Kantorovich’s relaxation is the decisive move that turns transport into convex
optimization. Deterministic maps are replaced by couplings, infeasibility and
asymmetry disappear, and the Wasserstein distances emerge. Historically, this
linear-programming viewpoint grew from Kantorovich’s economic planning work
Kantorovich, 1942 and is now the standard foundation of optimal transport
Villani, 2003Villani, 2009Rachev & Rüschendorf, 1998.
from pathlib import Path
import sys
from IPython.display import Image as DisplayImage
from IPython.display import display
here = Path.cwd()
myst_dir = None
for candidate in [here, here.parent, here / "myst", here.parent / "myst", here.parent.parent / "myst"]:
if (candidate / "ot4ml_web.py").exists():
myst_dir = candidate.resolve()
sys.path.insert(0, str(myst_dir))
break
if myst_dir is None:
raise RuntimeError("Could not locate myst/ot4ml_web.py")
repo_root = myst_dir.parent
thumbnails = repo_root / "notebooks-figures" / "thumbnails"
def show_book_figure(name, width=760):
display(DisplayImage(filename=str(thumbnails / f"{name}.png"), width=width))
from ot4ml_web import plot_regularization_sweep
The discrete relaxation is the cleanest place to see mass splitting. It
replaces permutations by a transportation polytope and reveals the
linear-programming structure that algorithms exploit.
Monge’s discrete matching problem cannot be applied when the two clouds have
different cardinalities or unequal weights. The continuous Monge problem has
the same obstruction: there may be no map T such that T♯α=β,
for instance when one Dirac mass must be sent to several Dirac masses. It is
also asymmetric: two Dirac masses can be mapped to one, but one Dirac mass
cannot be split into two by a deterministic map.
Kantorovich’s idea is to relax deterministic transportation. Instead of sending
each source point xi to exactly one target, the mass at xi may be
dispatched across several targets. The relaxation is encoded by a coupling
matrix P∈R+n×m for two discrete measures
The first consequence is feasibility. There is always at least one admissible
plan.
The feasible set is a bounded intersection of an affine space with the
nonnegative orthant, hence a convex polytope. In one dimension, the coupling
can be read as a matrix: rows index source bins, columns index target bins, and
the marginal constraints appear as prescribed row and column sums.
Proof
The reverse implication is immediate. Conversely, assume that a⊗b is
optimal and let Q∈U(a,b) be arbitrary. Since all entries of
a⊗b are positive, there exists t>0 small enough that
Taking scalar products with C, the optimality of a⊗b forces both
R and Q to have the same cost as a⊗b. Since Q was arbitrary, all
couplings are optimal.
Thus the product plan is mainly a feasibility witness. Except when the linear
cost is constant on the whole transportation polytope, it is not expected to
solve optimal transport.
Figure Div contrasts deterministic, product and optimal couplings through weighted transport segments.
Discrete couplings represented as straight transport segments. The
deterministic graph is a feasible Monge-type plan, the product plan spreads
every source mass over all targets, and the optimal Kantorovich plan minimizes
the quadratic transport cost. Line width and opacity encode transported mass.
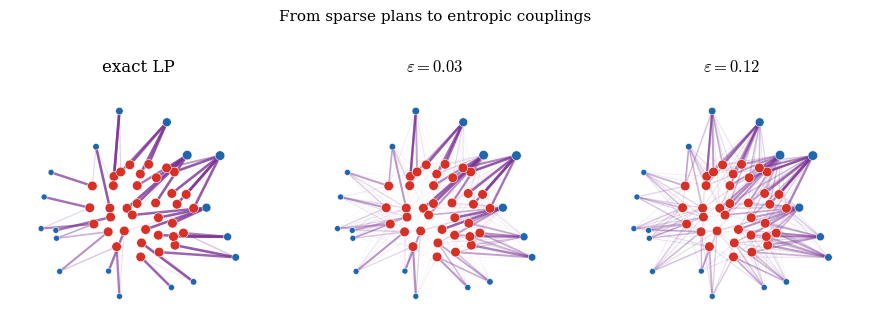
The interactive demo below separates the main feasible-plan archetypes: deterministic
graphs, independent product couplings, sparse splitting plans, and entropic
approximations.
Interactive panel. Use the point and mass sliders to see how a Kantorovich plan can split mass into several weighted links rather than choosing one destination per source.
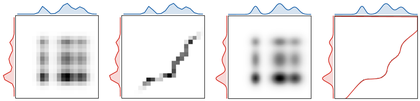
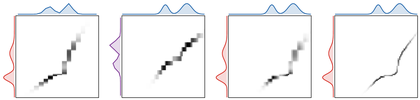
Figure Div gives the complementary matrix view and displays the prescribed marginals next to each coupling.
Coupling matrices with their prescribed marginals. The central grayscale image
displays Pij; the red curve on the left is the source marginal a, and
the blue curve on top is the target marginal b. The independent product plan
is diffuse, whereas the one-dimensional optimal plan concentrates near the
monotone quantile correspondence.
The companion control varies the bin count and the endpoint laws, making the
transition from diffuse independence to monotone transport visually explicit.
Interactive panel. Use the problem-size and mass-shape controls to compare the coupling matrix with its red and blue marginal sums.
The Kantorovich feasible set is symmetric: P∈U(a,b) if and only
if P⊤∈U(b,a). With a unit transport cost matrix
Cij, the discrete Kantorovich problem reads
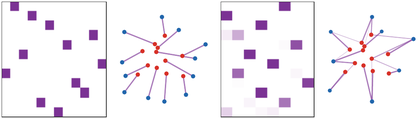
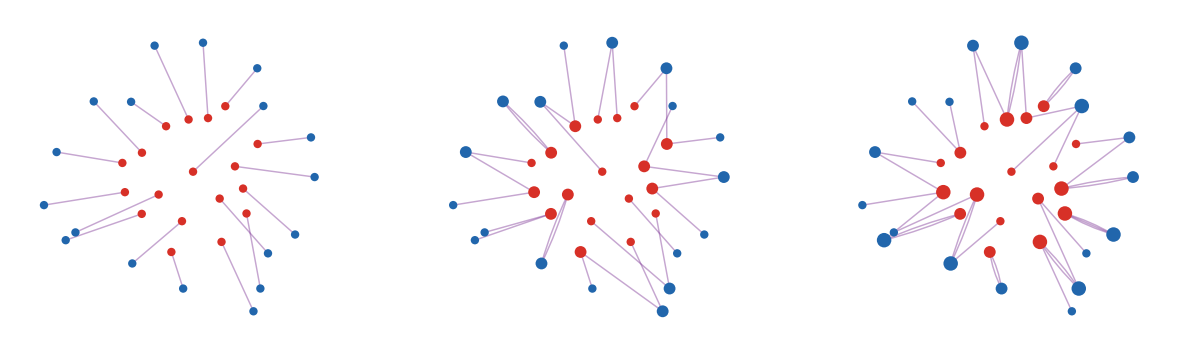
From permutation matrices to splitting couplings. When the two empirical
measures have the same number of atoms and uniform weights, an optimal plan can
be a permutation matrix. Once target masses are nonuniform, one source can send
mass to several targets and several sources can merge into the same target.
