Entropic regularization makes optimal transport smooth, strictly convex and
scalable. This chapter first explains the discrete KL-regularized problem,
derives Sinkhorn’s alternating matrix scaling algorithm, and then rewrites the
same construction as a relative-entropy projection problem. It then records
the general continuous formulation, develops the dual soft-transform
picture, explains the path-space Schrodinger problem behind the static coupling
formulation, and presents the main convex regularization variants
and the debiased Sinkhorn divergence. A final section records a less standard
viewpoint: after fixing the potential gauge, the finite-dimensional Sinkhorn
equations admit a local holomorphic continuation to complex values of the
temperature.
Entropy turns a possibly non-unique linear program into a unique smooth
problem. The price is bias, but the reward is differentiability and fast
scaling algorithms.
Using this entropy as a regularizing function gives the approximate transport
value
Equivalently, the regularizer is
ϵ∑i,jPi,jlogPi,j. It penalizes concentrated couplings
and makes the objective strictly convex on the relative interior of the
transport polytope.
Proof
The transport polytope is non-empty and compact, and the objective is
continuous with the convention 0log0=0, so a minimizer exists. On the
relative interior,
is positive definite on every non-zero feasible direction. Hence
−H is strictly convex on the polytope, which gives uniqueness.
If ai,bj>0 and a minimizer had Pi,j=0, then the perturbation
Pt=(1−t)P+ta⊗b remains feasible for small t>0. The derivative
of rlogr at zero along a positive direction is −∞, so the objective
decreases, contradicting optimality.
The entropy acts as a barrier for positivity and makes
LCϵ(a,b) smooth in a, b, and C as long as these
variables stay in the relative interior. As ϵ→+∞, the
minimizer converges to the independent coupling a⊗b; as
ϵ→0, it approaches the optimal face of the original transport
linear program.
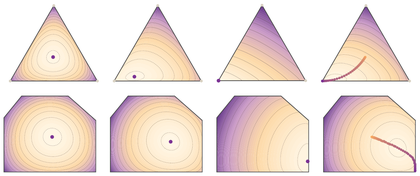
Figure Div visualizes this temperature-dependent path and contrasts it with a generic logarithmic barrier on linear-programming slacks.
show_book_figure("sinkhorn-entropy-lp-geometry")
Entropic regularization and slack barriers. Large ϵ selects an
interior reference point, while small ϵ moves the minimizer toward a
low-cost face of the transport polytope. The second row gives the analogous
entropy-on-slacks picture for a generic linear program.
Interactive panel. Move the temperature to see the entropic minimizer travel along the central path from the simplex interior toward the linear-programming vertex.
For a generic linear program minzℓ⊤z with constraints
Az≤b, one can introduce positive slacks s=b−Az and penalize them by an
entropy. This is a useful analogy, but it is not the standard self-concordant
interior-point barrier. The canonical barrier is the Burg, or reverse-KL,
barrier −∑ilogsi, which leads to Newton systems.
Optimal transport is special because entropy is placed on the entries of
P, while the constraints are only row and column marginals. This separable
structure turns Bregman projections into diagonal rescalings, giving the
Sinkhorn iterations.
Sinkhorn’s algorithm is alternating normalization of rows and columns. The
key point is that the optimizer of the entropic problem has a multiplicative
scaling form.
Proof
After removing zero-mass rows and columns, the minimizer is strictly positive,
so the positivity constraint can be ignored in the first-order conditions.
Introduce Lagrange multipliers f∈Rn and g∈Rm for the two
marginal constraints. The Lagrangian is
The division is entrywise. The scaling vectors are not unique: multiplying
u by λ>0 and v by 1/λ leaves P unchanged.
Figure Div exposes the alternating feasibility mechanism on a small matrix: each row or column normalization enforces one marginal exactly while generally perturbing the other.
show_book_figure("sinkhorn-marginal-errors")
Marginal constraints during Sinkhorn scaling. Row normalizations align the
red source marginal and leave a blue defect; column normalizations align the
blue target marginal and leave a red defect.
The interactive demo exposes the alternating row/column normalization directly.
Change the half-step count to see the current coupling acquire one marginal,
lose the other, and then converge toward both.
Interactive panel. Use the iteration, regularization, and mass controls to watch Sinkhorn row and column scalings enforce the marginals.
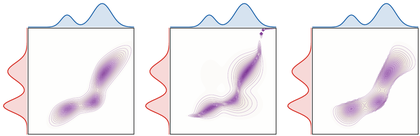
Figure Div shows the same alternating projection mechanism on a dense one-dimensional discretization, where the marginal defects appear as continuous side curves.
Dense Sinkhorn scaling for one-dimensional Gaussian-mixture marginals. The
violet side curves are the current row and column sums; the red and blue
curves are the prescribed marginals.
After convergence, the regularization strength controls how much of the Gibbs
kernel remains visible in the optimal plan. Small ϵ produces a
concentrated transport band, while larger ϵ spreads the same
marginals into a smoother coupling.
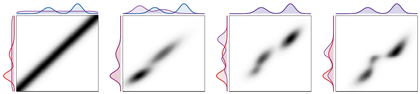
Figure Div compares these converged plans at four temperatures while keeping both marginals fixed.
show_book_figure("sinkhorn-coupling-iterations")
Final Sinkhorn couplings for the same one-dimensional marginals and four
regularization strengths. Decreasing ϵ sharpens the plan toward an
optimal-transport graph; increasing ϵ keeps more of the product
structure.
Before that, Figure Div tracks the same Sinkhorn scaling in dual variables.
KL-normalized dual potentials along the scaling iteration. The logarithmic
scaling potentials stabilize as the row/column normalizations converge.
The next interactive demo keeps the iteration count high and varies the temperature.
It is the quickest way to see the geometry-bias tradeoff: low temperature is
geometric and sharp, high temperature is smooth and closer to independence.
Interactive panel. Use the regularization slider to compare sparse exact-looking couplings with smoother entropic plans and potentials.
Complexity bounds for Sinkhorn and comparisons with accelerated first-order
methods are discussed in
Altschuler et al., 2017Dvurechensky et al., 2018Knight, 2008.
For a dense n×m problem, each iteration costs one multiplication by
K and one by K⊤, so the cost scales like Cnm for C iterations.
For fixed positive ϵ, the marginal error eventually has a linear
regime, but small ϵ makes the Gibbs kernel more peaked and scaling
harder.
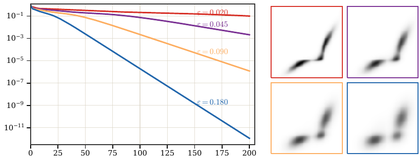
Figure Div complements the complexity discussion by plotting the marginal defect across half-steps and showing how smaller temperatures slow the observed linear regime.
show_book_figure("sinkhorn-linear-rate-epsilon")
Marginal violation along Sinkhorn half-steps for several values of
ϵ. Smaller ϵ gives sharper transport geometry but slower
scaling.
Interactive panel. Vary ϵ and the conditioning parameters to compare observed residual decay with Hilbert-metric convergence guides.
The KL formulation identifies Sinkhorn as a projection method. It also
prepares the continuous and unbalanced settings, where a reference measure is
essential.
A convenient tool to reformulate and normalize discrete entropy is relative
entropy. It turns entropy regularization into a finite-dimensional projection
problem and admits a direct measure-theoretic extension.
