively; intermediate values trade attribute matching against structural
matching. The first term compares node attributes in the usual OT sense, and
the second compares intrinsic geometry; this is useful when two spaces have
both distances and features, and the two sources of information may disagree.
Figure Div isolates this tradeoff on a small graph pair by comparing feature-only, structure-only and fused correspondences.
show_book_figure("fused-gromov-feature-geometry")
Feature information and intrinsic geometry in fused Gromov--Wasserstein.
Small inner disks encode binary node features. Feature-only OT follows the
attributes even when this crosses the shape structure, pure GW follows the
intrinsic ordering, and fused GW balances the feature term with the
pairwise-distance distortion.
Interactive panel. Use the geometry-weight and feature-conflict controls to balance structural matching against feature agreement.
Equivalently, it is half the minimal distortion of a correspondence between
X and YGromov, 2001Mémoli, 2007. This is a worst-case set
distance: every point must be matched with small distortion.
Gromov--Wasserstein replaces correspondences by probability couplings and
worst-case distortion by averaged distortion. It is therefore better adapted
to noisy sampled shapes and weighted graphs, but it can ignore small sets of
mass that would dominate the Hausdorff distance.
Quantum optimal transport replaces probability vectors by density matrices
and scalar couplings by positive operators on a tensor product space. This is
the right language when the transported objects are matrix-valued signals,
covariance-like descriptors or quantum states, and it exposes a precise
bridge between OT, non-commutative entropy and operator scaling
Ning & Georgiou, 2014Chen et al., 2016Chen et al., 2020Peyré et al., 2019Caglioti et al., 2020Chakrabarti et al., 2019.
Minimizing over T⪰0 gives a finite lower bound if and only if
C−F⊗Im−In⊗G⪰0, in which case the infimum in T is
0. When A,B≻0, the coupling A⊗B is strictly feasible, so
Slater’s theorem gives equality of primal and dual values and dual attainment.
For singular marginals, let PA,PB be their support projections. Positivity
and
imply
T=(PA⊗PB)T(PA⊗PB). Thus the primal is exactly the
problem compressed to supp(A)⊗supp(B),
where both reduced marginals are positive definite and Slater applies. The
unreduced dual values approach this reduced maximum by choosing sufficiently
negative potentials on the orthogonal complements.
The dual potentials have the usual scalar gauge freedom: replacing
(F,G) by (F+tIn,G−tIm) leaves both the constraint and the value
unchanged because tr(A)=tr(B)=1.
This is the non-commutative analogue of entropic OT: the Shannon entropy of a
coupling is replaced by the trace entropy of a density matrix
Peyré et al., 2019Chakrabarti et al., 2019.
Proof
The feasible set is compact and nonempty, and it contains the positive
definite point A⊗B. The trace entropy is strictly convex on positive
semidefinite matrices, hence the regularized primal has a unique minimizer.
The minimizer is positive definite: otherwise, moving toward the positive
feasible point A⊗B would have entropy directional derivative
−∞ at the boundary while changing the linear cost at finite rate.
Slater’s condition justifies the Lagrange dual computation. The Fenchel
identity
is the matrix analogue of the scalar exponential conjugacy. Applying it to
the Lagrangian with
Y=F⊗Im+In⊗G−C gives (62), and the
stationarity condition gives (63); differentiating the
dual objective with respect to F and G yields the two marginal equations.
Writing K=exp(−C/ϵ), the objective differs by a constant from
ϵ times the quantum KL divergence
For the projection of a positive definite matrix S onto MA, the
affine set contains the positive definite point A⊗Im/m. The entropy
derivative is singular at the boundary, so the projection lies in the
interior of the positive cone and the first variation has the form
for a Hermitian multiplier Λ. Hence
T=exp(logS+Λ⊗Im). If S=Te(F,G), this is again
Te(F+ϵΛ,G); the multiplier is fixed by the marginal equation.
The same argument applies to MB. Finally, the first-order
optimality condition for maximizing (62) over one block
is exactly the corresponding marginal equation, so the Bregman and block-dual
views coincide.
In the diagonal case this proposition gives the usual multiplicative Sinkhorn
updates. In the non-commutative case, however, the exact block equations
The algorithm often called quantum Sinkhorn comes from the operator-scaling
literature of Gurvits and subsequent developments
Gurvits, 2003Gurvits, 2004Georgiou & Pavon, 2015Garg & Oliveira, 2018.