The interactive demo keeps the same source and target sites while changing the target
mass imbalance, so the moment where permutation structure breaks becomes
visible.
Interactive panel. Use the split-mass and geometry controls to contrast deterministic permutation-like transport with plans that divide source mass across targets.
Sparsity here is not peculiar to transport. For nonnegative variables, the
relevant quantity is the rank of the constraint operator, not the raw number
of listed constraints, which may contain redundancies. The following standard
linear-programming principle makes this precise.
Proof
The feasible region is a nonempty polyhedron, so the attainment theorem for
linear programs gives a minimizer. Among all minimizers, choose P⋆ with
minimal support S. If #S>rank(A), rank-nullity
gives a nonzero matrix H supported on S with A(H)=0. Both
P⋆+tH and P⋆−tH are nonnegative for sufficiently small t>0,
and all their constraint values agree with those of P⋆. Optimality
therefore forces ⟨C,H⟩=0.
Choose σ∈{−1,1} so that σH has a negative entry, and set
Then P⋆+t⋆σH is feasible and optimal. At least one positive
entry has vanished, and no entry outside S has appeared, contradicting the
minimality of S.
Proof
Apply the rank-controlled proposition to the marginal operator
Amarg(P)=(P1m,P⊤1n). It has rank
n+m−1: equality of total row and column mass gives one relation. Conversely,
if (u,v) annihilates its image, testing the identity on each elementary
matrix gives ui+vj=0 for every (i,j). Thus all ui equal one scalar and
all vj equal its opposite, so this is the only relation. The preceding
proposition therefore supplies an optimal coupling with at most n+m−1
positive entries.
For transportation polytopes, the same kernel argument has a graph
interpretation: a cycle in the bipartite support carries an alternating
perturbation with zero row and column sums. Thus every extreme coupling has a
forest support.
Proof
All assignments are nonnegative. At each step, the mass placed in entry (i,j)
is subtracted from exactly one current row residual and one current column
residual, so no row or column can receive more mass than prescribed. Conversely,
an index is advanced only when its residual has been fully filled. When the
algorithm stops, the total assigned mass is ∑iai=∑jbj, hence all
row and column sums are exactly a and b.
Each positive assignment exhausts at least one current row or one current
column. Before the final assignment, at most n−1 row advances and m−1 column
advances can occur without terminating the construction. Hence the number of
positive entries is at most (n−1)+(m−1)+1=n+m−1. For acyclicity, view the
positive support as a bipartite graph. Once a row or column index is advanced,
it never appears again, so each new positive edge either starts a new component
or attaches at least one new vertex to the component currently being swept. No
edge is ever added between two old vertices of the same component, so no cycle
can be created.
The north-west corner rule, summarized in Algorithm
Algorithm: North-west corner coupling, does not use the cost matrix and is therefore not
meant to solve the discrete Kantorovich problem. Its role is algorithmic: an
acyclic support corresponds to linearly independent marginal constraints. When
the support has fewer than n+m−1 positive entries, transportation simplex
implementations complete it with zero-mass basic variables to obtain a
degenerate basic feasible solution. This gives a cheap initialization for the
pivoting methods discussed in Section Linear-Programming Algorithms.
In one dimension, the transportation polytope has a canonical monotone
optimizer. This is the weighted version of the sorting rule from the matching
chapter.
Proof
The Monge inequality for a convex displacement cost states that, whenever
i<i′ and j<j′,
We prove optimality by induction on n+m. Let P be an optimal plan that
maximizes P11. If P11<min(a1,b1), then row 1 sends positive
mass to some j′>1 and column 1 receives positive mass from some i′>1.
Moving the same small amount from (1,j′) and (i′,1) to (1,1) and
(i′,j′) preserves both marginals and, by the displayed inequality, does not
increase the cost. It strictly increases P11, a contradiction. Hence
P11=min(a1,b1), exactly as in the north-west rule. Row 1 or column
1 is exhausted; deleting it leaves the same problem on a smaller ordered
grid. Induction proves that the complete sweep is optimal. Sorting has cost
O(nlogn+mlogm), and the sweep creates at most n+m−1 nonzero entries.
Now assume n=m and uniform weights a=b=1n/n. In this case, a
matching can be encoded as a matrix with exactly one active entry per row and
per column.
The corresponding probability coupling is Pσ/n. If the matching cost
matrix is C, then
Thus the assignment problem is the minimization of a linear function over the
discrete, non-convex set of permutation matrices. The convex relaxation
replaces this finite set by all bistochastic matrices.
Proof
Among all nonempty faces of C, choose one of minimal affine
dimension. If this face contained two distinct points, maximizing a linear
functional that is not constant on the face would produce a nonempty proper
exposed subface, contradicting minimality. Hence the minimal face is a
singleton, and its point is extreme.
Proof
The set S=argminx∈Cℓ(x) is nonempty, compact and convex.
By Proposition Proposition: Existence of Extreme Points, it has an extreme point
x. If x=(y+z)/2 with y,z∈C, then by linearity and optimality
of x, both y and z also minimize ℓ on C, hence
y,z∈S. Since x is extreme in S, y=z=x. Thus x is extreme in
C.
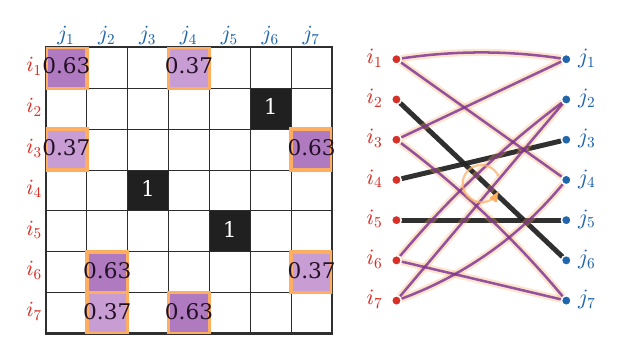
Figure Div shows the non-extreme mechanism
used in the proof below. The displayed matrix is bistochastic but not a
permutation matrix: the unit entries already behave like isolated matching
edges, while the fractional support contains a minimal alternating cycle.
show_book_figure("birkhoff-von-neumann-cycle")
Cycle certificate in the Birkhoff--von Neumann proof. The left panel is a
7×7 bistochastic matrix which is not a permutation matrix. The right
panel shows its bipartite positive-support graph, with the column nodes sorted
as j1,…,j7 from top to bottom to match the matrix order: red nodes are
rows, blue nodes are columns, thin purple edges
correspond to 0<Pij<1, and bold black edges correspond to isolated entries
Pij=1. The orange halo marks the longer alternating fractional cycle along
which one can add and subtract mass while preserving all row and column sums.
