The preceding gradient-flow calculus is variational. Modern machine-learning
models often use the same transportation language more broadly: one may
prescribe an interpolation and regress its velocity, fit a one-step generator
to a descent field, or view network depth as a continuous transport of token
measures. The examples below separate what is genuinely a Wasserstein gradient
flow from what is a transportation dynamics with a useful geometric
interpretation.
from pathlib import Path
import sys
from IPython.display import Image as DisplayImage
from IPython.display import display
here = Path.cwd()
myst_dir = None
for candidate in [here, here.parent, here / "myst", here.parent / "myst", here.parent.parent / "myst"]:
if (candidate / "ot4ml_web.py").exists():
myst_dir = candidate.resolve()
sys.path.insert(0, str(myst_dir))
break
if myst_dir is None:
raise RuntimeError("Could not locate myst/ot4ml_web.py")
repo_root = myst_dir.parent
thumbnails = repo_root / "notebooks-figures" / "thumbnails"
def show_book_figure(name, width=760):
display(DisplayImage(filename=str(thumbnails / f"{name}.png"), width=width))
Flow matching constructs a generative map by learning the velocity field of an interpolation. The key computational insight is that a constrained continuity-equation problem can be trained by an unconstrained regression.
Generative models aim to build a transportation map T between a reference distribution α (typically an isotropic Gaussian) and the target data distribution β. Since such reference measures are non-atomic, a measurable map with T♯α=β exists on standard Borel spaces, for instance by identifying both probability spaces with the unit interval and using a quantile-type rearrangement. This abstract existence statement is much weaker than having an explicit and numerically stable construction of T. Optimal transport is one approach to achieving this, but it is computationally expensive and raises questions about how to estimate it from samples. A different route is to prescribe an interpolation between noise and data, learn its velocity, and obtain T by integrating a time-dependent vector field vt. This point of view sits at the meeting point of two literatures, surveyed from a transport perspective in Peyré, 2025. The diffusion branch builds on score matching Hyvärinen, 2005, denoising score matching Vincent, 2011, nonequilibrium noising chains Sohl-Dickstein et al., 2015, denoising diffusion probabilistic models Ho et al., 2020, score-based generative modeling Song & Ermon, 2019, and the continuous-time score-SDE/probability-flow formulation Song et al., 2021. The deterministic regression branch was introduced, essentially in parallel, under three closely related names: flow matching Lipman et al., 2023, rectified flow Liu et al., 2023, and stochastic interpolants Albergo et al., 2025. In all three cases, the computational object is a velocity field whose regression loss avoids simulating the learned ODE during training. This vector field vt is obtained by constructing an interpolation αt and then finding vt using the least-squares formula of the dynamic chapter. As we will explain, for a specific class of interpolation (obtained by a parametric push-forward), this vt can be obtained by avoiding explicitly inverting a Laplacian and instead computing a simple conditional expectation. This conditional expectation can itself be estimated by solving another least-squares problem, but this time unconstrained, making the estimation feasible from finite samples of α and β.
The word “stochastic” can hide two different levels of randomness. We first use the simpler one: after drawing a latent variable U∼π, the path t↦Pt(U) is deterministic and differentiable. The randomness only comes from the initial draw of U; after taking the push-forward law, αt=(Pt)♯π is a deterministic curve of measures and obeys an ordinary continuity equation. This is the setting behind the stochastic-interpolant construction recalled in Remark Remark: Static-noise stochastic interpolants, and behind the flow-matching and rectified-flow regressions below. Genuine temporal noise, where the path itself has Brownian fluctuations, is different and is discussed in Remark Remark: Brownian realizations of interpolant marginals.
We assume first that αt is obtained by pushing a latent distribution π∈P(Rd′) through a time-dependent map Pt:Rd′→Rd; the latent dimension d′ may be larger than the data dimension d:
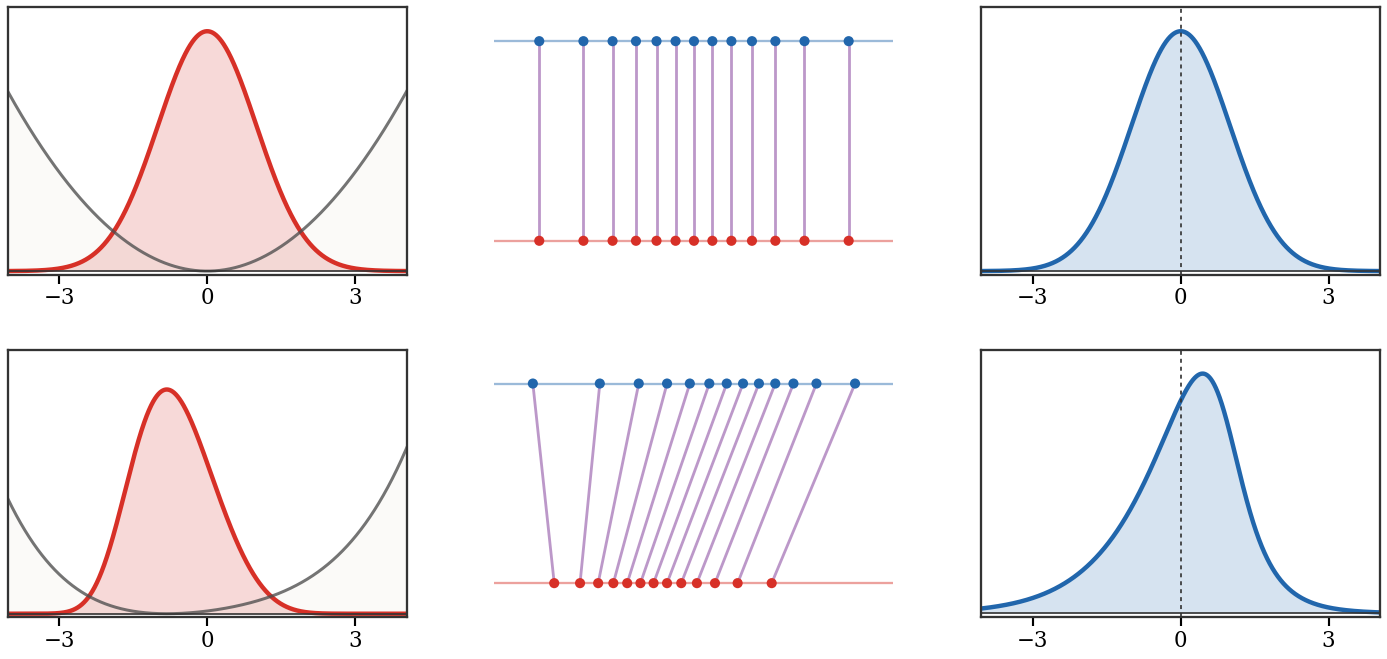
Flow matching interpolants between the same empirical source and target measures. A product-style random pairing produces crossing paths, an OT pairing gives direct displacement rays, and a curved bridge changes the path geometry while keeping the same endpoints. Gray arrows mark representative midpoint velocities ∂tPt.
Interactive panel. Use the interpolation and noise controls to compare flow-matching paths between source noise and target structure.
This interpolation is not directly useful for sampling from β, but it can be used to define a flow field vt so that the continuity equation, in Eulerian form, holds. This flow field is computed by solving an unconstrained least-squares problem, or equivalently, it is a conditional expectation.