For matrices with the same total mass, the affine terms cancel and
On fixed-mass couplings, taking Q=1n×m is equivalent to
subtracting the Shannon--Boltzmann entropy.
Proof
Write ϕ(s)=slogs−s+1. Then ϕ(s)≥0, with equality only at
s=1. If P is not absolutely continuous with respect to Q, the
divergence is infinite. Otherwise,
Hence this problem has exactly the same minimizer as the original entropic OT
problem, while its optimal value is
LCϵ(a,b)+ϵ(H(a)+H(b)).
The normalization becomes substantive in unbalanced OT, where changing the
reference measure is no longer merely an additive shift.
Proof
Expand the logarithm and use the marginal constraints:
The tensor-product reference is nevertheless useful when supports vary. It
makes explicit which entries may vanish and passes cleanly to the continuous
formulation.
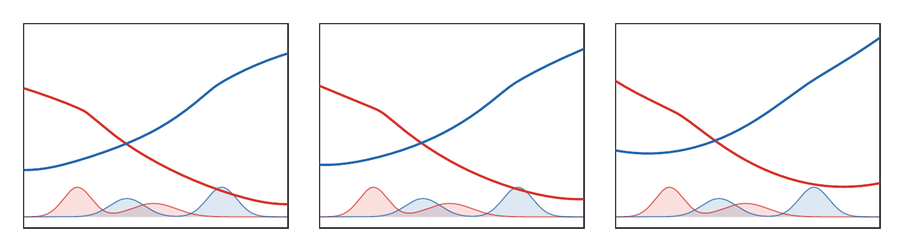
Figure Div shows how the corresponding KL-normalized dual potentials deform with temperature, from nearly hard Kantorovich potentials to smoother log-sum-exp profiles.
KL-normalized Sinkhorn dual potentials for one-dimensional Gaussian-mixture
histograms. For ϵ=0.010 the curves are already close to the
unregularized one-dimensional Kantorovich potentials; increasing ϵ
turns this hard c-transform geometry into smoother log-sum-exp potentials.
Interactive panel. Change ϵ to compare the dual potentials with the
corresponding entropic coupling.
Proof Sketch
For ϵ→0, use compactness of the transport polytope and compare the
optimality inequalities for the entropic problem against an exact
Kantorovich optimizer. The cost gap is bounded by
ϵ times a KL difference, so every cluster point is cost-optimal; after
dividing by ϵ, the cluster point is the KL-minimizer on the optimal
face.
For ϵ→+∞, subtract a constant from C so that C≥0.
Testing the objective at a⊗b gives
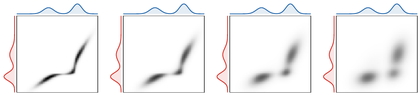
Figure Div illustrates the two limiting regimes established above: the plan approaches a sparse optimal coupling as ϵ↓0 and the product coupling as ϵ grows.
show_book_figure("sinkhorn-plan-epsilon")
Entropically regularized couplings between the red disk and blue annulus
point clouds. The plans are strictly positive for every ϵ>0, but the
visible mass pattern evolves from nearly radial and sparse to diffuse as
ϵ increases.
Interactive panel. Use the same temperature control to see positivity,
diffusion, and sharpening of entropic couplings in a one-dimensional setting.
The continuous formulation replaces matrices by measures and discrete KL by
relative entropy. This section records the measure-theoretic problem, explains
how the temperature ϵ connects exact transport to the independent
product coupling, and states the two asymptotic regimes that are useful later:
a large-temperature expansion around independence and a small-temperature
expansion around quadratic optimal transport.
The only structural change from the discrete problem is that matrix entries are
replaced by densities with respect to a product reference measure. For
probability measures α and β, define
For fixed balanced marginals, the specific product reference only matters up
to additive constants, provided the reference marginals are mutually
absolutely continuous with α and β. Its support still matters: it
determines which couplings have finite entropy.
Large ϵ favors nearly independent endpoints, while small ϵ
suppresses endpoint randomness and recovers an optimal Monge--Kantorovich
coupling in the limit. When the unregularized quadratic problem has a Brenier
map, this limiting coupling is deterministic.
Given v(ℓ), the first update produces an intermediate coupling with
X-marginal α; the second produces one with Y-marginal β, while
generally perturbing the first marginal again. The scalings retain the gauge
(u,v)↦(λu,v/λ).
There is one useful situation in which no iteration is required: choose the
target by applying the normalized Gibbs kernel itself to the source.
Proof
By construction, pϵ(x,⋅)dβ0 is a probability measure.
Fubini’s theorem therefore shows that
(31) has first marginal α and second
marginal βϵ.
Let γ∈Π(α,βϵ) have finite objective. Since
−ϵlogkϵ=c, the displayed density of πϵ gives
The last two terms depend only on the prescribed marginals. Minimizing the
entropic objective is therefore equivalent to minimizing
KL(γ∣πϵ), whose unique minimizer is
γ=πϵ.
If kϵ(x,⋅) is already normalized with respect to β0, then
Zϵ=1 and (30) reduces to
Equivalently, the closed-form coupling is the law of
(X,X+ϵ/2G) for independent X∼α and
G∼N(0,Id). Time-indexed Gaussian blurrings are the forward
noising mechanism behind diffusion models, with an additional deterministic
rescaling for variance-preserving Ornstein--Uhlenbeck schedules; see
Connection with diffusion models..
For discrete measures, setting ui=aiu(xi) and
vj=bjv(yj) gives
Pi,j=aibju(xi)Ki,jv(yj)=uiKi,jvj, so the functional
iteration reduces exactly to the matrix Sinkhorn iteration
(8). Its logarithmic interpretation as continuous dual block
ascent is derived in Dual Sinkhorn for General Measures. Continuous
convergence is revisited through a generalized Fortet-type monotonicity argument
in Section Sinkhorn Convergence: Monotone Point of View; the finite-dimensional linear rate is
studied through Hilbert’s metric in Section Sinkhorn Convergence: Linear Hilbert Metric Rate.
The continuous problem has the same qualitative temperature limits as the
finite-dimensional problem, but the zero-temperature selection is subtler. For
quadratic transport between smooth densities, the limiting OT plan is typically
supported on a graph and is therefore singular with respect to
α⊗β. Thus the robust statement is weak convergence of
minimizers. This is the standard Γ-convergence mechanism for entropic
OT Léonard, 2012Carlier et al., 2017; the density hypothesis
below isolates the only approximation point needed in the proof.
The proof is the standard Γ-convergence argument: the entropy is
nonnegative, finite-entropy couplings provide recovery sequences, and
Pinsker’s inequality from Theorem Theorem: Pinsker Inequality turns the
large-ϵ entropy bound into total-variation convergence.
When ϵ is large, the entropy dominates and the optimal plan is a small
perturbation of the product coupling. The useful object is the part of the cost
that cannot be absorbed into row and column potentials. Let
r=α⊗β and define
The coefficient c0 has zero conditional means. The second-order term follows
by expanding the constrained exponential tilt and using this conditional
orthogonality.
At small temperature, entropic transport is a viscous perturbation of quadratic
optimal transport. The expansion contains an ϵlogϵ term from
the Gaussian normalization of Brownian bridges, an endpoint entropy correction,
and a Fisher-information term along the McCann interpolation. The formula below
translates the small-noise Schrödinger expansion to the convention
∥x−y∥2+ϵKL(⋅∣α⊗β)Conforti & Tamanini, 2021Chizat et al., 2020.