Interactive panel. Move mass around the alternating cycle and observe that
all row and column sums remain unchanged.
Proof
We first prove that permutation matrices are extreme. Let
Pσ∈Pnperm and assume that
Every bistochastic matrix has entries in [0,1]. Since the only extreme
points of [0,1] are 0 and 1, each entry of Pσ fixes the
corresponding entries of Q and R: if (Pσ)ij=0, then
Qij=Rij=0, while if (Pσ)ij=1, then Qij=Rij=1.
Hence Q=R=Pσ, so Pσ is extreme.
We now prove the converse by contrapositive. Pick
P∈Bn∖Pnperm. Since an integral
bistochastic matrix is necessarily a permutation matrix, P has at least one
fractional entry. We shall split P=(Q+R)/2 with
Q,R∈Bn and Q=R, proving that P is not extreme.
Associate with P the bipartite graph whose left vertices are the rows, whose
right vertices are the columns, and whose edges are the fractional entries
0<Pij<1. An entry equal to 1 uses the whole mass of its row and column,
so it is isolated in the positive support and does not appear in this fractional
graph. If a left vertex is incident to one fractional edge, then it must be
incident to at least one other fractional edge: after the first fractional
contribution, the row still has positive remaining mass, and that remainder
cannot be carried by an entry equal to 1. The same argument applies to
columns. Thus every non-isolated vertex of the fractional graph has degree at
least two.
Starting from any fractional edge, one may therefore walk through adjacent
fractional edges without immediately backtracking and without getting stuck.
Since the graph is finite, some vertex is eventually visited twice; the portion
of the walk between the two visits contains a cycle. Choose a shortest such
cycle and write it in alternating form
Set Q=P and R=P outside A∪B; on A, set
Qij=Pij+ϵ/2 and Rij=Pij−ϵ/2; on B, set
Qij=Pij−ϵ/2 and Rij=Pij+ϵ/2. By the definition of
ϵ, all modified entries stay in [0,1]. Each row and column of the
cycle sees one +ϵ/2 and one −ϵ/2, so the row and column sums
remain one. Thus Q,R∈Bn, Q=R, and P=(Q+R)/2. Hence P
is not extreme. Consequently every extreme point of Bn is integral,
and every integral bistochastic matrix is a permutation matrix.
The same combinatorial idea gives the constructive decomposition used to
express a bistochastic matrix as a convex combination of permutations.
The perfect matching required at each iteration exists by Hall’s theorem.
Indeed, while the common row and column sum of the residual matrix is s>0,
any set I of row vertices and its neighborhood N(I) satisfy
Thus ∣N(I)∣≥∣I∣, which is Hall’s condition. Subtracting
λPσ preserves a common row and column sum s−λ and
removes at least one positive entry. The algorithm therefore terminates after
finitely many steps with R=0; summing the updates yields the announced
convex decomposition and ∑rλr=1.
Proof
The feasible set is Bn/n. By Proposition
Proposition: Linear Programs Have Extreme Minimizers, the linear objective has an
optimal extreme point. Since scaling preserves extreme points and Theorem
Theorem: Birkhoff--von Neumann identifies the extreme points of
Bn, this optimizer is Pσ/n for some permutation σ.
Its cost is exactly n−1∑iCi,σ(i), so σ is an optimal
assignment.
Equivalently, for uniform empirical measures, one can always choose a
permutation matrix among the minimizers of the relaxed Kantorovich problem: the
relaxation is tight for assignment problems.
The strict assignment model is tied to equal cardinalities and equal weights,
whereas the coupling set Definition: Discrete Couplings And Mass Conservation accommodates arbitrary
discrete masses and different support sizes. Figure
Div contrasts these regimes. For rational
weights, the relaxed problem can in fact be reduced back to a larger uniform
assignment problem.
From assignments to transport plans, using the same disk-to-annulus geometry.
In the balanced equal-weight case, each source atom is matched to one target
atom. With a target cloud that has half as many atoms, or with strongly
nonuniform target weights, the coupling matrix can merge or split mass; segment
thickness and opacity encode its nonzero entries, and blue marker areas encode
the prescribed target masses.
The interactive panel below exposes the target resolution, target weights, and
regularization level. The first displayed plan is sparse, while positive
regularization values show the entropic smoothing used later in the Sinkhorn
chapter.
Interactive panel. Use the source and target sizes, weight pattern, and regularization sliders to see how unequal masses and finite resolution change the matching picture.
Proof
Any assignment between the duplicated source and target clouds defines integers
nij counting how many copied particles of type xi are matched to copied
particles of type yj. These counts satisfy
∑jnij=ki and ∑inij=ℓj, and the associated coupling
Pij=nij/N has marginals ki/N and ℓj/N. The assignment cost is
Conversely, any nonnegative integer count matrix with those row and column sums
can be realized by allocating the ki copies of each xi among the target
copies according to (nij)j. It remains to show that restricting to
integer counts does not increase the optimum. Scale a feasible coupling by
N and write Q=NP. The constraints on Q have integer right-hand sides.
After multiplying the target rows by -1, their coefficient matrix is the
oriented node-edge incidence matrix of a bipartite graph and is therefore
totally unimodular. Every vertex of the transportation polytope is integral,
and a linear objective attains its minimum at a vertex. Thus an integral
optimal Q exists and the two optimal values coincide. This proves existence,
not integrality of every optimizer: convex combinations of distinct integral
optima can be fractional.
This network-flow integrality mechanism is the rational-weight counterpart of
the Birkhoff--von Neumann theorem above (Theorem: Birkhoff--von Neumann): in both cases, a linear
transport relaxation has an optimizer represented by integer edge flows after
scaling. Equal unit margins specialize these flows to permutation matrices,
whereas a degenerate optimal face may also contain fractional couplings.
Figure Div makes this reduction explicit by replacing each rational mass with identical unit copies and then regrouping the resulting uniform assignment.
show_book_figure("matching-rational-duplication")
Rational weights as duplicated uniform matchings, using the same
disk-to-annulus geometry with fewer displayed atoms. The red and blue locations
are kept fixed, while disk areas encode the integer multiplicities ki and
ℓj. Solving the assignment problem after duplicating particles produces
several collapsed segments attached to high-multiplicity atoms; this is the
integer count matrix of the proposition.
Interactive panel. Use the site and multiplicity sliders to see how rational weights can be represented by duplicated unit masses before solving an ordinary matching problem.