Proof
We first recall the two equivalent ways of writing the interpolated measure. Formally, one may write
The minimizer in (4) is the orthogonal projection in L2(π;Rd) of the latent velocity ∂tPt(u) onto the closed subspace of functions that depend on u only through Pt(u). This projection is the conditional expectation (5). Formally, this can be read as
for every bounded continuous vector field ψ. Since αt(A)=0 implies π(Pt−1(A))=0, one has ωt≪αt. The Radon--Nikodym decomposition of ωt with respect to αt is therefore
In the language of Lebesgue decomposition, ωt has only an absolutely continuous part with respect to αt and no singular part; the conditional expectation is precisely its density. This agrees with the flux notation used in the dynamic formulation. Equivalently, disintegrating π with respect to the map Pt gives π(du)=πt,z(du)αt(dz), where πt,z is supported on the fiber {u:Pt(u)=z}, and
Thus the solution of (4) is the conditional expectation of the velocities ∂tPt: intuitively, vt(z) is the average velocity of all trajectories passing through z. Numerically, (x,t)→vt(x) can be parameterized by a neural network (e.g., a U-Net for vision tasks) and estimated using stochastic gradient descent on the objective in (4). For the exact field vt, integrating the ODE x˙=vt(x) defines a transport map Tt. If vt is regular enough, or more generally if the continuity equation has a unique solution for this velocity, then (Tt)♯α0=αt. Thus the same interpolation as (1) is represented by a deterministic flow rather than by the original coupling. The sampling procedure consists in first drawing X0∼α, and then integrating the ODE X˙t=vt(Xt) starting with Xt=0=X0. In the ideal exact-field limit, the resulting Xt=1 is distributed according to α1=β.
In the special case where Pt(x,y)=(1−t)x+ty is a linear interpolation and π=α⊗β, the curve αt is a convolution of rescaled versions of α0 and α1. The flow-matching problem (4) becomes
When one endpoint is an isotropic Gaussian, this construction is closely related to the probability-flow formulation of diffusion models, up to the usual change of time parametrization Song et al., 2021. This is why flow matching can be viewed both as a deterministic alternative to diffusion training and as a common language for diffusion paths, OT-inspired paths, and rectified paths Lipman et al., 2023Liu et al., 2023Albergo et al., 2025. The next two propositions are written in the noising direction, from a data law α to a Gaussian; reversing time gives the corresponding sampling flow. They also give an explicit closed form for vt and show that it is a gradient field. In this setting, vt is also the solution of the constrained least-squares problem from the dynamic chapter. The regression (4) is computationally simpler because the continuity equation has already been enforced by the chosen interpolant. To prove this, we rely on Tweedie’s formula Efron, 2011, which expresses the optimal Gaussian denoiser through the score, i.e. the gradient of the log-density.
Proof
Let φσ be the N(0,σ2Id) density. Bayes’ rule gives
Fix t∈(0,1) and write W=(1−t)X, σ=t, so that
Zt=W+σY matches the setting of Proposition Proposition: Tweedie identity.
Conditional expectations satisfy
v⋆(z,t)=E[Y−X∣Zt=z]=t1E[Zt−W∣Zt=z]−1−t1E[W∣Zt=z].
Applying Proposition Proposition: Tweedie identity to E[W∣Zt=z] and
noting E[Y∣Zt=z]=−t∇logρt(z)
gives the claimed formula.
Figure Div shows both directions of this construction: the prescribed interpolation noising the data and the same probability-flow ODE integrated backward for sampling.
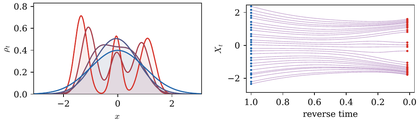
One-dimensional diffusion bridge for a Gaussian-mixture data law. The forward path Zt=(1−t)X+tY smooths the red data density toward a blue Gaussian endpoint. Reversing the probability-flow ODE transports a denser set of blue noise samples back toward the data modes, making the splitting of trajectories across mixture components visible.
Interactive panel. Use the noising time and schedule controls to see the one-dimensional forward and reverse diffusion bridge.
The same probability-flow intuition is visible in two dimensions. For a discrete data law, or more generally for a Gaussian mixture, the noising density is a Gaussian mixture whose score can be evaluated explicitly. This makes it possible to draw backward trajectories without training a neural network. In the plots below, the Gaussian endpoint has covariance σ2Id to keep the geometry visible at the scale of the three atoms. For a scalar noising schedule Zt=atX+btY, the intermediate law has component centers atcj and covariance (btσ)2Id. For the linear bridge, pt(z)=∑jwjN((1−t)cj,(tσ)2Id), with st=∇logpt, and the scaled Gaussian-endpoint field gives vt(z)=−(z+tσ2st(z))/(1−t).
In Figure Div, the Gaussian endpoint has covariance σ2Id to keep the geometry visible at the scale of the three atoms.
Two-dimensional noising paths from three Dirac masses to a single Gaussian. The linear interpolation Zt=(1−t)X+tY moves component centers linearly toward the origin and grows covariance like (tσ)2Id. The variance-preserving Ornstein--Uhlenbeck bridge has the same endpoints but a different speed of contraction and noising.
Interactive panel. Use the schedule and time controls to watch two-dimensional samples blur forward and concentrate backward.
Integrating the learned velocity gives a deterministic map from α0 to α1, but this map is not automatically the Brenier optimal map. It is optimal only in special cases where the accumulated flow remains the gradient of a convex potential. The Gaussian product-coupling case already shows the precise obstruction: the interpolated covariances are simple, the velocity is affine, but the terminal map can contain a hidden rotational part. This phenomenon, and its extensions to rectified flows and mixtures, is analyzed in depth in Hertrich et al., 2025.
which is exactly the equation T˙t=AtTt with T0=Id. Returning to the original coordinates gives (40), and t=1 gives (41).
Both T1FM and TOT push N(0,Σ0) to N(0,Σ1). The Brenier map between nondegenerate Gaussians is the unique symmetric positive definite linear map with this property. Hence T1FM=TOT if and only if T1FM is symmetric positive definite. The map T1FM is similar to C1/2, so if it is symmetric then it is automatically positive definite. It remains to characterize symmetry. Since C1/2 is symmetric positive definite,
Thus symmetry of T1FM is equivalent to
Σ0C1/2=C1/2Σ0, hence to Σ0C=CΣ0 by functional calculus. Multiplying this identity on the left and right by Σ01/2 gives Σ0Σ1=Σ1Σ0. Conversely, if Σ0 and Σ1 commute, they are orthogonally co-diagonalizable, and both (41) and (42) reduce in that basis to the diagonal map with entries λ1,k/λ0,k. This proves the equivalence.
The Gaussian optimality proposition explains why the statement “flow matching gives an optimal map” is fragile. The same terminal map (41) is obtained for any scalar schedule Zt=atX0+btX1 with the same endpoints, because after whitening the covariance path remains at2Id+bt2C. Thus changing the speed of a scalar Gaussian bridge, for instance by using an OU schedule, cannot repair the non-optimality created by non-commuting covariances. Commuting covariances reduce the terminal map to independent one-dimensional scalings, whereas non-commuting covariances create a non-symmetric affine map, hence a transport with a rotational or shearing component. More generally, mixture-like paths can create the same obstruction even when every instantaneous velocity looks natural. This distinction is closely related to counterexamples showing that flow maps associated with Fokker--Planck or diffusion-type evolutions do not in general provide optimal transport maps Lavenant & Santambrogio, 2022. In particular, starting from an isotropic Gaussian does not by itself guarantee optimality once the target distribution is non-Gaussian; additional structural assumptions on the path or on the coupling are needed.
The geometry of the generated trajectories depends on the chosen interpolant, not only on the two endpoint laws. There is first a harmless ambiguity: a monotone reparametrization Zt=(1−λ(t))X+λ(t)Y of the linear bridge only changes the speed of the flow,
then both the mixture centers and the component variances are changed. Writing pt for the density of Zt and st=∇logpt, Tweedie’s formula gives, away from times where at=0,
For the linear bridge, at=1−t and bt=t, this recovers the formula above. For the variance-preserving Ornstein--Uhlenbeck noising used in diffusion models,
one obtains the forward probability-flow velocity vτ(z)=−z−σ2∇logpτ(z). Sampling follows the reverse field z+σ2∇logpτ(z) as τ decreases. This is the noising law used in the diffusion trajectory panel below; the trajectories are more curved than for the linear bridge because the centers and variances evolve according to the OU/Fokker--Planck scaling rather than by affine interpolation. Numerically, the integration is stopped at a small positive time before the Dirac endpoint, where the score becomes singular.