The Brownian entropy used in the proof is relative to the sigma-finite
endpoint measure pT(x,y)dxdy, and therefore uses
H(π∣ξ)=∫log(dπ/dξ)dπ rather than the
finite-measure generalized KL above. This distinction is what fixes the
Gaussian normalization and the ϵlogϵ coefficient.
The dual point of view replaces couplings by potentials and soft
c-transforms. It is the right formulation for stabilized implementations
and differentiation.
Exponentiating the alternating soft-transform iterations recovers Sinkhorn’s
algorithm. For small ϵ, one must compute the log-sum-exp terms with
the usual stabilization trick: subtract the minimum before exponentiating and
add it back afterward.
Figure Div visualizes the corresponding soft minimum: decreasing ϵ sharpens the smooth best response toward the hard c-transform envelope.
After integration, this is exactly Dϵ(f,g), proving weak
duality. Fenchel--Rockafellar entropy duality gives equality: the strictly
positive feasible density r≡1 supplies the qualification point, and
c is bounded on the compact product. Continuity of c allows the supremum
to be restricted to continuous potentials, since the soft transforms turn
bounded potentials into continuous ones without lowering the dual value.
At primal--dual optimality, equality in the Fenchel inequality forces
r⋆ to be the unique pointwise minimizer. Its first-order condition is
ϵlogr⋆+c−f⋆−g⋆=0, which gives the displayed density
formula after exponentiation.
This is the smooth counterpart of the hard feasibility constraint
f⊕g≤c from the Kantorovich dual.
Proof Sketch
Normalize potentials by imposing ∫fdα=0. Replacing a pair of
potentials by the corresponding soft transforms does not decrease the dual
objective. The transformed potentials have oscillations bounded by the
oscillation of c, and their modulus of continuity is controlled by the
modulus of continuity of c. Arzela--Ascoli gives existence.
Uniqueness on the supports, up to constants, follows from strict convexity of
H↦∫eH/ϵd(α⊗β) on the image of
(f,g)↦f⊕g−c, modulo constants.
The soft transforms are not only regularized analogues of hard
c-transforms: they are the exact block-maximization steps of the continuous
dual objective (53). Indeed, for fixed g and
h∈C(X),
The transforms are those of Definition
Definition: Continuous Soft c-Transforms. Their decorations record their
domains: the cˉ-transform sends a potential on Y to one on X,
whereas the c-transform sends a potential on X to one on Y.
This dual iteration is exactly the logarithmic form of the continuous scaling
iteration (27). Set
u(ℓ)=ef(ℓ)/ϵ and
v(ℓ)=eg(ℓ)/ϵ. Exponentiating the dual updates and using
the kernel operators (24) gives
The coupling density reconstructed from the current potentials is therefore
u(ℓ)(x)kϵ(x,y)v(ℓ)(y) with respect to
α⊗β, as in (25). At a fixed
point, its two marginals are α and β; equivalently, the potentials
jointly maximize the continuous dual.
The convex-potential structure above suggests a sample-based alternative to evaluating soft transforms on a grid or on all pairs of samples. For the bilinear cost c(x,y)=−⟨x,y⟩, the signs of the dual potentials are convex: writing Φ=−f and Ψ=−g, the zero-temperature constraint f(x)+g(y)≤−⟨x,y⟩ becomes
For the quadratic cost this is the same statement after subtracting the quadratic terms. One can therefore maximize the continuous dual over parameterized convex potentials, estimating the integrals by stochastic samples.
A useful parameterization is given by input-convex neural networks (ICNNs) Amos et al., 2017Makkuva et al., 2020. The construction mirrors elementary closure rules for convex functions: nonnegative linear combinations preserve convexity, composition with a convex nondecreasing scalar nonlinearity preserves convexity, and the ReLU r↦max(r,0) is both convex and nondecreasing. Thus a feed-forward network with nonnegative hidden-to-hidden weights and affine skip connections from the input defines a convex function of its input. This gives a flexible cone of convex trial potentials, although the finite-dimensional optimization over the network weights is not a convex optimization problem. Universal-approximation statements must be read with this distinction in mind: max-affine functions are dense among continuous convex functions on compact convex sets, and ICNN-type architectures are designed to inherit this approximation principle. General ReLU universal approximation results, such as the width d+1 theorem on compact subsets of RdHanin, 2019, provide useful background but do not by themselves enforce convexity. In practice, neural dual solvers trade exact Sinkhorn scaling for amortized stochastic optimization of the dual potentials.
The path-space meaning of the static Schrodinger problem now follows the dual construction. A noisy reference dynamics first defines a probability law on trajectories; after optimizing out the conditional law of the path given its endpoints, only the endpoint coupling remains.
Schrodinger’s reciprocal problem is naturally posed on paths rather than on
endpoint pairs. The Sinkhorn problem appears after the path law is reduced to
its two endpoint marginals.
Let Rϵ∈P(Ω) be a reference path law, for instance a
Brownian or Langevin dynamics at noise level ϵ. The dynamic
Schrodinger bridge problem is the entropy projection
It asks for the most likely path law, relative to the prior dynamics, among
all path laws matching the observed endpoints
Schrödinger, 1931Léonard, 2012Léonard, 2014Chen et al., 2016.
so that the generator is (ϵ/2)Δ. Under the standard
finite-entropy assumptions, a path law M with the same initial marginal and
M≪Rϵ can be represented, in the weak sense, by an adapted drift
ut of finite energy,
Conversely, such a drift defines an absolutely continuous change of law when
the usual Girsanov integrability conditions hold. Girsanov’s formula then gives
If the reference initial law is not α, an additional term
ϵKL(α∣R0ϵ) appears, but it is fixed by
the endpoint constraint. Hence, up to this fixed endpoint cost, the Schrodinger bridge can be read as
Thus the bridge is the least energetic change of drift that steers the
Brownian prior from α to β. The optimizer may be chosen Markovian.
If ht denotes the positive space-time harmonic Schrodinger factor associated
with the terminal constraint, then the optimal feedback drift has the
Doob-transform form
Equivalently, with the value potential ϕt=ϵloght, one has
ut⋆=∇ϕt and ϕt solves the viscous Hamilton--Jacobi
equation
∂tϕt+21∥∇ϕt∥2+2ϵΔϕt=0.
This control viewpoint and the endpoint-coupling reduction below are two faces
of the same object: the controlled diffusion describes the whole path law,
whereas the static Sinkhorn coupling records only its two endpoints.
The dynamic problem also has viscous Benamou--Brenier formulations. Here
vt denotes the forward drift called ut in the control formulation,
whereas ut denotes the associated current velocity. If the uncontrolled
noise is σdBt, its generator is (σ/2)Δ and
For the convention dXt=ϵdBt, the endpoint kernel is
exp(−∥x−y∥2/(2ϵ)) and the corresponding static cost is
∥x−y∥2/2. Renaming the static temperature gives the equivalent kernel
After rewriting this prior with respect to α⊗β, the endpoint
problem is exactly the continuous Sinkhorn problem up to an additive constant.
Sinkhorn computes which endpoints should be paired; the path-space
Schrodinger bridge then connects each pair by a Brownian bridge.