Discrete Kantorovich transport applies whenever weighted data points or
histograms must be compared through a geometry-aware correspondence. The
following examples illustrate information transfer between datasets,
comparison of visual distributions, and inference of temporal relations
between cell populations.
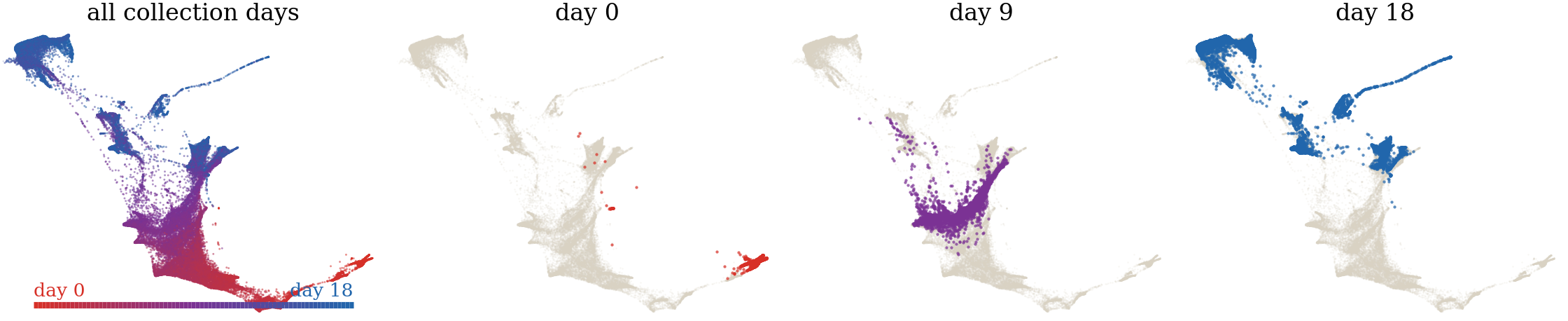
Three snapshots of the Waddington-OT single-cell reprogramming time course.
The first panel aggregates a representative sample from all collection times
and colors cells from red to blue according to time. The remaining panels
highlight the populations observed at days 0, 9, and 18, while cells from
other times remain in gray. Every panel uses the same official force-layout
embedding and viewport; no transport coupling or interpolated trajectory is
displayed.
The discrete Kantorovich problem is a linear program with much more structure
than a generic dense LP. Its variables are arcs of a complete bipartite network,
its equality constraints are flow-conservation constraints, and its extreme
points are sparse tree-like couplings.
The transportation simplex goes back to Dantzig’s formulation of the
transportation problem Dantzig, 1951. It works on basic feasible
couplings, whose support is completed into a spanning tree of the bipartite
supply-demand graph. Reduced costs identify whether an unused arc can decrease
the objective. Adding such an arc creates a unique cycle; one then pushes as
much mass as possible around that cycle and removes the exhausted arc.
The network simplex is the corresponding pivoting method for general
minimum-cost-flow problems Bertsekas & Eckstein, 1988. It keeps node
potentials, reduced costs and a spanning-tree basis. Its worst-case number of
pivots can be exponential, but the per-pivot operations exploit graph sparsity.
Polynomial guarantees can be obtained from strongly polynomial
minimum-cost-flow algorithms such as Orlin’s algorithm Orlin, 1997.
Generic interior-point methods approach the LP through a smooth central path.
Assume here that all entries of a and b are positive; zero-mass rows and
columns must first be removed. The logarithmic-barrier problem on the resulting
transport polytope is
The barrier is singular at the boundary, so each iterate stays strictly inside
the transportation polytope. As ϵ↓0, the central path
approaches the set of LP minimizers.
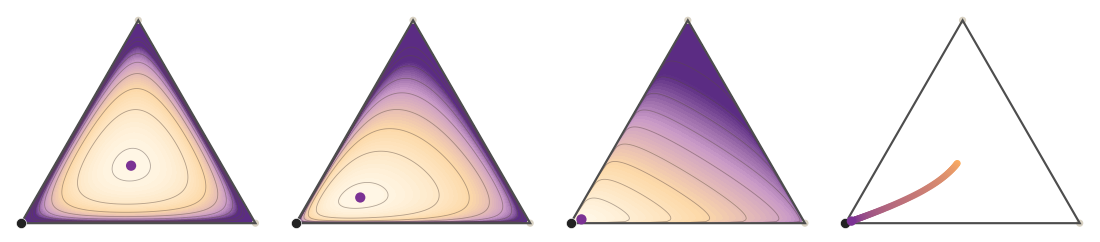
Figure Div isolates this mechanism on a two-dimensional polytope: decreasing the barrier parameter moves the minimizer along the central path toward the optimal face.
Logarithmic-barrier central path for a triangular slice of a linear program.
Large ϵ selects a central interior point; decreasing ϵ moves
the minimizer toward the optimal vertex while never touching the boundary. This
differs from entropic OT, where the entropy temperature is part of the
regularized objective itself.
The interactive view exposes the barrier parameter directly: lowering ϵ
slides the minimizer from the center of the feasible triangle toward the LP
vertex.
Interactive panel. Use the barrier and angle controls to move along the interior central path of the transport polytope.
Both interior-point methods and Sinkhorn keep iterates positive, but they use
positivity differently. Interior-point algorithms solve the original LP by
decreasing a barrier parameter. Sinkhorn fixes an entropic temperature and
solves a different, KL-regularized OT problem by alternating diagonal scalings.
This section lifts the finite-dimensional coupling matrix to a joint
probability measure. The payoff is that existence, duality and metric
properties can be stated for arbitrary laws, including discrete, singular and
continuous distributions.
Unlike the Monge constraint, the coupling constraint is never empty. The
continuous feasibility witness is the tensor product coupling.
The next result echoes Proposition
Proposition: Discrete Product Optimality Is Degenerate in the continuous setting. In
both cases, the independent coupling is optimal precisely when the objective is
flat over the whole admissible set; for continuous costs, this flatness is
equivalently the additive form c(x,y)=u(x)+v(y) on the product support.
Proof Sketch
If all couplings are optimal, the product coupling is optimal. Conversely,
assume the product is optimal. If cross differences failed to vanish on the
product support, there would be points x0,x1,y0,y1 such that exchanging
the two target neighborhoods decreases cost. Replacing a small amount of
product mass on the two diagonal rectangles by mass on the crossed rectangles
keeps the same marginals and lowers the cost, a contradiction. Vanishing cross
differences imply
c(x,y)=c(x,y⋆)+c(x⋆,y)−c(x⋆,y⋆) on the support, so the
cost of any coupling depends only on its marginals.
The tensor product is therefore a trivial feasible coupling, not a typical
optimizer. The continuity assumption matters: changing a cost on an
α⊗β-negligible set can change the cost of singular couplings while
leaving the product cost unchanged.