The finite-time coefficients at=cos(πt/2) and bt=sin(πt/2) are not a new spatial interpolant: they are exactly the OU coefficients after the time change τ=−logcos(πt/2). The schedule comparison below therefore places the OU bridge next to a genuinely different scalar bridge,
whose data coefficient changes sign before vanishing. This overshooting bridge is mainly a diagnostic example: it keeps the same endpoints, but its intermediate mixture reflects through the origin and produces visibly different reverse trajectories.
This is the noising law used in the left panel of Figure Div; the trajectories are more curved than for the linear bridge because the centers and variances evolve according to the OU/Fokker--Planck scaling rather than by affine interpolation.
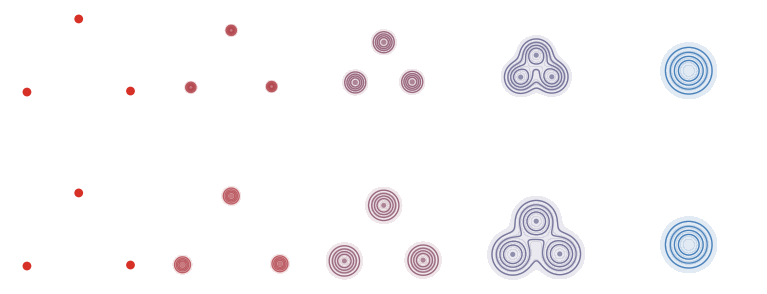
Diffusion-style sampling trajectories compared with OT rays in the three-Dirac setting. Red particles are sampled from the centered Gaussian endpoint and transported toward the three blue atoms. The diffusion panel integrates a reverse probability-flow field based on a Gaussian-mixture score, while the OT panel uses straight displacement rays selected by a quadratic matching.
Interactive panel. Use the trajectory and schedule controls to compare curved diffusion sampling paths with straight optimal-transport rays.
Figure Div therefore compares OU with a genuinely different scalar bridge,
Effect of the interpolant on the exact reverse flow for the same three-Dirac target and the same Gaussian endpoint. The linear bridge at=1−t, bt=t produces almost radial curves. The variance-preserving OU bridge aτ=e−τ, bτ=1−e−2τ changes the relative speed of contraction and noising. The overshooting bridge at=(1−t)(1−2t), bt=t is not a time reparameterization of either one and produces a more pronounced bending of the reverse trajectories.
Interactive panel. Use the schedule controls to compare how different noising laws allocate motion over time.
One-step generative models try to keep the geometric training principle of flows while removing the expensive multi-step integration at sampling time. The idea is to evolve the model distribution during training, but to store the final evolution in a single generator evaluation.
One-Step Models via Parameter-Domain Discrepancy Flows¶
The most direct one-step strategy is to train the generator parameters
themselves by descending a discrepancy between generated and data
distributions. Let ζ be a simple latent distribution, let
fθ:Z→X be a neural generator, and let β be the data
distribution. The objective is to find θ such that
This viewpoint includes Wasserstein GANs, MMD-GANs and Sinkhorn generative
models Arjovsky et al., 2017Dziugaite et al., 2015Genevay et al., 2018; when
D is written through a dual potential or discriminator, it connects
directly with the adversarial formulation in GANs via Duality. The
resulting training dynamics is the ordinary Euclidean gradient flow in
parameter space,
For αt-a.e. x, let ηt,x be the disintegration of the latent
law ζ with respect to the map fθt. Thus ηt,x is
supported on the fiber {z:fθt(z)=x}, and for every bounded
measurable ψ,
The velocity (60) depends on the parameter value
θt and on the latent disintegration, not only on the measure
αt. If the parametrization is non-identifiable, two different
parameters can generate the same measure while inducing different velocities.
Thus (56) is a Euclidean gradient flow on parameter
space, and only after push-forward a model-dependent flow on measures. It
coincides with an intrinsic Wasserstein gradient flow only in special cases
where vt agrees with the Wasserstein velocity
More generally, a projected Wasserstein flow on the model manifold would
require projecting this intrinsic velocity onto the infinitesimal velocities
attainable by variations of θ, using the L2(αt) metric. The
ordinary Euclidean parameter gradient flow (56) does
not perform this projection in general.
In machine learning, however, β is accessed through minibatches. If
then the implemented update often replaces Hβ by the random objective
Hβ^n. For nonlinear discrepancies this is not, in general, an
unbiased gradient estimator:
The expectation is over the data minibatch. This bias is a finite-sample effect
of inserting the empirical measure inside a nonlinear transport or adversarial
optimization before differentiating; it is distinct from the optimization noise
of stochastic gradient descent. MMD losses admit unbiased U-statistic
variants, but OT and entropic OT objectives generally exhibit the bias--variance
phenomena discussed in Bias and Variance of OT.
One-Step Model Using Wasserstein Flow of Discrepancy¶
This construction keeps the discrepancy-minimization viewpoint of the previous
paragraph but changes the dynamics. Instead of following the Euclidean gradient
of the discrepancy in parameter space, one prescribes the Wasserstein gradient
flow of the generated law and then learns a generator update realizing this
motion. This distribution-space, natural-gradient-type dynamics is less tied to
a particular parametrization and can have better convergence behavior, in
particular by reducing parameter-space traps when the discrepancy has a
favorable geometry.
Let ζ be a simple latent distribution and let αθ=(Gθ)♯ζ be the model distribution. Assume that the target data distribution is β. The Wasserstein-flow construction chooses a discrepancy
for instance a smoothed KL(α∣β), an MMD/IPM loss, or the debiased Sinkhorn divergence Lˉcϵ(α,β) introduced in the Sinkhorn divergence section. The associated formal descent is
Instead of integrating (67) at inference time, one fits, at each training time t, a parametric residual field Uηt along the current model distribution:
This is an ideal function-space update. A genuine one-step implementation fits the updated outputs back into a fixed generator architecture, or distills the accumulated transport into one network. After many training updates, that fixed-architecture or distilled generator is evaluated once at test time. This is the organizing principle behind recent one-step methods based on Wasserstein gradient flows: W-Flow uses such a construction with the Sinkhorn divergence as a tractable global discrepancy Han et al., 2026, while drifting methods evolve the generated distribution during training through a fitted vector field and also admit one-step inference Deng et al., 2026. The gradient-flow interpretation of drifting models, and its relation to KL, MMD, sliced-Wasserstein and Sinkhorn-type discrepancies, is analyzed in Gretton et al., 2026He et al., 2026. These ideas are also connected to the Sinkhorn-type normalization dynamics used to model attention in Sinkformers Sander et al., 2022.
A particularly transparent instance uses the sliced objective introduced for
imaging and barycenters by Rabin, Peyré, Delon and Bernot
Rabin et al., 2011. Take
with SW2 defined in Sliced Wasserstein Distances. With the
continuity-equation convention
∂tαt+div(αtwt)=0, the descent velocity
points from the current projected law toward the target projected law. More
precisely, assume that α has a density and sufficient moments so that the projected monotone maps are uniquely defined for almost every direction. If Tθ
denotes the one-dimensional monotone transport from (Pθ)♯α
to (Pθ)♯β, then the formal W2-gradient-flow velocity is
The sign follows from the one-dimensional identity: the first variation of
21W22(ρ,ν) has spatial derivative s−T(s), so the descent
velocity is T(s)−s, and composing with Pθ lifts it in the direction
θ.
Thus empirical implementations only require one-dimensional sorting along
sampled directions, followed by averaging the lifted projected displacements.
This is the sliced-Wasserstein flow studied by Cozzi and Santambrogio
Cozzi & Santambrogio, 2024, who prove long-time convergence under
their hypotheses when the target is Gaussian and also show that the limiting
characteristic map is not, in general, the optimal transport map. When both the
evolving law and the target are Gaussian, the averaged velocity is affine and
the flow closes on means and covariances; this finite-dimensional closure is
revisited in Flows over the Gaussian Manifold, where the sliced
objective appears in the Gaussian closure catalogue of
Proposition: Gaussian closure catalogue.