It replaces the true Gibbs coupling (63) by the
symmetric factorization
where U=exp(F/(2ϵ)), V=exp(G/(2ϵ)) and
K=exp(−C/ϵ). If [Z,C]=0, then Ts(F,G)=Te(F,G); otherwise this
is a Strang-type symmetric surrogate.
Fix a Choi convention and let K:Hm→Hn be the
completely positive map represented by the positive Choi matrix K; let
K⋆ be its Hilbert--Schmidt adjoint. Up to the transpose
dictated by the chosen Choi convention, the marginal equations for the
symmetric coupling take the operator-scaling form
These inverse square roots are well-defined when K≻0 and
U,V,A,B≻0. Under the standard strict-positivity and scalability
hypotheses, the alternating normalizations converge to the prescribed
marginals Georgiou & Pavon, 2015Garg & Oliveira, 2018. At finite tolerance
they return an approximate coupling. When all matrices are diagonal, the
updates reduce to classical Sinkhorn scaling; when the targets are
proportional to identities, they match the usual bistochastic
operator-scaling normalization up to trace convention.
Dynamic time warping (DTW) compares ordered feature sequences when the same
phenomenon may be observed under different clocks. It is historically rooted
in speech recognition Vintsyuk, 1968Sakoe & Chiba, 1978, and is now
a standard tool for time-series alignment, retrieval and classification
Berndt & Clifford, 1994Müller, 2007. Like OT, it minimizes an
aggregate feature mismatch over correspondences; unlike OT, those
correspondences must respect chronology.
For two empirical measures, Kantorovich OT minimizes a linear cost over the
convex polytope of nonnegative matrices with prescribed row and column sums.
DTW instead minimizes over the finite, non-convex set of connected monotone
paths through the pairwise cost matrix. Every time index must be visited, but
it may be visited repeatedly; the row and column sums therefore record
endogenous visit counts rather than prescribed masses. Normalizing a path
matrix produces a coupling only for these path-dependent marginals, not for
fixed input histograms. Conversely, ordinary OT between the unordered
empirical feature measures forgets chronology and may match indices in a
crossing order. Temporal penalties, causal constraints, and joint OT--DTW
models interpolate between the two viewpoints; spatio-temporal alignment, for
example, combines regularized OT for spatial comparison with soft-DTW for
chronological alignment Janati et al., 2020. Here “dynamic”
refers to Bellman’s dynamic programming on the index grid, not to the transport
PDEs of Paragraph.
Let x=(xi)i=1n and y=(yj)j=1m be two sequences in a feature
space Z, and set Cij=c(xi,yj) for a nonnegative cost
c:Z×Z→R+. A warping path is a sequence
Denote the set of such paths by Ωn,m and the corresponding incidence
matrix by (Aω)ij=1{(i,j)∈ω}. Its length satisfies
max{n,m}≤L≤n+m−1, its total mass is
∑ij(Aω)ij=L, and its two marginals are precisely the row and
column visit counts.
The definition is symmetric when c is symmetric, but it is generally not a
metric: repetitions can give zero cost to distinct sequences, and the triangle
inequality can fail. Step weights, slope constraints and a Sakoe-Chiba band
are common variants that penalize excessive repetition or restrict the
admissible temporal distortion
Sakoe & Chiba, 1978Müller, 2007.
The monotone path structure converts the exponentially large variational
problem (76) into a shortest-path computation on an acyclic
grid.
Proof
Every admissible path reaching (i,j) enters it from exactly one of
(i−1,j), (i,j−1) or (i−1,j−1). Removing the last cell therefore leaves
an admissible path to one of these predecessors, while appending (i,j) to
any predecessor path gives an admissible path to (i,j). Minimizing over the
three mutually exhaustive last steps proves (77) by
induction on i+j. Each of the nm cells performs constant work.
Discrete DTW depends on the sampling density because every visited cell
contributes once. A direct continuous registration minimizes
∫01c(x(t),y(γ(t)))dt over nondecreasing endpoint-fixing maps
γ, but this one-clock formulation is asymmetric and privileges the
parameterization of x. Continuous DTW instead traverses both clocks and
measures mismatch per unit length in the parameter square
Buchin et al., 2022.