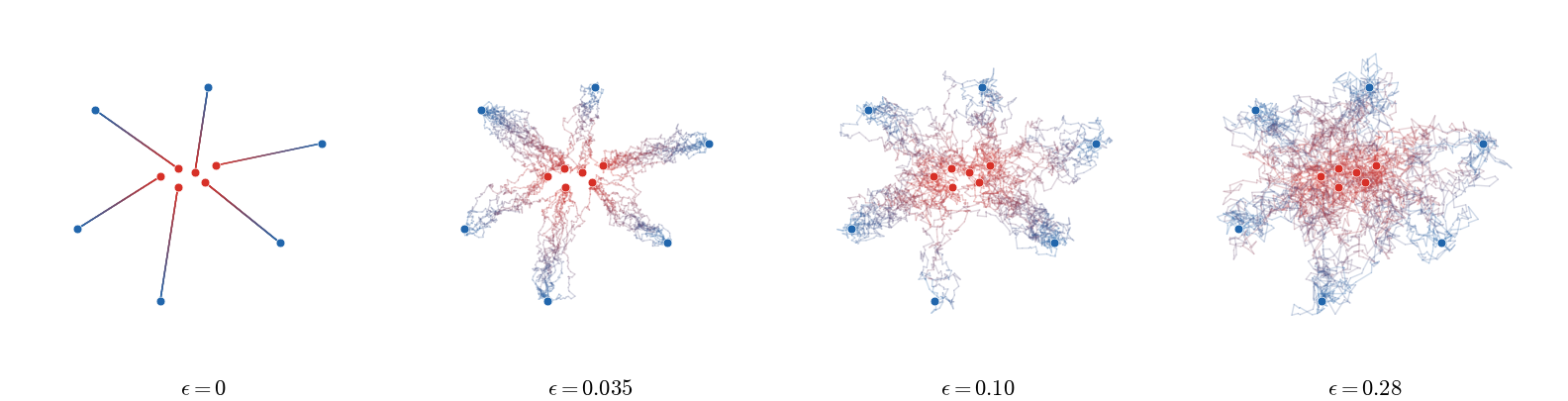
Figure Div illustrates this endpoint-to-path lifting on a small discrete example.
show_book_figure("sinkhorn-path-space-bridges")
Endpoint couplings lifted to Brownian bridges. Increasing ϵ both
softens the endpoint coupling and amplifies the Brownian fluctuations between
paired endpoints.
Interactive panel. Vary ϵ to move continuously from straight OT
rays to noisy Brownian-bridge lifts with a more diffuse endpoint coupling.
The balanced Sinkhorn problem fixes both marginals exactly. Many nearby models
instead optimize the transported marginals, but only through penalties or
constraints applied separately to each marginal. The useful point, emphasized by
the generalized scaling algorithms of Chizat, Peyré, Schmitzer and Vialard
Chizat et al., 2018, is that entropic OT remains a diagonal-scaling
problem whenever these marginal terms admit simple KL-proximal maps.
Let F and G be proper convex lower semicontinuous
functionals on finite nonnegative measures on X and Y. The
unregularized marginal-dependent transport problem is
where α and β are reference measures. In this subsection, when the
total mass of π is not fixed, the KL term is understood in the generalized
sense associated with φ(s)=slogs−s+1. Thus, if
λ=α⊗β and π=ρλ+π⊥ is the Lebesgue
decomposition of π with respect to λ, then
with value +∞ when π⊥=0. On probability couplings this
coincides with the usual relative entropy.
Balanced OT is recovered by taking F=ι{α} and
G=ι{β}. Unbalanced OT replaces these hard indicators by
marginal divergences, as developed later in Section Unbalanced OT. An
entropic JKO step fixes the first marginal to the previous iterate and puts the
energy on the second marginal, for instance
F=ι{αt} and G=E, with cost c/(2τ);
this is the static counterpart of the minimizing-movement schemes of Chapter
Paragraph. Barycenters are the multi-coupling
extension: several couplings share one unknown marginal and are treated by the
generalized Sinkhorn updates of Section OT Barycenters.
In finite dimension, with reference weights satisfying ai,bj>0 and proper
convex functions
F:R+n→R∪{+∞},
G:R+m→R∪{+∞}, the entropic version becomes
Equivalently, if Kij=aibje−Cij/ϵ, the terms involving
C can be absorbed into the Gibbs reference and the problem is, up to the
additive constant ϵ∑i,j(aibj−Kij),
Introduce independent variables r and s for the two marginals and use dual
variables f,g for the constraints r=P1m and
s=P⊤1n. The Lagrangian contains
Minimizing over r and s gives −F∗(−f) and
−G∗(−g). For each scalar entry, the convex conjugate of
p↦Cijp+ϵ(plog(p/(aibj))−p+aibj) is
q↦ϵaibj(e(q−Cij)/ϵ−1). Minimizing over P
with q=fi+gj gives the displayed dual.
For the scaling form, fix v>0, set
K=Kdiag(v) and
z=K1m=Kv. Updating the row scaling means looking
for P=diag(u)K, so its row marginal is
r=P1m=u⊙z. The row-wise chain rule gives
Thus exact optimization of this block is equivalent to minimizing
F(r)+ϵKL(r∣z) over r≥0, hence
r=proxF/ϵKL(z) and
u=r⊘z. The column update is identical with
w=K⊤u.
When F=ι{a} and G=ι{b}, the first two
dual terms are ⟨f,a⟩+⟨g,b⟩, and one
recovers the usual entropic dual. The classical Sinkhorn update is the special
case in which the KL proximal maps return the prescribed marginals a and
b.
The usefulness of this formulation is that many KL-proximal maps are explicit.
Hard marginal constraint. If F=ι{a}, then
proxF/ϵKL(z)=a.
KL marginal relaxation. If F(r)=τKL(r∣a) with τ>0,
then, coordinatewise,
Fixed total mass. If F=ι{⟨r,1⟩=m},
then
proxF/ϵKL(z)=mz/⟨z,1⟩.
These examples explain why generalized Sinkhorn algorithms remain practical:
the expensive operation is still multiplication by K or K⊤, while the
model-specific part is a low-dimensional KL-proximal update on a marginal.
The Gaussian kernel used by Sinkhorn is also the Euclidean heat kernel. This
viewpoint clarifies when entropic OT admits fast grid and surface
implementations, and it places soft minima and Hopf--Cole transforms in the
same heat-kernel calculus.
The scalar factor is absorbed by the Sinkhorn scalings and does not change the
coupling. On a Riemannian manifold or surface M, write
L=−ΔM and replace the dense Gibbs matrix by the intrinsic heat operator
Hϵ=e−(ϵ/4)L. For two histograms on the same discretized
domain, Sinkhorn becomes
Here Hϵ includes quadrature weights and Hϵ⊤ is its
discrete adjoint; they coincide for a symmetric mass-normalized
discretization. This fits Sinkhorn because kernel multiplication is its only expensive step.
Equivalently, the heat kernel defines the effective cost
cϵ(x,y)=−ϵloghϵ/4(x,y). Varadhan’s formula gives
so convolutional Sinkhorn recovers the squared geodesic ground cost at small
temperature without computing all pairwise geodesic distances
Varadhan, 1967Solomon et al., 2015. This is also the asymptotic
principle behind geodesics-in-heat distance estimation Crane et al., 2013.