If there exists a map T:X→Y with T♯α=β, then the Monge map
induces the graph coupling π=(Id,T)♯α∈Π(α,β),
characterized by
Graph couplings are precisely the Kantorovich representation of deterministic
Monge maps.
A last important class consists of semi-discrete problems, where α has a
density and β is discrete. Every coupling is supported on the union of the
slices X×{yj}. When an optimal coupling is induced by a map, these
slices are selected by a partition of X into transport cells, as developed
in Chapter Paragraph.
This is an infinite-dimensional linear program over a space of measures.
The linear formulation gives the Kantorovich value opposite curvature
properties in its two kinds of arguments: it is convex in the marginals but
concave in the ground cost.
Proof
For joint convexity, let (α0,β0) and (α1,β1) be two
pairs of probability measures. The claim is immediate at t∈{0,1} or if
one of the two values on the right-hand side is infinite. Otherwise, for
η>0, choose πi∈Π(αi,βi) such that
Taking the infimum over π proves the stated inequality.
Proof
The constraint set is nonempty because it contains α⊗β. It is
uniformly tight: for ε>0, choose compact sets
KX⊂X and KY⊂Y with
α(KX),β(KY)≥1−ε/2. Every feasible π then
satisfies π(KX×KY)≥1−ε. Prokhorov’s theorem
gives relative weak compactness. The marginal constraints are weakly closed
because the coordinate projections are continuous, so the feasible set is
weakly compact. Finally, Portmanteau’s theorem makes
π↦∫cdπ weakly lower semicontinuous. The direct method gives a
minimizer.
For the Wasserstein cost c(x,y)=d(x,y)p on a Polish metric space, the
natural finite-valued domain is
for one, and hence every, reference point x0. If
α,β∈Pp(X), the product coupling has finite p-cost by the
triangle inequality, and the proposition supplies an optimal coupling.
The proof of Brenier’s theorem relies on Kantorovich relaxation and duality.
Under Brenier’s hypotheses, the relaxation is tight: it has the same cost as
the Monge problem and the optimal coupling is induced by a map.
Proof
The proof of Brenier’s theorem shows that the support of any optimal
Kantorovich plan lies in the subdifferential ∂ϕ of a convex
function. Since α has a density, ϕ is differentiable
α-almost everywhere, so ∂ϕ(x)={∇ϕ(x)} for
α-almost every x. Every optimal coupling is therefore concentrated on the
graph of T=∇ϕ and equals (Id,T)♯α.
If α does not have a density, non-smooth points of ϕ can be charged by
α and mass splitting can occur. For instance, moving δ0 to
(δ−1+δ1)/2 can be represented by a plan concentrated on the
set-valued subdifferential of ϕ(x)=∣x∣, but not by a deterministic map.
The atomless assumption in the Monge statement of Section
One-Dimensional Transport And Quantiles is a limitation of maps, not of
one-dimensional optimality. Once couplings are allowed, atoms can be split by
assigning subintervals of quantile levels to different target points. The common
quantile parameter therefore defines an optimal relaxed coupling for arbitrary
probability measures.
Proof
The push-forward statement π⋆∈Π(α,β) follows from the
quantile push-forward proposition. It remains to prove optimality.
The key point is the one-dimensional uncrossing inequality. If x<x′ and
y>y′, set a=x−y, δ=x′−x>0 and η=y−y′>0. Convexity of h implies
that increments are monotone, hence
Thus removing a crossing never increases the cost. For a finite transport
matrix on two ordered grids, if i<i′ and j>j′ carry crossed masses
Pij and Pi′j′, move θ=min(Pij,Pi′j′) units from the
crossed entries (i,j), (i′,j′) to the uncrossed entries (i,j′), (i′,j).
The marginals are unchanged, and the cost does not increase. Repeating this
elementary step yields an ordered plan; on an ordered uniform quantile grid,
this is the diagonal plan.
For general measures, lift any coupling to quantile coordinates. Let
π∈Π(α,β). Using regular conditional laws of a uniform
quantile variable given its image under qα and qβ, construct a
coupling γ of two uniform variables such that
π=(qα,qβ)♯γ.
To justify the approximation, let
κM(r)=max(−M,min(r,M)) and set
qα,M=κM∘qα and qβ,M=κM∘qβ.
Approximate these bounded nondecreasing functions almost everywhere by
nondecreasing step functions, constant on the uniform intervals
Ik=((k−1)/N,k/N]. The matrix
GkℓN=γ(Ik×Iℓ) couples two uniform histograms.
Proposition Proposition: One-Dimensional Weighted Sweep applied to the ordered step values
therefore yields the desired comparison for the step functions. For fixed
M, continuity of h on [−2M,2M] allows passage to the limit as
N→∞.
Finally, κM is nondecreasing and 1-Lipschitz, so for every x,y
there is tM(x,y)∈[0,1] such that
κM(x)−κM(y)=tM(x,y)(x−y). Convexity and nonnegativity give
The assumed integrability controls the diagonal term; for a competitor of
finite cost the same bound controls the other term, while an infinite-cost
competitor is irrelevant. Dominated convergence as M→∞ gives
This result is strictly more flexible than the Monge formula. If α has an
atom, a map can only send that whole atom to one target point, whereas the
quantile interval associated with the atom can be coupled with a nontrivial
portion of β. The one-dimensional Kantorovich solution therefore handles
mass splitting without changing the monotone geometry.
Cyclical monotonicity is the local geometric fingerprint of optimality for a
cost c. It converts a global minimization problem into finite exchange
inequalities and is the bridge from Kantorovich plans to convex potentials.
The support of a coupling is the topological support introduced in Definition
Definition: Support Of A Measure, now applied to a Radon measure on X×Y. Thus
(x,y)∈supp(π) exactly when every open neighborhood of (x,y) has
positive π-mass.
For uniform marginals on the same number of atoms, Corollary Corollary: Kantorovich For Matching gives an optimal permutation plan. Its support must be c-cyclically monotone: otherwise exchanging finitely many targets along a violating cycle would lower the matching cost. The next theorem says that the same finite-exchange certificate holds for arbitrary optimal plans.
Proof Sketch
Suppose a finite family in supp(π) violates the exchange inequality. By
continuity, the same strict inequality holds in small neighborhoods
Ui×Vi around the chosen pairs. Write
mi=π(Ui×Vi)>0 and choose
0<λ≤(∑imi−1)−1. The scaled restrictions
πi=λπ∣Ui×Vi/mi have common mass λ and satisfy
∑iπi≤π, even when the rectangles overlap. If αi and
βi are their marginals, replace ∑iπi by
∑iαi⊗βσ(i)/λ. The new measure has the same
marginals, while the uniform strict inequality makes its cost strictly
smaller, contradicting optimality.