For simplicity, let x,y:[0,1]→Z use normalized clocks, and let
Γ↑ contain pairs (ϕ,ψ) of absolutely continuous,
nondecreasing surjections of [0,1] onto itself. Equivalently, the endpoint
conditions are ϕ(0)=ψ(0)=0 and ϕ(1)=ψ(1)=1. The continuous DTW
functional is
Because ϕ˙,ψ˙≥0 almost everywhere, the last factor is the
ℓ1 line element of the monotone path
s↦(ϕ(s),ψ(s)). Formula (78) is invariant under
increasing reparameterizations of the auxiliary variable s and does not
privilege either clock; when c is symmetric, the resulting functional is also
symmetric in x and y. After parameterization by ℓ1 arc length, it is
simply the line integral of the feature mismatch along a monotone path. For
physical clock intervals [0,p] and [0,q], the same formula uses
ϕ:[0,1]→[0,p] and ψ:[0,1]→[0,q]. Exact computation is
substantially harder than the discrete recurrence: for arc-length-parametrized
one-dimensional polygonal curves and the standard cost c(u,v)=∣u−v∣, Buchin,
Nusser and Wong propagate piecewise-quadratic boundary costs in
O((n+m)5) time Buchin et al., 2022. This complexity statement
does not apply to an arbitrary feature cost c.
To make the regularization explicit, let Δ(Ωn,m) be the simplex
of probability laws q=(qω)ω over paths and let
H(q)=−∑ωqωlogqω be their Shannon entropy, with
0log0=0. The Gibbs variational identity gives
because the partition sum is bounded below by its largest term and above by
∣Ωn,m∣ times that term. Hence
sDTWc,ϵ→DTWc as ϵ→0.
Forward and backward dynamic programs compute its value and gradient in
O(nm) time and O(nm) memory Cuturi & Blondel, 2017.
Differentiating the finite log-partition function gives
Thus (Eϵ)ij is the probability that a Gibbs path visits cell
(i,j). The matrix Eϵ is a diffuse expected alignment and converges,
when the hard optimum is unique, to its path-incidence matrix.
The analogy with entropic OT is now exact at the level of free energies, but not
at the level of feasible variables. Sinkhorn regularizes a coupling with
prescribed marginals, whereas soft-DTW regularizes the path law q in
(82). Its mean Eϵ generally has neither
prescribed row sums nor prescribed column sums, and the path entropy H(q)
cannot in general be recovered from Eϵ alone. Algorithmically,
Sinkhorn uses alternating matrix scaling, while soft-DTW uses forward--backward
dynamic programming on an acyclic grid. Global-alignment kernels sum the same
Gibbs weights over all paths
Cuturi et al., 2007Cuturi, 2011.
Raw soft-DTW also has an entropic self-bias and can be negative. In direct
analogy with the Sinkhorn divergence of Sinkhorn Divergences, define
The correction always vanishes on the diagonal, but positivity requires care.