Computationally, the heat operator admits the resolvent approximation
For a sparse discrete Laplacian Lh, factor
Aϵ,q=I+ϵLh/(4q)=RR⊤ once by sparse Cholesky. Each
application of Hϵ is then approximated by q successive solves with
Aϵ,q, each reduced to two triangular substitutions. The same
factorization is reused in every Sinkhorn row and column update, avoiding a
dense kernel and an all-pairs distance matrix
Solomon et al., 2015. An ϵ-scaling schedule requires one factorization per
temperature. The diffusion length is of order ϵ, so the
small-temperature limit must still be resolved by the mesh; taking ϵ
smaller than the squared grid spacing produces metrication and discretization
artifacts.
Figure Div compares the exact distance to a non-convex source curve with heat-kernel and shifted-Laplacian approximations at several smoothing scales.
show_book_figure("sinkhorn-geodesics-in-heat")
Geodesics-in-heat approximation of the distance to a dense non-convex source
curve. The one-step approximation (I+ϵLh/4)−1 with Neumann
boundary conditions is followed by a normalized-gradient Poisson solve. Larger
Sinkhorn temperatures suppress unresolved grid-scale artifacts but progressively round the
non-convex level-set geometry.
Interactive panel. Adjust the Sinkhorn temperature ϵ and number of sources to see how heat smoothing rounds Voronoi fronts and approximate distance level sets.
The sign only reflects the convention of Definition: c-Transform. This is the
usual Hopf--Lax formula for the Hamiltonian ∥p∥2/2Evans, 2010Villani, 2009; other quadratic scalings amount to multiplying
the cost by a constant. In the present entropic setting, the parameter of
interest is instead the temperature ϵ.
The soft version replaces the infimum by a log-sum-exp soft minimum. In the
notation of Definition: Continuous Soft c-Transforms, and using Lebesgue measure
on Rd,
This is a soft c-transform of the function −h, and Laplace’s principle gives
(−h)cˉ,ϵ→(−h)cˉ as ϵ→0 under the usual
compactness assumptions on near-minimizers. The same formula is also a
heat-kernel formula. If
Thus a soft quadratic c-transform is a Gaussian convolution followed by a
logarithm, up to an explicit additive constant independent of x. This is the
bridge between soft-minimum operators, heat kernels and entropic transport
potentials.
this shift turns the Legendre--Fenchel transform into a quadratic
cˉ-transform. Replacing the hard transform by its soft version gives the
definition of f∗,ϵ. Expanding the square yields the log-sum-exp
formula, the Gaussian-convolution expression follows from the normalized kernel
Gϵ, and the convergence follows from Laplace’s principle.
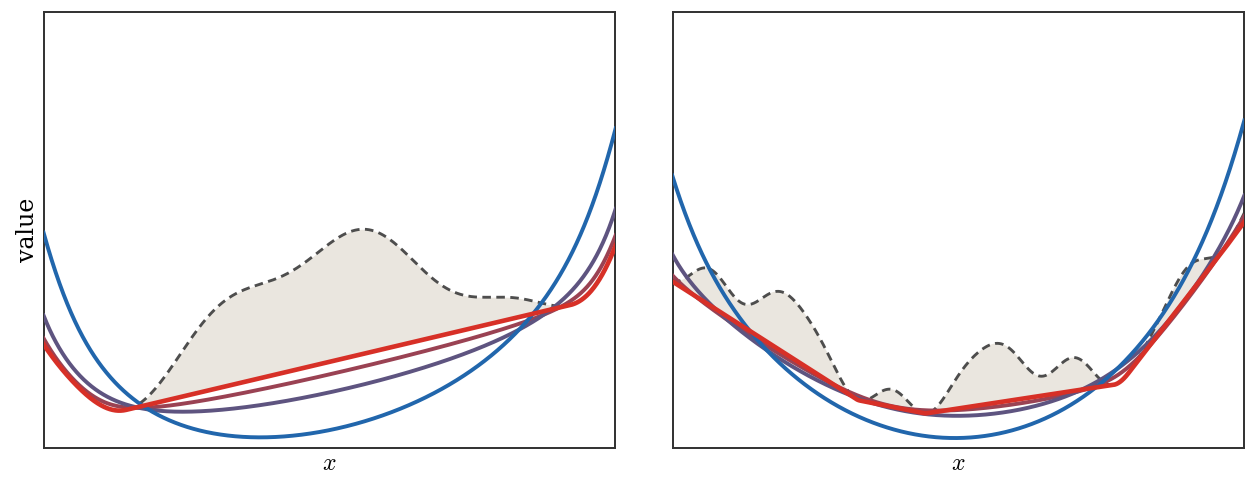
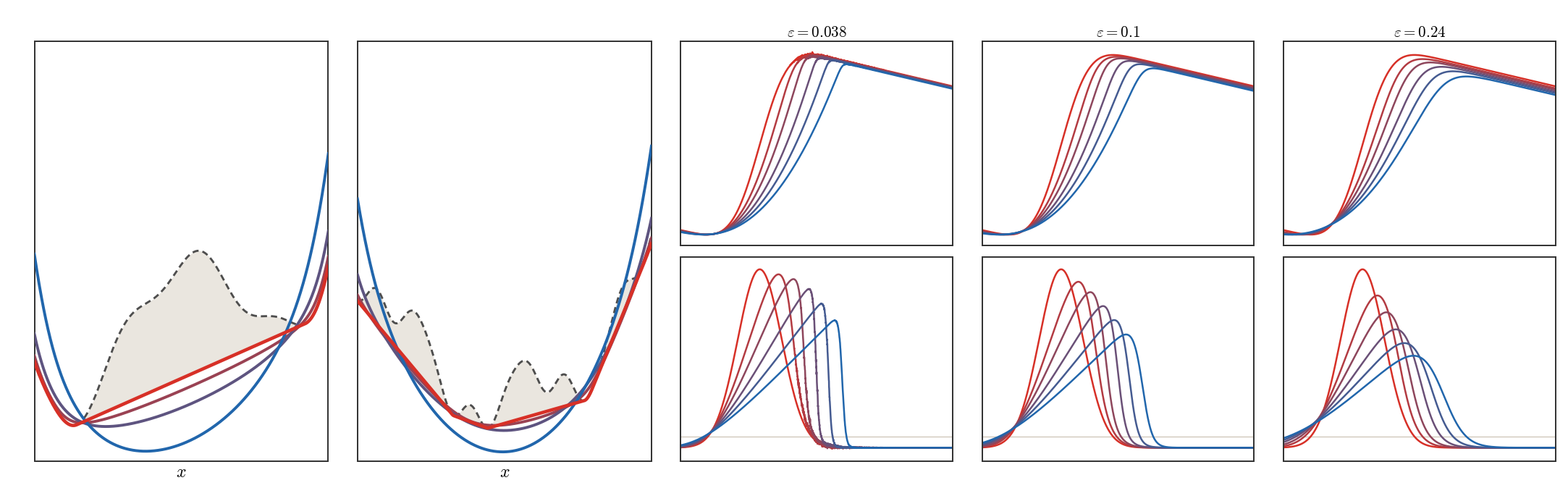
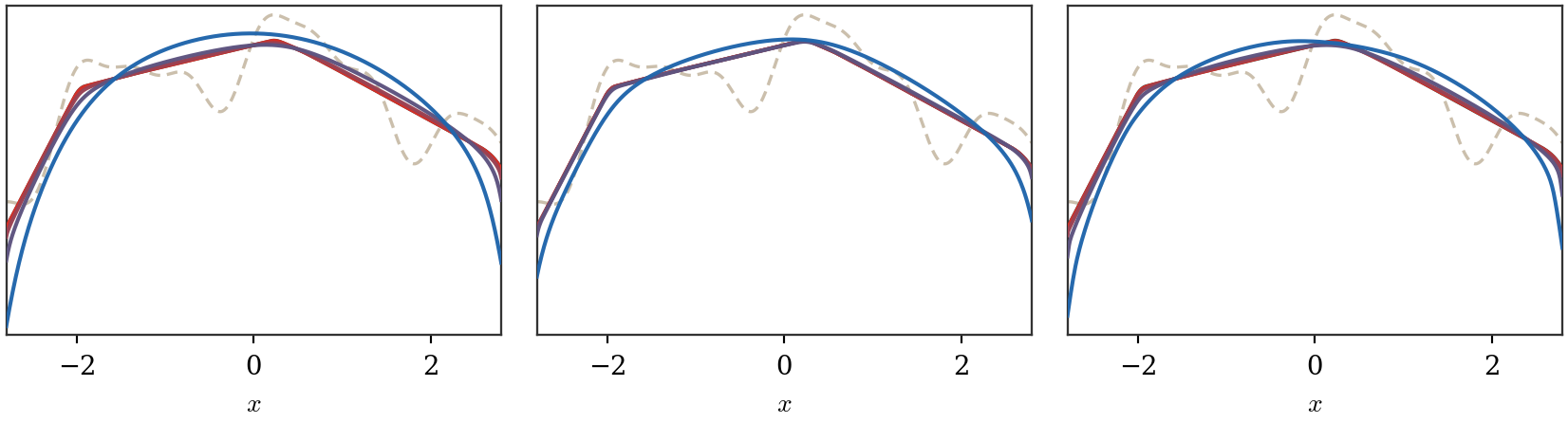
The first figure below isolates the biconjugation effect. It compares the hard
lower convex envelope with finite-temperature soft biconjugates for both a simple
and a more oscillatory non-convex profile.
Figure Div illustrates the biconjugation viewpoint directly.
Soft Legendre biconjugates as approximations of lower convex envelopes. The dashed gray curve is the original non-convex function, the red curve is f∗∗, and the purple-to-blue curves show (f∗,ϵ)∗,ϵ for increasing ϵ.
Interactive panel. Change the smoothing temperature to see how the soft
c-transform interpolates between hard envelopes and smooth log-sum-exp
transforms.
The nonlinear PDEs are linearized by the Hopf--Cole transform. With the same
temperature normalization, us=e−ϕs/ϵ converts
into ∂sus=(ϵ/2)Δus. Conversely,
ϕs=−ϵlogus gives a Hamilton--Jacobi solution, while
vs=∇ϕs=−ϵ∇logus solves the gradient viscous Burgers
equation ∂svs+(vs⋅∇)vs=(ϵ/2)Δvs. In one
dimension this is the classical Cole--Hopf transform; in higher dimension this
scalar reduction applies to irrotational velocity fields.
The figure below keeps only the PDE content: the same initial potential is
evolved through the Hopf--Cole transform for three values of the viscosity.