The difference between the full W2 descent and its sliced analogue is
already visible on a simple shape example. Div
compares the exact empirical flow of 21W22(⋅,β), where
one fixed optimal assignment gives straight relaxation curves, with the
W2-gradient flow of 21SW22(⋅,β), where the velocity is
recomputed from projected monotone rearrangements.
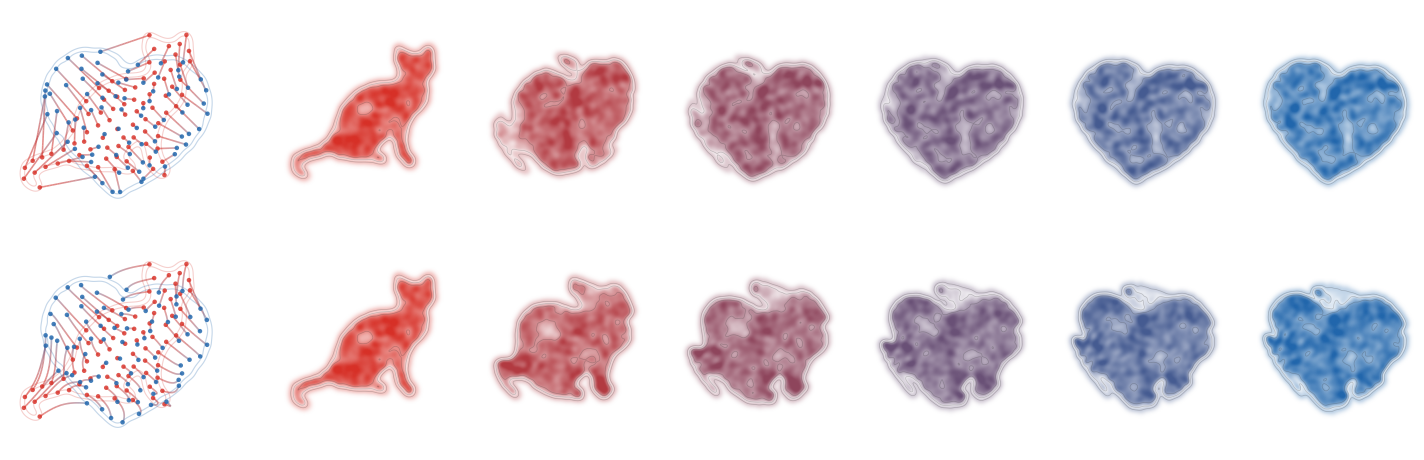
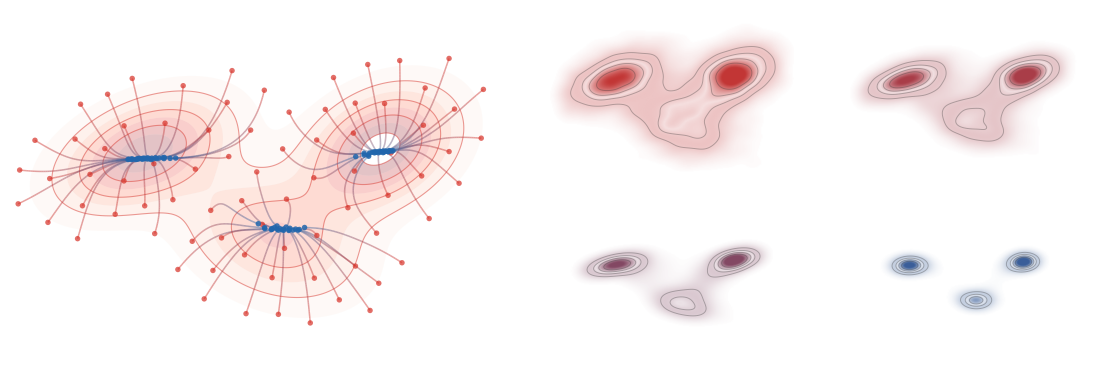
Full Wasserstein and sliced-Wasserstein flows from a cat-shaped empirical law
to a heart-shaped target. The left panel in each row shows representative
particle trajectories colored from red to blue. The five panels on the right
render kernel-density estimates of all particles at common normalized times.
The W2 flow follows the fixed optimal assignment and therefore straight
relaxation rays, whereas the sliced flow averages one-dimensional sorted
rearrangements over projection directions, producing curved trajectories and a
different transient density evolution.
Interactive panel. Change the slicing angle and samples to compare a global quadratic assignment flow with the coordinatewise flow induced by one projected sliced direction.
Stein variational gradient descent (SVGD) is another deterministic particle
flow that fits naturally in this one-step viewpoint Liu & Wang, 2016.
Its original motivation is Bayesian sampling: given a target probability
β=ρβdx known through its score
∇logρβ=−∇V, but not necessarily through its normalizing
constant, drive a particle cloud toward β without estimating the score of
the current empirical law. Geometrically, this replaces
the Wasserstein gradient flow of KL(α∣β), whose tangent norm is
L2(α), by the kernelized Benamou--Brenier geometry of
Kernelized Benamou--Brenier Distances, whose velocities live in a vector-valued RKHS.
For the formal density-level calculation, assume
α=ραdx and β=ρβdx have smooth positive
densities, and let v be a smooth compactly supported vector field. For the
perturbation αϵ=(Id+ϵv)♯α, integration by
parts gives
The bracket is the Langevin--Stein operator applied to v and averaged under
α; because it only evaluates v, divv, and the target
score at sample locations, it remains meaningful when α is empirical.
Optimizing this linear functional over the unit ball of Hkd and using
the reproducing property gives the RKHS steepest-descent direction,
The first term attracts particles toward increasing target log-density; the second term is a kernel repulsion that prevents immediate collapse.
The gradient-flow interpretation and its many-particle limits are studied in
Liu, 2017Duncan et al., 2023Nüsken & Renger, 2023.
In generative modeling terms, SVGD transports a simple empirical latent law by
repeated smooth particle updates. It is therefore close in spirit to the
drifting fields above, but its velocity is not learned by regression: it is the
closed-form RKHS steepest-descent direction of the KL functional.
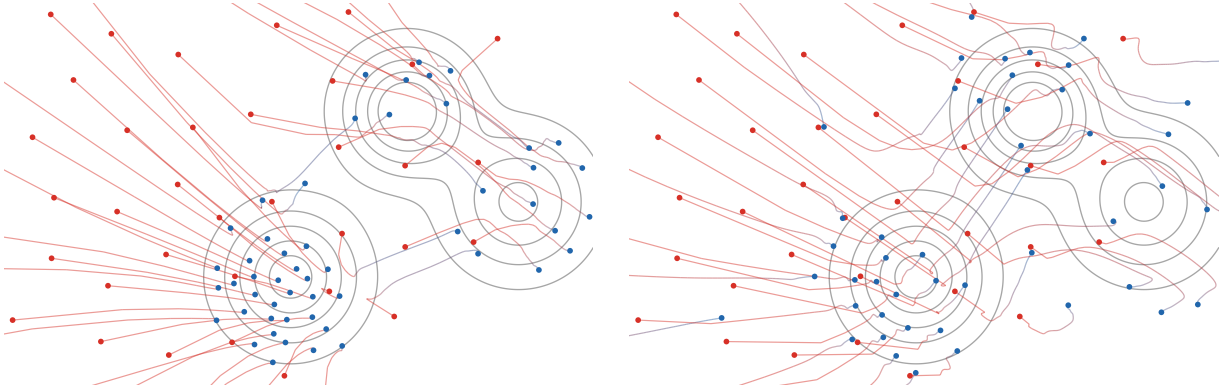
The figure below contrasts this RKHS flow with a particle closure of the Wasserstein gradient flow of KL(α∣β). The latter evaluates the current score ∇logρα by a Gaussian KDE, while SVGD avoids this density estimate and uses the target score together with a kernel repulsion.
Figure Div contrasts this RKHS flow with a particle closure of the Wasserstein gradient flow of KL(α∣β).