If the optimal plan is induced by a map T, there is a set G of full
α-measure such that (x,T(x))∈supp(π) for every x∈G. For
x1,…,xk∈G, cyclical monotonicity reads
In one dimension, for c(x,y)=∣x−y∣p, the two-point inequality has a strict
uncrossing consequence when p>1: if x<y, every optimal map satisfies
T(x)≤T(y) on its full-measure transport set. For p=1, uncrossing is
not strict. The monotone rearrangement remains optimal, but nonmonotone maps
and nondeterministic plans can also be optimal, as in Remark
Remark: Book-shifting as a flat Kantorovich face.
The discrete gluing lemma is the finite-dimensional mechanism behind the triangle inequality.
Proof
If bj>0, summing Sijk over k gives
Pijbj/bj=Pij; if bj=0, the corresponding column of P and row of
Q are zero. The other prescribed marginal is checked in the same way. Summing
over the intermediate index j gives R. Its row and column sums are
a and c.
Figure Div displays this construction in matrix form.
Discrete gluing lemma in matrix form. The first two panels are optimal
one-dimensional couplings through an intermediate marginal. The third panel
shows the induced marginal R=Pdiag(1/b)Q; it is feasible and is the coupling
used in the triangle-inequality proof.
The interactive version changes the resolution of the intermediate marginal, which
controls how mediated the glued source-target plan becomes.
Interactive panel. Use the mediation slider to inspect how two couplings through an intermediate marginal glue into a source-target plan.
Proof
Symmetry follows by transposing couplings. Positivity follows because a zero
cost plan must be supported on the diagonal. For the triangle inequality, take
optimal couplings P from a to b and Q from b to c, glue them into
S, and use the feasible marginal R from a to c. Then Minkowski’s
inequality and the ground triangle inequality give
This is the measure-theoretic version of the discrete formula above.
Proof
Symmetry is obtained by swapping the coordinates of a coupling. If the value is
zero, an optimal coupling is supported on the diagonal and therefore the two
marginals coincide. For the triangle inequality, glue optimal couplings
π∈Π(α,β) and ξ∈Π(β,γ) into
σ, project it to a coupling ρ between α and γ, and apply
the ground triangle inequality plus Minkowski:
The quadratic Wasserstein distance does not only compare two endpoint
measures. An optimal plan also says how to move mass between them: each active
pair (x,y) travels along the segment joining x to y. This turns an
optimal coupling into a curve of measures.
In the discrete case, each mass Pij moves from xi to yj along its
own segment. When the optimal plan is not induced by a map, one source atom can
split into several moving atoms. If the optimal plan is not unique, different
optimal plans may also induce different W2 geodesics.
Proof
Push the optimal plan π⋆ forward by (es,et). This gives a
coupling γs,t∈Π(αs,αt), and
All inequalities are therefore equalities, in particular the middle segment
has the claimed length.
Figure Div visualizes the construction when the optimal plan splits mass, so that the intermediate measure is obtained by moving every coupled pair along its Euclidean segment.
McCann interpolation induced by a non-deterministic optimal transport plan. In
every panel, the red and blue endpoint measures are shown with low opacity,
thin gray segments display the support Pij>tol of the coupling,
and the moving atoms are colored from red to blue along the interpolation.
The companion panel lets the same coupling be inspected along time t, with an
entropy slider to contrast sparse and diffuse plans.
Interactive panel. Use the interpolation time and plan controls to see how a fixed coupling induces a cloud of displacement paths between endpoint measures.
The distance Wp defined through the Kantorovich problem
(64) should be contrasted with the directed distance
W obtained using Monge’s problem. The Kantorovich feasible
set is never empty, since it contains the product coupling, although the
p-cost may still be infinite without moment assumptions on non-compact
spaces. By contrast, Monge’s constraint set
{T:T♯α=β} can be empty. When an optimal Monge map exists,
Kantorovich gives the same value by choosing the graph coupling
(Id,T)♯α.
The next proposition makes precise one important sense in which Kantorovich is
the relaxation of Monge. The cleanest statement is first made in the lifted
plan variable π: deterministic graph couplings are dense among all couplings
when the source can be split at arbitrarily fine scales. Thus the Kantorovich
functional is the weak lower-semicontinuous envelope of the Monge graph
functional.
This is an equality of infimal values: the Kantorovich minimum is attained,
whereas the infimum defining W~p need not be attained by a
transport map.
Proof
Let π∈Π(α,β). Choose finite Borel partitions
(Ai)i and (Bj)j of X with mesh at most ϵ, and set
mij=π(Ai×Bj). Since α is atomless and
∑jmij=α(Ai), split each Ai into pieces Aij with
α(Aij)=mij. For mij>0, Proposition
Proposition: Existence Of Transport Maps From Atomless Sources gives a measurable map from
Aij to Bj sending α∣Aij/mij to
β∣Bj/β(Bj). Pasting these maps gives T♯α=β, and the
graph coupling (Id,T)♯α has the same masses as π on all
rectangles Ai×Bj.
Uniform continuity of every test function on the compact product implies that
these graph couplings converge weakly to π as the mesh goes to zero.
Applying this to the continuous cost dp gives convergence of costs.
Therefore any weakly lower-semicontinuous minorant of the graph functional is
bounded above by Fp along the approximating graph couplings, while Fp
itself is continuous and below the graph functional. This proves the envelope
claim and then the equality of infima.
Since Fp is affine in the plan variable and Π(α,β) is convex,
this envelope is also the closed convex relaxation of the Monge graph problem in
the space of transport plans.
At the level of endpoint measures, this gives a literal
lower-semicontinuous-envelope interpretation for the Monge p-cost whenever
source measures can be regularized into atomless ones.
Proof
For every admissible map T, the graph plan (Id,T)♯α is a coupling,
hence Wp(α,β)p≤Wp(α,β)p. Since
Wpp is continuous in the product Wp topology, it is a
lower-semicontinuous minorant of the extended Monge cost.
Conversely, let H be any lower-semicontinuous minorant of the extended Monge
cost. Fix (α,β) and choose atomless αk→α in Wp. By
Proposition Proposition: Kantorovich As The Plan-Space Relaxation Of Monge,
Wp(αk,β)p=Wp(αk,β)p. Therefore
H(α,β)≤liminfkH(αk,β)≤limkWp(αk,β)p=Wp(α,β)p. Thus no larger
lower-semicontinuous minorant exists.
The extra density assumption in the corollary is essential. If α has atoms,
the graph-density statement can fail dramatically: a single source Dirac mass
cannot be mapped to two target Dirac masses. On finite spaces, the topology is
discrete and this obstruction cannot be removed by closure. In such cases the
Kantorovich formulation is not merely a closure of existing maps with the same
marginals; it genuinely adds the possibility of splitting atomic mass.