Figure Div starts from a Gaussian velocity bump, whose inviscid evolution would form a shock on its decreasing flank, and shows how the viscosity parameter ϵ/2 regularizes this steepening.
Hopf--Cole numerics for viscous Hamilton--Jacobi and Burgers dynamics. The upper row shows the potentials ϕt, the lower row shows the velocities vt=∂xϕt, and colors encode time from red to blue.
Interactive panel. Change the viscosity, final time and initial velocity
bump to see the same Hopf--Cole mechanism: heat evolves the transformed
variable, while the logarithm reconstructs the Hamilton--Jacobi potential and
the Burgers velocity.
KL regularization is the case that leads to multiplicative Sinkhorn scalings.
Replacing KL by another density-ratio penalty keeps the same transport
constraints but changes the scalar law linking the optimal density to the
dual potentials.
The previous construction regularizes OT by a density-ratio divergence. This
differs from using a Bregman divergence generated by a convex functional on
the space of measures.
With the product reference ξ=α⊗β, the corresponding
regularized transport value is
Dualizing the marginal constraints and minimizing over π produces the
global conjugate Φ∗. Equality in Fenchel’s inequality gives the
Bregman optimality condition.
The primal--dual relations
(118) and
(113) make the distinction precise.
Bregman regularization translates the reference measure in the functional
dual coordinate δΦ, whereas ϕ-divergence regularization applies
the scalar derivative ϕ′ pointwise to the density relative to
α⊗β. For KL these laws coincide: logarithmic dual coordinates
turn additive potential shifts into multiplicative density scalings.
Thus the two generalizations lead to different duals and different
algorithms. Only for KL do density-ratio regularization and Bregman
projection geometry coincide and reduce to multiplicative Sinkhorn scalings.
Generalized Soft c-Transforms and Alternate Dual Maximization Method¶
The two dual formulations above suggest the same basic optimizer: maximize
exactly over one potential while the other is fixed, then exchange their
roles. For the ϕ-divergence dual, separability with respect to
α⊗β makes both block updates pointwise:
and the second satisfies the symmetric equation. Thus each update normalizes
one conditional density. For Burg or quadratic penalties, the solve remains
one-dimensional and monotone, but it is no longer a log-sum-exp.
The Bregman dual has analogous block transforms, but they are function-space
minimizations unless Φ is separable. With
ξ=α⊗β, define
These are precisely the exact block minimizers of the negative Bregman dual.
For separable Φ, disintegration reduces them to independent scalar
problems.
The two alternate dual-maximization schemes are therefore
For KL, which has both descriptions, these iterations coincide with the
usual soft c-transform iteration and recover Sinkhorn.
Quadratic regularizers replace exponentiation by positive-part thresholding.
For discrete measures, the choices
ϕ(r)=21(r−1)2 and
Φ(P)=21∥P∥F2 give, respectively,
The left-hand side is continuous, nondecreasing, and piecewise affine.
Sorting its breakpoints, equivalently computing a weighted simplex
projection, costs O(mlogm) for a row of length m. The unweighted
quadratic Bregman transform is an ordinary Euclidean simplex projection.
Figures Div and
Div show the two
visible consequences: changing the regularizer modifies both the smoothing
of the dual envelope and the support of the primal coupling.
Generalized soft double transforms for c(x,y)=−xy. The dashed curve is the
same non-concave input potential in all panels, the dark curve is the hard
double c-transform after centering, and colored curves show the centered
double transform (fc,ϵ,ϕ)cˉ,ϵ,ϕ for increasing
ϵ from red to blue. KL, Burg, and quadratic density-ratio penalties
smooth the concave envelope differently.
Density-ratio regularizers and coupling support. KL gives a diffuse positive
plan, the Burg barrier keeps positive but differently tailed support, and the
rightmost quadratic plan is computed by alternate threshold transforms and
is exactly sparse through the positive-part law.