Particle trajectories for two deterministic descents of relative entropy toward the same three-Gaussian target, whose density is shown by gray contours. The left panel approximates the W2 gradient flow of KL(α∣β) by the KDE velocity ∇logρβ−∇logρα,h. The right panel uses the RBF-kernel SVGD velocity (73), where target-score attraction is coupled with RKHS repulsion. Both panels use the same initial particles and color trajectory time from red to blue.
Interactive panel. Change the number of particles and integration time to
compare a KDE Wasserstein closure with an RKHS Stein-type particle flow.
Drifting methods need not start from an exact Wasserstein gradient. They often prescribe an attraction-minus-repulsion field and then regress this field in L2(αt). A simple continuous version uses a strictly positive kernel Kϵ(x,y) for which the following integrals are finite, and defines, for any probability measure ν,
The first term pulls samples toward data, while the second term corrects self-attraction and prevents all particles from collapsing onto the same high-density region. For a fixed reference measure, Bϵ[ν] is precisely the Gaussian mean-shift displacement in (112): it moves x toward the local kernel barycenter of ν. Hence self-corrected drifting can be read as the difference between a target mean-shift field and the current model’s own mean-shift field. Sinkhorn drifting replaces these one-sided kernel normalizations by two-sided entropic OT couplings, so that the cross and self terms are normalized by Sinkhorn scaling rather than by a single denominator He et al., 2026.
Figure Div illustrates why the self term matters: it corrects the collapse created by target attraction alone and improves coverage of separated modes.
Drifting trajectories for a small particle generator. The raw kernel drift has weak long-range attraction and can leave particles away from the data modes. The self-corrected field uses the difference Bϵ[β]−Bϵ[αt], so a longer integration brings particles to the blue modes while repelling them from their own current concentration.
Interactive panel. Use the drift and time controls to inspect a learned-looking velocity field and its induced particle trajectories.
Proof
Since αt and ϕt are fixed in the variation with respect to α, the first variation is
The Wasserstein gradient-descent velocity is the negative of this gradient, namely ut. Substituting this velocity in the continuity equation gives the claimed flow.
Moment measures give another way to make a whole distribution from one convex potential. Instead of first fixing a simple source law and then learning a transport map, one asks for a convex function whose own log-concave density is pushed forward by its gradient. This couples sampling and mapping in a rigid way: the same potential defines both the source density and the Brenier map. The reward is a hidden convex structure: after a suitable optimal-transport reformulation, a nonlinear equation on convex functions becomes a convex minimization problem for probability densities. This is one of the cleanest places where optimal transport, Prékopa-type inequalities and convex geometry meet.
The normalization removes additive constants in u. Translations of the argument are another invariance: if ua(x)=u(x−a), then ηua is the translate of ηu, while ∇ua(x)=∇u(x−a), hence M(ua)=M(u). A first obstruction is immediate. Formally, if u is smooth and e−u decays fast enough for the boundary term to vanish, then
Thus moment measures are necessarily centered. The nonsmooth theory uses essentially continuous convex functions: lower-semicontinuous convex functions whose set of discontinuity points has zero Hd−1 measure. Since a convex function is continuous in the interior of its effective domain, this condition controls only its boundary behavior.
Figure Div shows the forward construction in one dimension. The map u′ is implicit in the push-forward, but the display focuses on the two visible measures: the log-concave source ηu=Zu−1e−udx and the resulting moment measure M(u).
Forward moment-measure construction in one dimension. Each column shows a convex potential u chosen so that the moment measure has a prescribed shape: a skewed unimodal density, two bumps, and three bumps with different widths and heights. The top row overlays u (gray, vertically rescaled) with the density of the log-concave source ηu=Zu−1e−udx (red), while the bottom row shows M(u)=(u′)#ηu (blue); the dashed vertical line marks the zero barycenter.
Interactive panel. Change the convex potential coefficients and watch the
same (u) define both the log-concave source measure (\eta_u) and the
moment measure obtained by pushing it through the monotone map (u’).
This theorem is due to Cordero--Erausquin and Klartag Cordero-Erausquin & Klartag, 2015. It is a functional analogue of a Minkowski-type problem: the target measure prescribes how the gradient image of a log-concave density should be distributed. The hyperplane condition is the natural non-degeneracy assumption; otherwise the prescribed gradient image lives in a lower-dimensional affine direction and no coercive full-dimensional convex potential can be recovered.
Santambrogio Santambrogio, 2016 reformulates the moment-measure problem as a minimization over absolutely continuous probability measures. For a centered α∈P1(Rd), define the maximal-correlation transport functional, with values in R∪{+∞},
with H(η)=+∞ when η is not absolutely continuous.
The centering of α makes this functional invariant under translations of η, since translating η by a vector a changes ∫x⋅ydπ by a⋅∫ydα(y)=0.
Proof
The existence proof has two ingredients. First, since α is centered, translating η does not change either H(η) or Cα(η), so one can center a minimizing sequence. Second, the assumption that α is not supported on a hyperplane gives a coercive lower bound of the form Cα(η)≥cα∫∥x∥dη(x) for centered absolutely continuous η, with cα>0. Together with the lower-semicontinuity estimates for entropy and maximal correlation, this yields a minimizer Santambrogio, 2016.
Let η=rdx be a minimizer and let u be a convex optimizer in the dual formula (94). Keeping u fixed and varying η in (96) gives the Euler equation
so η=Zu−1e−udx. The optimality condition for the scalar-product transport problem says that an optimal coupling is supported on {(x,y):y∈∂u(x)}. Since η is absolutely continuous and u is convex, ∂u(x)={∇u(x)} for η-almost every x, hence α=(∇u)♯η.
Conversely, assume η=Zu−1e−udx and α=(∇u)♯η. Let ν be a smooth compactly supported competitor, and let T be the Brenier map from η to ν. Along the geodesic ηt=((1−t)Id+tT)♯η, the right derivative of the entropy at t=0 is
because (Id,∇u)♯η is optimal for the scalar-product problem. The two bounds coincide, so the first-order terms cancel. Hence the one-sided derivative of H+Cα at η in every such direction is zero. Displacement convexity implies global minimality, and approximation removes the smooth compact-support restriction. Strict displacement convexity of entropy gives uniqueness, except for translations; translations do not change Cα because α is centered.
It remains to justify the convexity assertion. The entropy term is displacement convex by McCann’s theorem, recalled in Theorem Theorem: McCann Displacement Convexity for Internal Energies. If α has finite second moment, identity (95) writes Cα as the sum of the 1-convex moment term η↦21∫∥x∥2dη and the (−1)-convex term η↦−21W22(η,α), hence Cα is displacement convex. For a target with only a finite first moment, Santambrogio obtains the same convexity along P2 geodesics by approximation and proves the full variational characterization by lower semicontinuity.
The moment-measure factorization suggests a generative recipe: sample X from the log-concave law Zu−1e−u and output ∇u(X). This ties sampling and mapping through the same convex potential. Vesseron, Béthune and Cuturi Vesseron et al., 2025 argue that this direct factorization can be poorly adapted to practical generative modeling, and propose instead the conjugate factorization
Here ∇w∗ is the Brenier map from the learned log-concave source to the target distribution β. This keeps the single-convex-potential philosophy, but places the transport map on the conjugate side; it can be parameterized by input-convex neural networks and trained using OT solvers. From the viewpoint of this chapter, moment measures are therefore a rigorous convex-analytic prototype for one-step generators based on gradients of convex potentials.
Deep residual architectures can be read as time discretizations of ODEs or PDEs. For transformers, the transported objects are token measures and the velocity is induced by attention.
Transformers were introduced as sequence-to-sequence architectures driven by self-attention Vaswani et al., 2017 and have since become a central architecture for language and vision models Brown et al., 2020Dosovitskiy et al., 2021. Their distinctive feature is that each token is updated by a data-dependent average of all other tokens. This makes an attention layer permutation-equivariant before positional encoding, context dependent after conditioning on the input sequence, and naturally compatible with a measure viewpoint in which a prompt is regarded as an empirical distribution of tokens.