Representing structured data as probability measures turns the Wasserstein
distance into a geometry-aware comparison tool. The following are two
representative application domains: single-cell biology and natural-language
processing.
Wasserstein distances metrize weak convergence under moment control, sit
between weak and strong topologies, and provide quantitative estimates in
probability and robust optimization.
Proof
The left inequality is Jensen’s inequality applied to r↦rq/p. The
right inequality follows from
d(x,y)q≤diam(X)q−pd(x,y)p.
On compact spaces this is also the weak-* topology inherited from the duality
between continuous functions and finite measures. On noncompact spaces,
“narrow convergence” avoids conflating this probability topology with other
weak-* topologies.
The total variation norm induces the strong topology on measures. For a signed
difference, ∥α−β∥TV=∣α−β∣(X); this is an L1 norm for
densities and an ℓ1 norm for discrete weights. The following proposition
shows that total variation is itself a transport cost for the degenerate 0/1
ground metric.
Proof
Let λ=α+β, write a=dα/dλ and
b=dβ/dλ, and define the common part η by
dη/dλ=min(a,b). The residual measures
α′=α−η and β′=β−η are mutually singular and have common
mass
The diagonal submeasure of any coupling is bounded by both marginals, hence by
η. Every coupling therefore has off-diagonal mass, and thus 0/1 cost,
at least r. If r=0, the diagonal coupling is optimal. If r>0, the
coupling
Probability theory gives weak convergence its most direct interpretation: it
compares distributions rather than samplewise realizations. In terms of random
vectors, if Xn∼αn and X∼α (not necessarily defined on the same
probability space), then αn⇀α means precisely that Xn
converges in law to X.
Convergence in law should be distinguished from stronger notions that compare
random variables on a common probability space. In that setting, Xn→X
almost surely means pointwise convergence outside a null set, while convergence
in probability means
Almost-sure convergence implies convergence in probability, which in turn
implies convergence in law. The last notion depends only on the marginal laws,
since it is exactly the weak convergence
(Xn)♯P⇀X♯P, and therefore does not require a
common probability space.
Convergence in law should also be distinguished from strong convergence of
measures. Total variation convergence controls the mass assigned to every
measurable set, not only averages against continuous test functions, and
therefore implies weak convergence. The converse fails, notably for empirical
approximations of continuous laws.
Limit theorems produce canonical convergent sequences of probability measures,
and Wasserstein distances turn their qualitative conclusions into metric error
bounds. The central limit theorem concerns sums of independent random
variables; because sums of independent variables correspond to convolutions of
their laws, the following statement introduces convolution before expressing
the theorem in transport language.
Figure Div makes this qualitative weak
convergence visible in the elementary Bernoulli case: every finite-n law is
discrete, yet the normalized atom heights approach the Gaussian density.
show_book_figure("matching-quantitative-clt")
Central-limit theorem for normalized Bernoulli sums. Starting from
α0=21(δ−1+δ1), the law of
Zn=n−1/2∑iXi remains discrete, but its rescaled atom heights
approach the standard Gaussian density shown in gray. Proposition
Proposition: Berry--Esseen bound in W1 later quantifies this weak convergence in
W1.
The interactive version varies the number of summands and the Bernoulli skew,
making weak convergence visible even while every displayed law remains
discrete.
Interactive panel. Use the number-of-summands and Bernoulli-skew controls to watch the Wasserstein CLT scaling predicted by Lipschitz test functions.
Thus the strong topology never sees Diracs converge unless they are eventually
equal, while the Wasserstein topology captures their spatial convergence. On
an unbounded space, weak convergence alone does not prevent a vanishing amount
of mass from escaping to infinity; Wasserstein convergence also controls the
corresponding moment tail.
Proof
If Wp(αk,α)→0, then W1≤Wp gives weak convergence.
For every coupling of αk and α, the reverse triangle inequality in
Lp bounds the difference between the rooted p-th moments by the coupling
cost; minimizing proves moment convergence.
Conversely, the Skorokhod representation theorem gives random variables
Xk∼αk and X∼α such that Xk→X almost surely. Convergence of
the p-th moments makes d(Xk,x0)p uniformly integrable. The estimate
and Vitali’s theorem yield E[d(Xk,X)p]→0. The law of (Xk,X) is
a coupling, hence Wp(αk,α)→0. Finally, truncating the continuous
moment function by min{d(⋅,x0)p,Rp} proves the equivalence with the
uniform tail condition.
On compact spaces the moment function is bounded and continuous, so the moment
condition is automatic and Wp metrizes weak convergence.
On a finite metric space, weak and strong topologies coincide. If
dmin=minx=yd(x,y) and
dmax=maxx,yd(x,y), then
Many constructions in modern machine learning act directly on probability laws. This section isolates this viewpoint and records two useful principles: some transformations move particles without splitting them, while others are intrinsically diffusive.
on Wasserstein space. Later chapters use such maps repeatedly: flow matching and diffusion models evolve laws during sampling, one-step transportation methods learn maps between latent and data distributions, and transformers update the empirical law of their tokens; see Chapter Paragraph and Section Evolution in Depth of Transformers. Two questions are especially useful. The structural question asks whether Φ preserves a discrete particle representation. The metric question asks whether Φ is stable, for instance Lipschitz, for Wp.
Thus the weights and the number of particles are preserved, up to possible collisions between images. This is the natural structure behind deterministic particle methods: particles move, but they do not split. Lavenant and Savaré Lavenant & Savaré, 2026 study when transformations of measures admit transport representatives of the form (95), the obstructions to choosing representatives continuously, and the additional regularity available when Φ is Wasserstein-Lipschitz.
The opposite case is a stochastic transformation, where one input particle can generate a full output distribution. Let K be a Markov kernel on X, so that K(y,⋅) is a probability measure for each y. To obtain a map on Pp(X), assume a finite-moment bound
is a measure-to-measure map from Pp(X) to itself: integrating the
moment bound against α proves that Ψ(α) has finite pth moment. If
X=Rd and K(y,dx)=κ(x−y)dx for a probability density
κ with finite pth moment, then Ψ(α)=α∗κ is convolution.
Unless K(y,⋅) is a Dirac mass, a single atom is sent to a diffuse
probability distribution. Heat flows, noising steps in diffusion models, and
other smoothing mechanisms therefore belong to this mass-splitting class.
If in addition X is Polish and
Wp(K(y,⋅),K(y′,⋅))≤Ld(y,y′), then Ψ is L-Lipschitz
for Wp. Glue an input coupling of (y,y′) with measurable optimal
couplings between K(y,⋅) and K(y′,⋅), then integrate the resulting
kernel coupling. Its expected pth-power cost is at most Lp times the input
coupling cost.