The interactive demo separates the same two effects. The left plot shows the
pointwise law r=h(s), while the right plot recomputes a coupling after
enforcing the marginals with that law.
Interactive panel. Compare entropic and quadratic penalties on the same transport problem by changing the regularizer and its strength.
Sinkhorn divergences remove the entropic self-bias while retaining
smoothness. They interpolate between OT-like geometry and kernel-like norms,
which explains their statistical behavior.
The raw Sinkhorn cost is biased: for ϵ>0, minimizing
Lcϵ(α,β) over β does not generally return
β=α. In the large-temperature limit, the raw value behaves like a
product interaction:
For c(x,y)=∥x−y∥2, minimizing this large-temperature limit over
β collapses toward a Dirac at the mean of α.
The standard debiasing subtracts the two self-interaction energies.
This cancellation removes the large-temperature attraction toward the
independent coupling; positivity is a separate property, proved below through
the positive-definite kernel associated with e−c/ϵ.
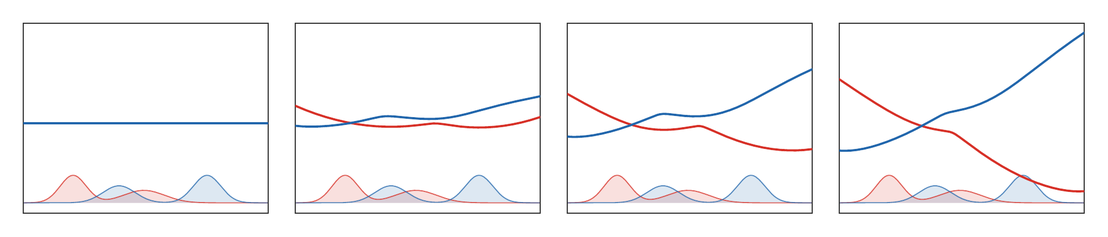
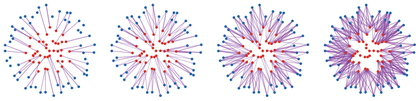
Figure Div demonstrates the role of the two self-cost corrections by optimizing a finite point cloud against a fixed target with and without debiasing.
show_book_figure("sinkhorn-divergence-debiasing")
Debiasing by point optimization. For large ϵ, minimizing the raw
entropic cost collapses atoms toward the barycenter, whereas the self-cost
subtraction keeps a bimodal cloud.
The interactive demo below shows the same mechanism with two-dimensional point
clouds. The raw entropic loss tends to keep the fitted cloud too concentrated,
whereas the self-cost correction spreads the moving particles across the target
geometry.
Interactive panel. Use the smoothing, correction, and iteration controls to compare raw entropic attraction with the debiased Sinkhorn divergence.
for α-almost every x. Therefore the exponential penalty term in the
dual integrates to zero, and the dual value reduces to the two linear
potential terms.
The zero-temperature statement is the Γ-convergence of entropic OT to
the Kantorovich problem Léonard, 2012Carlier et al., 2017.
Non-negativity of relative entropy and continuity of c give the liminf
inequality; a finite-entropy approximation of an optimal coupling, chosen so
that its entropy multiplied by ϵ vanishes, gives a recovery sequence.
Proof Sketch
Use the optimal self-potentials for (α,α) and (β,β) as
a suboptimal pair in the dual problem between α and β. After
rewriting with
α~=efα,α/ϵα and
β~=efβ,β/ϵβ, one obtains
The self Sinkhorn fixed-point equations imply
∥α~∥kϵ=∥∥β~∥∥kϵ=1, so
Cauchy--Schwarz for the kernel pairing gives the result.
If the divergence vanishes and the kernel is universal, equality in
Cauchy--Schwarz gives identical kernel mean embeddings for α~ and
β~, hence α~=β~. The self-consistency equations
then recover the same original measure from this common weighted measure.
Positive semidefiniteness without universality guarantees only non-negativity
and may leave a nontrivial null space.
The Sinkhorn temperature is usually a positive real number: positivity makes
the Gibbs kernel positive, gives the entropy a convex meaning, and underlies
the Hilbert-metric and monotone convergence arguments of the next chapter.
Once the equations are written as exponential fixed-point equations, however,
ϵ can also be regarded locally as a complex variable. This does not
produce a positive coupling or a contraction theorem; it produces a
holomorphic branch of the same scaling equations near any positive real
temperature.
Let α∈P(X) and β∈P(Y). For
ϵ∈C∖{0}, reuse the Gibbs kernel and integral
operators in (24) whenever the defining
integrals exist. The density factorization
(25), the marginal equations that follow it,
and the updates (27) then remain valid
verbatim for complex-valued u and v, provided that the divisions are well
defined. For real ϵ>0 these are the usual Sinkhorn equations. For
complex ϵ they are only local analytic identities: they imply neither
positivity of πϵ nor convergence of the alternating iteration.
For discrete histograms, evaluate the Gibbs kernel entrywise at (xi,yj).
The factorization (4) and Sinkhorn updates
(8) are then used verbatim over C, with the same
marginal constraints and multiplicative gauge, whenever ϵ=0 and all
divisions are defined. This complexified iteration is again a local
parametrization of the scaling equations, not a globally convergent algorithm.
The following finite-dimensional result is the scaling-variable counterpart of
Theorem 2.1 and Remark 2.2 of
Carlier et al., 2023. For compactly supported
marginals and a continuous cost, Carlier, Pegon and Tamanini prove through the
Schrödinger system that the normalized potentials, and hence the entropic
cost, depend analytically on every real ϵ>0; their remark explicitly
records the resulting local extension to complex temperatures. We state the
discrete version directly in (u,v) and also allow the marginals and cost
matrix to vary.
Proof
Apply the holomorphic implicit-function theorem to the n row residuals, the
first m−1 column residuals, and the gauge residual
G(u)=∑iai0(ui−ui0). There are n+m equations for the n+m
scaling coordinates. Let (δu,δv) belong to the kernel of their
derivative at the positive real base point and set
The linearized row sums vanish; the first m−1 column sums vanish by
definition, and the last column sum follows from equality of the total row and
column sums. Hence
Strict positivity gives ri=θ and sj=−θ. The linearized gauge
then gives 0=θ∑iai0ui0, hence θ=0. The derivative is
invertible, and the holomorphic implicit-function theorem gives the local
branch.
After shrinking the neighborhoods if necessary, every scaling coordinate is
nonzero. Choosing local logarithms defines the holomorphic log-scalings
fϵ=ϵloguϵ and
gϵ=ϵlogvϵ. They are useful for visualization but
are not needed in the theorem.