The mathematical limit used below concerns depth rather than model scale: one lets the number of residual attention layers grow while each layer makes a small update, as in continuous-depth neural networks Chen et al., 2018. For attention, the resulting velocity is nonlinear in the current token law because it is normalized by the whole context. This measure-theoretic view appears in the analysis of attention as a Lipschitz or interacting-particle operator Vuckovic et al., 2020Geshkovski et al., 2025, in the Sinkhorn-normalized dynamics of Sinkformers Sander et al., 2022, and in recent well-posedness and mean-field-limit results for several attention mechanisms Castin et al., 2025. It also separates the infinite-depth limit studied here from the token-limit question, where one controls how a finite empirical context approximates its limiting attention operator Bohbot et al., 2025.
We now consider very deep transformers, focusing on a single-head attention mechanism for simplicity while ignoring MLP layers, layer normalization, causality, and masking. This stripped-down framework is best suited to modeling encoders and vision transformers; the references above indicate which parts of this simplified picture extend to richer attention mechanisms.
After tokenization, embedding, and positional encoding, each input is represented as a point cloud (xi)i=1n of n vectorized tokens. An attention layer with a skip connection and residual scale 1/T, where T is the depth, transforms the tokens according to
where θ=(K,Q,V) denotes the three parameter matrices. The conventional factor 1/r, with r the query/key dimension, can be absorbed into Q or K and is omitted here.
At the level of the token distribution, the layer uses the context-dependent velocity Γθt[α] and pushes α forward by Id+τΓθt[α]. This map depends on the whole context α and on the depth-dependent parameters θt. Denoting normalized depth by t∈[0,1] and setting τ=1/T gives
A particularly geometric variant replaces the dot-product score ⟨Qx,Ky⟩ by a negative squared Euclidean score sϵ(x,y)=−∥x−y∥2/(2ϵ). Take, for simplicity, the same token space for queries, keys and values, and set
The map x↦mϵ[α](x) is exactly Gaussian-kernel attention, i.e. normalized kernel regression over tokens; such L2 or Gaussian-kernel scores are used explicitly in transformer variants motivated by Lipschitz control and projection-free attention Kim et al., 2020Kundu et al., 2026. Classical mean shift, however, uses the displacement from the current point to this local barycenter. This gives
and, when α is empirical, ρϵ[α] is a Gaussian kernel density estimate up to normalization. Thus Mϵ[α] is the classical Gaussian mean-shift vector Fukunaga & Hostetler, 1975Cheng, 1995Comaniciu & Meer, 2002. If the data measure α is frozen, the update x←mϵ[α](x) is the usual mode-seeking mean-shift iteration. If instead all support points move and the empirical measure is recomputed after every step, one obtains the self-consistent, or blurring, mean-shift process Chen, 2015. Its damped update is
For τ=1 this is discrete blurring mean shift; for small residual steps it becomes a transport PDE that moves each token uphill along the log of the smoothed token density. This distinction between the raw barycentric attention output mϵ and the velocity Mϵ=mϵ−Id is important: adding mϵ directly as a residual would produce a different drift. The mean-shift form isolates a purely metric attention mechanism from the learned bilinear geometry of ⟨Qx,Ky⟩.
When the averaging measure evolves together with the particles, mean shift
becomes a consensus model. The Hegselmann--Krause model updates each opinion by
averaging the opinions inside a confidence neighborhood
Hegselmann & Krause, 2002; its finite-agent convergence
was developed further in Blondel et al., 2009, and a
measure-valued Eulerian formulation appears in
Canuto et al., 2012. The row-normalized average below
is also characteristic of Motsch--Tadmor dynamics
Motsch & Tadmor, 2014.
The positive matrix PX is row-stochastic. Its ith row is the
probability law used to average the cloud from xi. Figure
Div visualizes the corresponding
loss of memory for a fixed Markov matrix; mean shift applies the same averaging
mechanism to every spatial coordinate, but with a matrix that changes with the
cloud. The particle system is
A row-stochastic matrix P is order preserving and satisfies
P(z+s1n)=Pz+s1n. It is therefore a linear
topical map, so Proposition Proposition: Topical Maps are Variation-Nonexpansive gives
nonexpansiveness on the additive quotient. Strict positivity yields more:
Birkhoff contraction can be linearized at the constant ray to obtain a strict
variation contraction.
Proof
Fix two rows p=(Pij)j and
p′=(Pℓj)j, and remove their common mass
rj=min{pj,pj′}. The two residual nonnegative measures have the same
mass
Their averages of z can differ by at most this mass times ∥z∥V.
Maximizing over output rows proves the upper bound in
(120). Conversely, for a pair of rows attaining
the maximum, take zj=1 when pj≥pj′ and zj=0 otherwise. Then
∥z∥V=1 and the corresponding output difference equals the Dobrushin
coefficient, proving equality and hence the variation contraction.
If P>0, apply Birkhoff contraction to us=esz and
1n. Since P1n=1n,
Moreover,
Pesz=1n+sPz+O(s2), so
log(Pesz)=sPz+O(s2). Dividing by ∣s∣ and letting
s→0 gives ∥Pz∥V≤λ(P)∥z∥V. Taking the exact quotient norm then yields the
comparison. This Hilbert--Hopf--Dobrushin relation extends to Markov
operators on general cones Gaubert & Qu, 2015.
By duality, the same coefficient is the exact contraction factor of the adjoint
Markov evolution on probability vectors: for p,p′∈Δn,
Thus (121) contracts observables modulo
constants, while the adjoint inequality contracts probability laws in total
variation. The proposition also separates two useful constants. The Dobrushin
coefficient is sharp but depends on the normalized rows. The Birkhoff
coefficient can be looser, but its cross-ratio formula is explicit and
invariant under positive diagonal scalings, precisely the invariance used in
the Sinkhorn proof of Theorem Theorem: Projective Linear Convergence of Sinkhorn.
For a compact C⊂Rd and α∈P(C), the corresponding
Markov operator is
The equality in the middle is the same diagonal-scaling invariance used by
Sinkhorn: the normalization diag(KXa)−1 and the weight
matrix diag(a) disappear from every projective cross-ratio.
The integral Birkhoff--Hopf theorem and the same linearization therefore give
Positivity and Lipschitz regularity on the compact set C0×C0 make
the characteristic field uniformly Lipschitz in x and Lipschitz in α
for W1. Moreover,
x+MK[α](x)=PαId(x) belongs to
conv(suppα). Hence no characteristic
crosses an outward supporting hyperplane, the convex hulls are nested, and the
flow is globally well posed.
Taking the supremum over directions gives the one-step factor qk;
multiplying these factors and using qk≤qτ proves the discrete
diameter estimate. Since ∥∥xik+1−xik∥∥≤τD(Xk), every path
is Cauchy; summing the uniform geometric tail gives the pointwise estimate.
For the measure flow, let fθ(x)=⟨θ,x⟩ and let
wθ(t) be the width of the support in direction θ. Its upper Dini
derivative satisfies
Gronwall’s lemma and the directional diameter identity give the adaptive
estimate. Finally, every characteristic has speed at most D(t), hence is
Cauchy. All limits coincide because D(t)→0, and integrating the exponential
tail gives the W∞ estimate.
Strict positivity therefore gives a global exponential rate, while contraction
becomes much stronger once the cloud is narrow relative to the bandwidth.
These are Birkhoff bounds; the exact Dobrushin factors can be smaller.
The projective argument also clarifies what is not conserved and when
clustering replaces consensus. Because row normalization makes the coefficients
asymmetric, the consensus point need not equal the initial barycenter; that
barycenter is conserved for the constant kernel, but not in general. The
self-consistent flow should not be confused with classical mode seeking, where
the data measure is frozen and different queries may converge to different
modes. Finally, one-point consensus can fail for the hard confidence kernel
KR(x,y)=1{∥x−y∥≤R}: once the interaction graph
disconnects, its Dobrushin and Birkhoff coefficients can equal one. The discrete
Hegselmann--Krause dynamics then converges to opinion clusters
Blondel et al., 2009; under the Eulerian hypotheses,
the limit is a finite combination of Dirac masses separated by at least RCanuto et al., 2012. For the Gaussian kernel,
global positivity eventually forces one Dirac, although
1−tanh(D02/(4ϵ)) can be very small and the multimodal transient can
be long.