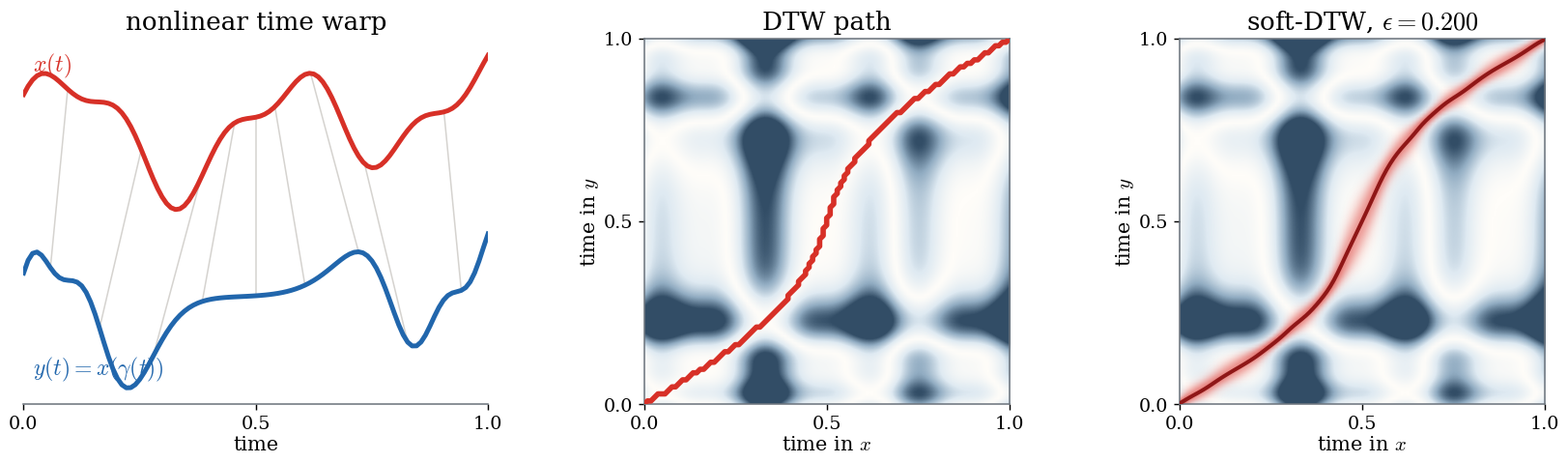
# Hard DTW path and soft-DTW Gibbs occupancy at epsilon = .200.
show_book_figure("dynamic-time-warping")
Hard and soft monotone alignments recover a nonlinear time warp. Left: an
oscillatory signal x and the warped observation y(t)=x(γ(t)) for a
smooth increasing map γ; thin gray segments mark exact corresponding
times. Middle: the pairwise squared feature-cost matrix
Cij=∣xi−yj∣2, with the optimal DTW path shown in red. Right: the same
matrix overlaid with the soft-DTW expected alignment Eϵ from
(85) at ϵ=.200; red intensity gives
cell-visit probability and the dark red curve is its row-wise barycentric
summary.
Maas, J., Rumpf, M., Schönlieb, C., & Simon, S. (2015). A generalized model for optimal transport of images including dissipation and density modulation. ESAIM: Mathematical Modelling and Numerical Analysis, 49(6), 1745–1769.
Maas, J., Rumpf, M., & Simon, S. (2016). Generalized optimal transport with singular sources. arXiv Preprint arXiv:1607.01186.
Dolbeault, J., Nazaret, B., & Savaré, G. (2009). A new class of transport distances between measures. Calculus of Variations and Partial Differential Equations, 34(2), 193–231.
Mielke, A. (2013). Geodesic convexity of the relative entropy in reversible Markov chains. Calculus of Variations and Partial Differential Equations, 48(1–2), 1–31.
Ning, L., & Georgiou, T. T. (2014). Metrics for matrix-valued measures via test functions. 53rd IEEE Conference on Decision and Control, 2642–2647.
Jiang, X., Ning, L., & Georgiou, T. T. (2012). Distances and Riemannian metrics for multivariate spectral densities. IEEE Transactions on Automatic Control, 57(7), 1723–1735.
Ning, L., Georgiou, T. T., & Tannenbaum, A. (2015). On matrix-valued Monge–Kantorovich optimal mass transport. IEEE Transactions on Automatic Control, 60(2), 373–382. 10.1109/TAC.2014.2350171
Chen, Y., Georgiou, T. T., & Tannenbaum, A. (2016). Matrix optimal mass transport: a quantum mechanical approach. arXiv Preprint arXiv:1610.03041.
Chen, Y., Gangbo, W., Georgiou, T. T., & Tannenbaum, A. (2020). On the matrix Monge-Kantorovich problem. European Journal of Applied Mathematics, 31(4), 574–600. 10.1017/S0956792519000172
Carlen, E. A., & Maas, J. (2014). An analog of the 2-Wasserstein metric in non-commutative probability under which the fermionic Fokker–Planck equation is gradient flow for the entropy. Communications in Mathematical Physics, 331(3), 887–926.
Peyré, G., Chizat, L., Vialard, F.-X., & Solomon, J. (2019). Quantum entropic regularization of matrix-valued optimal transport. European Journal of Applied Mathematics, 30(6), 1079–1102. 10.1017/S0956792517000274
Loiola, E. M., de Abreu, N. M. M., Boaventura-Netto, P. O., Hahn, P., & Querido, T. (2007). A survey for the quadratic assignment problem. European Journal of Operational Research, 176(2), 657–690. 10.1016/j.ejor.2005.09.032
Lyzinski, V., Fishkind, D. E., Fiori, M., Vogelstein, J. T., Priebe, C. E., & Sapiro, G. (2016). Graph matching: relax at your own risk. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(1), 60–73.
Mémoli, F. (2011). Gromov–Wasserstein distances and the metric approach to object matching. Foundations of Computational Mathematics, 11(4), 417–487.
Sturm, K.-T. (2012). The space of spaces: curvature bounds and gradient flows on the space of metric measure spaces (Preprint 1208.0434). arXiv.