Regularity of Φ is a stability requirement: small perturbations of the input law should not create large changes of the output law. For transport representations, the following elementary estimate separates the spatial Lipschitz constant of the map from its sensitivity to the input measure.
Proof
Let π be an optimal coupling between α and β. The measure (T[α],T[β])♯π is a coupling between Φ(α) and Φ(β), hence
Self-attention is a central example because the number of tokens can be large and variable. A token cloud is represented by the empirical law α=n−1∑iδxi, and a single-head mean-field attention layer is naturally a transport representation. With the notation of Section Evolution in Depth of Transformers, define
and a residual transformer layer uses the closely related map (Id+τΓθ[α])♯α. Lipschitz estimates for Attθ are therefore stability estimates for attention in the many-token regime.
Proof
Write AR=∥Q∥op∥K∥opR2. For x,z∈B(0,R), the attention weight
satisfies e−AR≤ax(z)≤eAR. Moreover the functions ax and axVz have Lipschitz constants bounded by eAR times polynomial factors in R and ∥Q∥op,∥K∥op,∥V∥op. By Kantorovich--Rubinstein duality,
The same differentiation of the quotient with respect to x gives a spatial Lipschitz bound for x↦Γθ[α](x) on B(0,R), uniformly in α∈PR. Since W1≤Wp on probability measures and the output remains in the ball B(0,∥V∥opR), Proposition Proposition: Wasserstein stability of transport representations, applied with E=B(0,R), proves the estimate.
Distributional Robustness And Wasserstein Infinity¶
Wasserstein distances define ambiguity sets around empirical laws. Given
samples zi and αn=n1∑iδzi, a
distributionally robust optimization problem replaces empirical risk by
The robust risk is therefore an empirical risk in which each sample is replaced
by its worst penalized perturbation. For p=1 and an Lθ-Lipschitz loss,
Figure Div shows this robustification for a
genuinely nonlinear classification problem. The red and blue samples form two
noisy interlocking crescents whose opposing tips overlap locally. The
Wasserstein adversary transports samples toward high-loss regions under a
global root-mean-square displacement budget.
show_book_figure("kantorovich-dro-ambiguity")
Wasserstein robustness reshapes the separator between two noisy interlocking
moons. The black curve is the learned zero-score boundary. Filled dots are
observed samples; hollow dots and violet segments show a deterministic
approximation of the adversarial transport for increasing quadratic
Wasserstein radii.
Interactive panel. Increase the Wasserstein radius to move the two moons
toward high-loss regions and observe how their winding nonlinear separator
reorganizes.
minimizes the worst displacement rather than an average displacement.
It is the limit of Wp as p→∞ on bounded spaces, but not the
limit of the linear objectives defining Wpp. Although the
essential-supremum objective is not linear, each sublevel is a convex
support-constrained feasibility problem:
Thus one can compute it by threshold search over feasible coupling problems.
Proof
If W∞(β,α)≤ρ, choose couplings πm whose
essential displacements are at most ρ+1/m. Their fixed marginals make the
family tight; Prokhorov’s theorem and closedness of the marginal constraints
give a weak limit π. Portmanteau’s theorem, applied to the closed sets
{d≤ρ+η} and then letting η↓0, shows that π is
supported on {d≤ρ}.
Disintegrate this coupling as
∑iaiδzi⊗νi. Each νi is supported in
B(zi,ρ), so the robust expectation is bounded above by the
displayed sum. Compactness and upper semicontinuity provide a maximizer
zi⋆ in every ball. The measure
β=∑iaiδzi⋆ and the coupling
∑iaiδ(zi,zi⋆) attain the reverse inequality.
The coupling viewpoint developed in this chapter provides feasibility,
existence, geometry, and stability. The next chapter adds the complementary
dual description, in which marginal constraints are represented by
Kantorovich potentials.
Kantorovich, L. (1942). On the transfer of masses (in Russian). Doklady Akademii Nauk, 37(2), 227–229.
Villani, C. (2003). Topics in Optimal Transportation (Vol. 58). American Mathematical Society.
Villani, C. (2009). Optimal Transport: Old and New (Vol. 338). Springer.
Rachev, S. T., & Rüschendorf, L. (1998). Mass Transportation Problems: Volume II: Applications. Springer.
Courty, N., Flamary, R., Tuia, D., & Rakotomamonjy, A. (2017). Optimal transport for domain adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(9), 1853–1865.
Courty, N., Flamary, R., Habrard, A., & Rakotomamonjy, A. (2017). Joint distribution optimal transportation for domain adaptation. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.), Advances in Neural Information Processing Systems 30 (pp. 3730–3739).
Rubner, Y., Tomasi, C., & Guibas, L. J. (2000). The earth mover’s distance as a metric for image retrieval. International Journal of Computer Vision, 40(2), 99–121.
Solomon, J., De Goes, F., Peyré, G., Cuturi, M., Butscher, A., Nguyen, A., Du, T., & Guibas, L. (2015). Convolutional Wasserstein distances: efficient optimal transportation on geometric domains. ACM Transactions on Graphics, 34(4), 66:1-66:11.
Bonneel, N., Rabin, J., Peyré, G., & Pfister, H. (2015). Sliced and Radon Wasserstein barycenters of measures. Journal of Mathematical Imaging and Vision, 51(1), 22–45.
Bonneel, N., & Digne, J. (2023). A Survey of Optimal Transport for Computer Graphics and Computer Vision. Computer Graphics Forum, 42(2), 439–460. 10.1111/cgf.14778
Schiebinger, G., Shu, J., Tabaka, M., Cleary, B., Subramanian, V., Gould, J., Solomon, A., Liu, S., Lin, S., Berube, P., Lee, L., Chen, J., Brumbaugh, J., Rigollet, P., Hochedlinger, K., Jaenisch, R., Regev, A., & Lander, E. S. (2019). Optimal-Transport Analysis of Single-Cell Gene Expression Identifies Developmental Trajectories in Reprogramming. Cell, 176(4), 928-943.e22. 10.1016/j.cell.2019.01.006
Tong, A., Huang, J., Wolf, G., van Dijk, D., & Krishnaswamy, S. (2020). TrajectoryNet: A Dynamic Optimal Transport Network for Modeling Cellular Dynamics. Proceedings of the 37th International Conference on Machine Learning, 119, 9526–9536. https://proceedings.mlr.press/v119/tong20a.html
Lavenant, H., Zhang, S., Kim, Y.-H., & Schiebinger, G. (2021). Towards a Mathematical Theory of Trajectory Inference. arXiv Preprint arXiv:2102.09204. https://arxiv.org/abs/2102.09204
Klein, D., Uscidda, T., Theis, F., & Cuturi, M. (2024). GENOT: Entropic (Gromov) Wasserstein Flow Matching with Applications to Single-Cell Genomics. Advances in Neural Information Processing Systems, 37. 10.52202/079017-3301