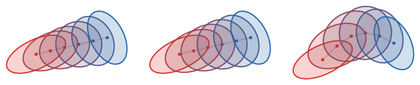
Continuous-time mean shift for a densely sampled three-Gaussian mixture. Left: initial density level sets, in red, and representative particle paths of x˙=Mϵ[αt](x), colored from red to blue. Right: four later kernel-density renderings of αt at increasing times, with the same red-to-blue time palette; the initial density is omitted because it is shown on the left. The snapshots show the long multimodal transient before globally positive Gaussian interactions drive the cloud toward the one-point consensus of Theorem Theorem: Dobrushin consensus for positive mean shift.
Interactive panel. Vary the bandwidth, particle count, and integration time to see the mean-shift transport PDE sharpen a three-mode density.
When the token space has dimension d and the query/key space has dimension r, take Q,K∈Rr×d and V∈Rd×d. If V=Q⊤K, the field Γθ[α] is a gradient vector field in the token variable. Indeed, define the log-partition potential
This proves only that the velocity is an instantaneous gradient in x; it does not by itself identify a Wasserstein energy. Indeed, the natural scalar candidate
up to an additive constant. The second term is the response of every query normalization to a perturbation of the key distribution, and its spatial gradient is absent from Γθ[α]. Thus, without additional symmetry or integrability conditions, the attention PDE is a transportation dynamics rather than the Wasserstein gradient flow of this fixed scalar functional. Special variants recover additional structure: Sinkhorn attention can be interpreted through doubly stochastic normalization and Wasserstein-type gradient flows Sander et al., 2022Castin et al., 2025, while layer normalization leads naturally to dynamics on the sphere and to modified metrics. The key open difficulty for the present viewpoint is training: after the architecture has been rewritten as a controlled transport equation, learning corresponds to optimizing the time-dependent parameters (θt)t rather than merely analyzing the forward PDE for fixed parameters.
Gaussian measures provide a useful testing ground for the preceding dynamics. They are not invariant under a general Wasserstein gradient flow: a nonlinear velocity usually creates non-Gaussian densities immediately. The useful substitute is to either identify affine velocities, which exactly preserve Gaussianity, or to project the dynamics onto the Gaussian manifold. In both cases the measure PDE reduces to matrix ODEs for the mean and covariance. This viewpoint is emphasized in the survey Peyré, 2025 and is useful for comparing diffusion paths, Wasserstein gradient flows, drifting fields and transformer-type dynamics.
For constrained gradient flows on this family, the covariance equation is the finite-dimensional Bures--Wasserstein gradient flow on positive definite matrices. Thus Gaussian closure is not just a computational shortcut: it is the restriction of Wasserstein geometry to the Gaussian submanifold, where affine gradient fields encode tangent vectors. The following figure first compares three bridge-type Gaussian closures from a source α0 to a target γ; the exact gradient-flow closures for specified energies f(α) are catalogued afterwards in Proposition: Gaussian closure catalogue.
Figure Div first compares three bridge-type Gaussian closures from a source α0 to a target γ; the exact gradient-flow closures for specified energies f(α) are catalogued afterwards in Proposition Proposition: Gaussian closure catalogue.
Gaussian closures from a red source α0 to a blue target γ=N(mˉ,Σˉ). The left panel is the constant-speed W2 geodesic, equivalently the displacement interpolation minimizing the Benamou--Brenier action between α0 and γ. The middle panel is an entropic Sinkhorn/Schrödinger bridge-style closure for the quadratic cost ∣x−y∣2 and regularization strength ϵ>0; it is a bridge toward γ, not the gradient flow of a fixed energy f(α), and the entropic noise inflates intermediate covariances. The right panel is a prescribed non-variational drifting flow, governed by a continuity equation with an affine Gaussian-preserving velocity, chosen so that the mean follows a curved path while the covariance is moment-matched to the same endpoint γ.
Interactive panel. Use the anisotropy, angle, regularization, and drift controls to compare Gaussian closures of Wasserstein, Sinkhorn, and drifting dynamics.
The first question is invariance: one wants a simple criterion ensuring that the continuity equation does not leave the finite-dimensional Gaussian family.
Proof
Let Xt follow the characteristic ODE X˙t=bt+At(Xt−mt) with X0∼N(m0,Σ0). Since m˙t=bt, the centered variable X~t=Xt−mt solves the homogeneous linear ODE X~˙t=AtX~t. If Φt is the fundamental matrix Φ˙t=AtΦt, Φt=0=Id, then
This proves Gaussian preservation and the moment ODE. The Wasserstein gradient-flow statement follows by inserting the descent velocity vt=−∇∇f(αt).
For the converse, fix α=N(m,Σ) and denote its density by ρ. Tangency to the Gaussian manifold means that the density variation −div(ρV) is generated by some moment variation (m˙,Σ˙), with Σ˙ symmetric. Set b=m˙, and let A=A⊤ be the unique solution of
in the distributional sense. Both V and V0 belong to the L2(α) closure of gradient fields. The weighted Helmholtz decomposition therefore makes V−V0 simultaneously a tangent gradient and orthogonal to every tangent gradient, so V=V0 in L2(α). Equivalently, for a smooth representative V−V0=∇ψ, integration by parts gives ∫∥∇ψ∥2dα=0. This proves that the Wasserstein tangent representative is affine. The qualification is essential: without selecting the gradient representative, one can add a nonzero field with zero α-weighted divergence without changing the Gaussian curve.
For a prescribed smooth Gaussian curve, set bt=m˙t and choose any matrix At satisfying AtΣt+ΣtAt⊤=Σ˙t. Since Σt is positive definite, the Lyapunov map A↦AΣt+ΣtA is invertible on symmetric matrices, which gives the unique symmetric choice when a gradient velocity is required. In that case vt is the gradient of the quadratic potential x↦⟨bt,x⟩+⟨At(x−mt),x−mt⟩/2.
We now instantiate the affine-gradient viewpoint by tracking functionals whose full Wasserstein gradient is affine on Gaussian inputs. The catalogue below contains exact Gaussian-preserving Wasserstein flows, not projected or constrained flows; the separate constrained construction is discussed only afterwards.
Proof
For the moment-functional row, the formula is exact on the full Wasserstein space. Indeed, write
These first variations are quadratic in x, hence the affine Gaussian flow coincides with the full Wasserstein gradient flow.
For the KL row, write α=ρdx and let ργ denote the density of γ. The ambient first variation is log(ρ/ργ) up to an additive constant. If α=N(m,Σ), then
Proposition Proposition: Affine velocities preserve Gaussianity gives h(m,Σ)=−Aδm and H(m,Σ)=2Id−ΣA−AΣ. For the Fisher row, writing u=log(ρ/ργ), the ambient first variation of 21I(α∣γ) is, up to constants,
Hence the Wasserstein velocity is affine and the Gaussian family is closed, with the displayed h and H. Although the ambient Fisher flow is a fourth-order PDE for a generic density, it is therefore an exact finite-dimensional closure in this quadratic-reference case.
For W22(α,γ), the Brenier map from N(m,Σ) to γ is
The descent velocity for the unhalved squared distance is 2(T−Id), which gives the mean and covariance equations through Proposition Proposition: Affine velocities preserve Gaussianity. For the MMD row, k(x,y)=⟨x,y⟩2 identifies the kernel mean embedding with the raw second moment. Thus
and the ambient first variation is 2x⊤Rx, whose descent velocity is −4Rx. This gives h(m,Σ)=−4Rm and H(m,Σ)=−4(ΣR+RΣ).