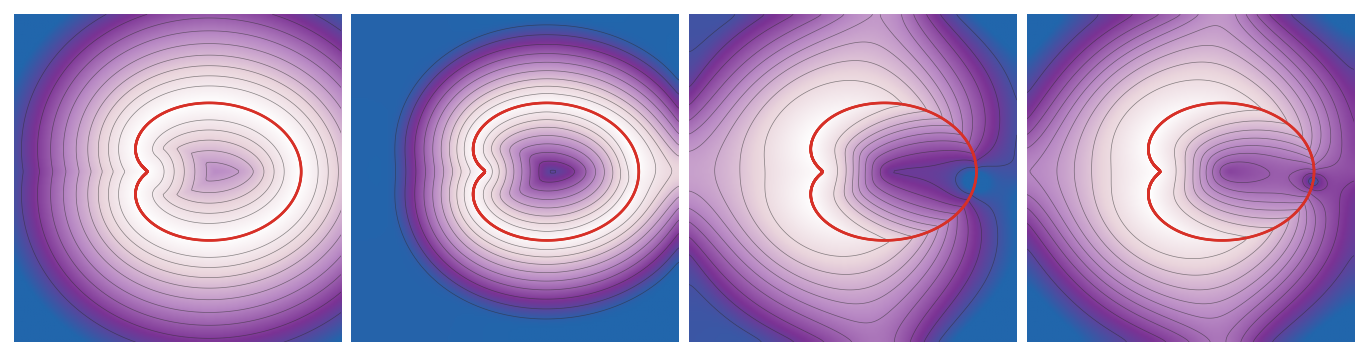
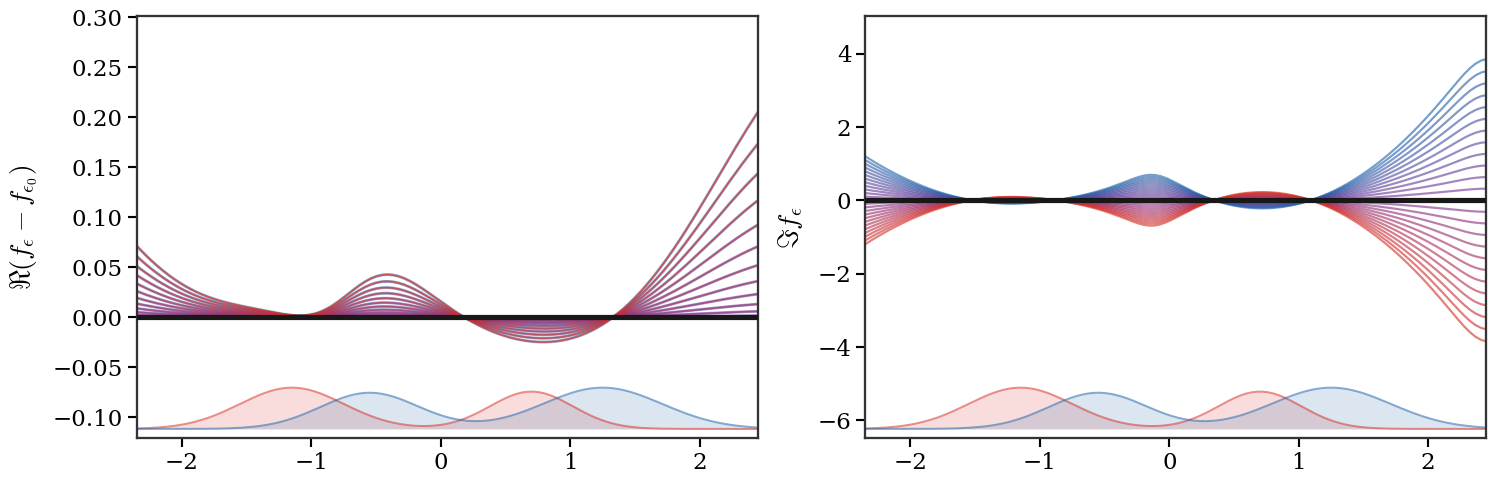
Figure Div visualizes the local
continuation at the level of the coupling, without choosing logarithm branches.
For a fixed real part ϵ0, it displays
∣Pϵ0+iη∣ at four increasing imaginary parts. The complex
matrix Pϵ0+iη retains the prescribed marginals (a,b), but
taking its entrywise modulus destroys these linear identities. The attached
red and blue profiles therefore show (a,b), while the violet profiles show
the row and column sums of ∣Pϵ0+iη∣ and reveal the
cancellations hidden by the modulus.
The magnitude of a complex Sinkhorn coupling exposes the oscillations created
by an imaginary temperature. Two Gaussian-mixture histograms and
ϵ0=0.55 are fixed, while ϵ=ϵ0+iη is continued
through η∈{0,0.20,0.40,0.60}. Every panel uses the same intensity
scale. The red and blue profiles are the prescribed marginals of the complex
coupling; the violet profiles are the marginals of its entrywise modulus and
separate from them as cancellation increases.
Interactive panel. Vary the real and imaginary parts of the temperature to
inspect ∣Pϵ0+iη∣. The side profiles distinguish the prescribed
marginals of the complex matrix from the marginals obtained after taking its
entrywise modulus.
Sinkhorn, R. (1964). A relationship between arbitrary positive matrices and doubly stochastic matrices. The Annals of Mathematical Statistics, 35(2), 876–879. 10.1214/aoms/1177703591
Sinkhorn, R., & Knopp, P. (1967). Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics, 21(2), 343–348. 10.2140/pjm.1967.21.343
Sinkhorn, R. (1967). Diagonal equivalence to matrices with prescribed row and column sums. American Mathematical Monthly, 74, 402–405.
Cuturi, M. (2013). Sinkhorn distances: lightspeed computation of optimal transport. Advances in Neural Information Processing Systems 26, 2292–2300.
Peyré, G., & Cuturi, M. (2019). Computational Optimal Transport: With Applications to Data Science. Foundations and Trends in Machine Learning, 11(5–6), 355–607. 10.1561/2200000073
Nesterov, Y., & Nemirovskii, A. (1994). Interior-point polynomial algorithms in convex programming (Vol. 13). SIAM.
Altschuler, J., Weed, J., & Rigollet, P. (2017). Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration. Advances in Neural Information Processing Systems, 30, 1964–1974.
Dvurechensky, P., Gasnikov, A., & Kroshnin, A. (2018). Computational Optimal Transport: Complexity by Accelerated Gradient Descent Is Better Than by Sinkhorn’s Algorithm. In J. Dy & A. Krause (Eds.), Proceedings of the 35th International Conference on Machine Learning (Vol. 80, pp. 1367–1376). PMLR.
Knight, P. A. (2008). The Sinkhorn–Knopp algorithm: convergence and applications. SIAM Journal on Matrix Analysis and Applications, 30(1), 261–275. 10.1137/060659624
Léonard, C. (2012). From the Schrödinger problem to the Monge–Kantorovich problem. Journal of Functional Analysis, 262(4), 1879–1920.
Carlier, G., Duval, V., Peyré, G., & Schmitzer, B. (2017). Convergence of entropic schemes for optimal transport and gradient flows. SIAM Journal on Mathematical Analysis, 49(2), 1385–1418.
Conforti, G., & Tamanini, L. (2021). A formula for the time derivative of the entropic cost and applications. Journal of Functional Analysis, 280(11), 108964. 10.1016/j.jfa.2021.108964
Chizat, L., Roussillon, P., Léger, F., Vialard, F.-X., & Peyré, G. (2020). Faster Wasserstein Distance Estimation with the Sinkhorn Divergence. Advances in Neural Information Processing Systems, 33, 2257–2269.
Nutz, M., & Wiesel, J. (2022). Entropic Optimal Transport: Convergence of Potentials. Probability Theory and Related Fields, 184, 401–424. 10.1007/s00440-021-01096-8
Amos, B., Xu, L., & Kolter, J. Z. (2017). Input Convex Neural Networks. Proceedings of the 34th International Conference on Machine Learning, 70, 146–155.