For the Sinkhorn row, Corollary Corollary: Gaussian Sinkhorn Divergence and Smoothed Bures Term gives the closed Gaussian formula as a squared mean displacement plus the smoothed Bures term Bϵ2. This is not only a formula on the Gaussian submanifold. The first variation of the entropic value with respect to the first marginal is a Sinkhorn dual potential, and for Gaussian marginals the cross and self dual potentials are quadratic. Their debiased combination is therefore quadratic, so its spatial gradient is affine. Since the restriction of the functional to Gaussians is
the quadratic coefficient is Gϵ=∇ΣBϵ(Σ,Σˉ)2, and the moment-functional computation gives the displayed h and H. To compute this gradient, set BΣ,Σˉ=Σˉ1/2ΣΣˉ1/2. Since ψϵ′(r)=−2τϵ(r), differentiating
trψϵ(BΣ,Σˉ1/2) gives
whereas differentiating the self term
−21trψϵ(Σ) gives τϵ(Σ). This proves the displayed closed form for Gϵ. When Σˉ=Id, this covariance contribution is a spectral function of Σ. If λ is an eigenvalue of Σ, the corresponding scalar velocity is
For Gaussian marginals, Tθ is affine. Thus this velocity is affine in x, and Proposition Proposition: Affine velocities preserve Gaussianity applies. The spherical identity ∫θθ⊤dσ(θ)=Id/d gives the mean equation, and differentiating the covariance term gives Gsw.
Not every PDE preserves Gaussianity exactly. Wasserstein flows of generic higher-order regularizers usually create higher moments immediately and require a Gaussian projection to close on (m,Σ). Such projected closures are still useful: they expose the finite-dimensional dynamics predicted by a variational model and make it easy to compare variational flows with non-variational affine dynamics such as drifting fields or the Gaussian transformer closure below.
The preceding affine-gradient examples have a limited scope: most Wasserstein gradient flows of a functional f(α) are not closed on the Gaussian manifold. A nonlinear ambient velocity creates higher-order moments immediately, so the exact Gaussian closure usually fails. The constrained viewpoint deliberately replaces the full evolution by its projection onto G, forcing the curve to remain Gaussian while keeping the Wasserstein tangent geometry.
be the Gaussian submanifold of P2(Rd). The Wasserstein gradient of a functional constrained to a smooth submanifold M⊂P2 is defined as the Riesz representative of the differential restricted to tangent velocities of M. Equivalently, it is the small-step limit of the constrained JKO scheme
For M=G, tangent velocities are affine gradient fields v(x)=b+A(x−m) with A=A⊤. The constrained gradient is therefore the L2(N(m,Σ)) projection of the ambient Wasserstein gradient onto this finite-dimensional affine space, whenever the ambient gradient exists.
Proof
Test the functional along a Gaussian tangent vector, represented by an affine gradient field
for all affine gradient fields v. This identifies the constrained Wasserstein gradient in the induced L2(α) metric, or equivalently the projection of the ambient gradient when it exists. Substituting the descent velocity −vF in Proposition Proposition: Affine velocities preserve Gaussianity gives (209).
This proposition is the organizing rule for constrained Gaussian closures: once the scalar energy has been reduced to a function of (m,Σ), its constrained Wasserstein gradient is automatically affine and the covariance follows the Bures-type ODE (209). When the first variation of f is quadratic, this constrained gradient coincides with the full Wasserstein gradient.
The last examples are not ordinary gradient flows of a fixed scalar energy on the full Wasserstein space. They preserve Gaussianity because the prescribed velocity field is affine when evaluated on Gaussian measures.
The preceding examples show when Gaussianity is preserved or imposed by projection. Gelbrich’s inequality Gelbrich, 1990 gives a useful variational explanation: replacing a measure by the Gaussian with the same first two moments cannot increase its Wasserstein distance to another similarly projected measure.
Proof
Take any coupling (X,Y) of α and ν, center the variables, and write C=E[(X−mα)(Y−mν)⊤]. In the positive definite case, positivity of the block covariance matrix implies the factorization C=Σα1/2KΣν1/2 with ∥K∥op≤1, and therefore, by operator/nuclear norm duality,
Proposition Proposition: Nondegenerate Gaussian inputs remain Gaussian is an earlier application of this
contraction: because every Gaussian input is fixed by R, projecting
any competitor cannot increase the quadratic Wasserstein barycenter objective.
The following preservation criterion is a direct consequence of Gelbrich’s theorem and was explained to us by Hugo Lavenant. It says that a functional which does not increase under moment-matched Gaussian projection admits Gaussian minimizing movements from Gaussian initial data.
Proof
For the JKO claim, Rγ=γ because γ is Gaussian. Hence, for any competitor η,
Gaussian preservation concerns the full law, whereas moment closure asks only whether selected statistics obey an autonomous system. The first row of Proposition Proposition: Gaussian closure catalogue in fact gives a distribution-free closure. If f(α)=g(mα,Σα) and G=∇Σg(mα,Σα) denotes the symmetric Frobenius gradient, then the Wasserstein descent velocity is vα(x)=−∇mg(mα,Σα)−2G(x−mα). It is affine in x for every α, not only for Gaussian laws. Consequently, every sufficiently regular flow starting from an arbitrary α0∈P2(Rd) satisfies
For Gaussian initial data, this affine velocity also preserves Gaussianity; for general initial data, the law need not become Gaussian, but its mean and covariance still follow the same closed vector field (h,H) listed in that proposition.
This suggests asking which linear statistics α↦∫φdα admit an exact closure. For scalar statistics, the answer is completely characterized by an eikonal equation.
Proof
The first variation is δfg(α)(x)=g′(mφ(α))φ(x), so the continuity equation gives the displayed evolution of mt. Condition (233) then proves sufficiency.
For necessity, it is enough to take g(s)=s and write ψ=∥∇φ∥2. Autonomy for Dirac laws first shows that ψ=q∘φ for some function q on φ(Ω). Because Ω is connected, φ(Ω) is an interval. Comparing a Dirac law with any two-point mixture having the same φ-moment shows that
Peyré, G. (2025). Optimal and Diffusion Transports in Machine Learning. arXiv Preprint arXiv:2512.06797.
Hyvärinen, A. (2005). Estimation of Non-Normalized Statistical Models by Score Matching. Journal of Machine Learning Research, 6, 695–709.
Vincent, P. (2011). A Connection Between Score Matching and Denoising Autoencoders. Neural Computation, 23(7), 1661–1674.
Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N., & Ganguli, S. (2015). Deep Unsupervised Learning Using Nonequilibrium Thermodynamics. Proceedings of the 32nd International Conference on Machine Learning, 37, 2256–2265.
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. Advances in Neural Information Processing Systems, 33, 6840–6851.
Song, Y., & Ermon, S. (2019). Generative Modeling by Estimating Gradients of the Data Distribution. Advances in Neural Information Processing Systems, 32.
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2021). Score-Based Generative Modeling through Stochastic Differential Equations. International Conference on Learning Representations.
Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., & Le, M. (2023). Flow Matching for Generative Modeling. International Conference on Learning Representations.
Liu, X., Gong, C., & Liu, Q. (2023). Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. International Conference on Learning Representations.
Albergo, M. S., Boffi, N. M., & Vanden-Eijnden, E. (2025). Stochastic Interpolants: A Unifying Framework for Flows and Diffusions. Journal of Machine Learning Research, 26(209), 1–80.
Efron, B. (2011). Tweedie’s Formula and Selection Bias. Journal of the American Statistical Association, 106(496), 1602–1614. 10.1198/jasa.2011.tm11181
Hertrich, J., Chambolle, A., & Delon, J. (2025). On the Relation between Rectified Flows and Optimal Transport. Advances in Neural Information Processing Systems.
Lavenant, H., & Santambrogio, F. (2022). The Flow Map of the Fokker–Planck Equation Does Not Provide Optimal Transport. Applied Mathematics Letters, 133, 108225.
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein generative adversarial networks. In D. Precup & Y. W. Teh (Eds.), Proceedings of the 34th International Conference on Machine Learning (Vol. 70, pp. 214–223). PMLR. https://proceedings.mlr.press/v70/arjovsky17a.html
Dziugaite, G. K., Roy, D. M., & Ghahramani, Z. (2015). Training generative neural networks via maximum mean discrepancy optimization. Uncertainty in Artificial Intelligence-Proceedings of the 31st Conference, UAI 2015, 258–267.