Semi-discrete and Wasserstein-1
This chapter develops three computational consequences of duality. Eliminating one potential gives the semi-dual; for discrete measures, this viewpoint leads to auction algorithms, while a continuous source and discrete target lead to Laguerre-cell geometry. The final part specializes duality to , where Lipschitz functions and flow fields replace convex potentials. The material connects auction and network-flow methods Bertsekas, 1992Bertsekas & Eckstein, 1988, computational geometry Aurenhammer et al., 1998Mérigot, 2011Mérigot, 2013, and the Kantorovich--Rubinstein and Beckmann formulations Kantorovich & Rubinstein, 1958Beckmann, 1952.
Semi-dual¶
The semi-dual eliminates one potential by an exact -transform. It preserves concavity while removing the explicit pointwise inequality constraint.
General Measure Semi-dual¶
For arbitrary measures, partial maximization converts the constrained two-potential dual into an unconstrained optimization over one function.
Denote the extended full-dual objective by
Thus . For fixed , feasibility is equivalent to . Since is nonnegative, the largest admissible choice maximizes the objective and gives
Partial maximization preserves concavity. Moreover, because and both measures have unit mass. Potentials are therefore defined only up to an additive constant, while the optimization is unconstrained.
Discrete Semi-dual¶
For two discrete measures
with common total mass , use the same notation for vectors:
Eliminating the source vector gives
where
The function is concave, piecewise affine, and invariant under . If ties are resolved by choosing , then a supergradient is
It is therefore the mismatch between the desired target mass and the mass currently attracted by each target coordinate. At ties, splitting source mass among active targets describes the full superdifferential.
Auction Algorithm¶
The auction algorithm is derived from coordinate maximization of the semi-dual of the linear assignment problem. Its practical form uses bidder-specific dual-weight updates that cross the selected row’s next indifference threshold by ; this controlled relaxation prevents jamming at nonsmooth ties. We follow the account of Mérigot and Thibert Mérigot & Thibert, 2020, itself based on Bertsekas’ auction algorithm and its -scaling refinement Bertsekas, 1981Bertsekas & Eckstein, 1988Bertsekas, 1992. In this section, and . A permutation matrix represents the probability coupling .
Coordinate Ascent and Discrete Laguerre Cells¶
Write for the target Kantorovich potential. Specializing the discrete semi-dual to uniform weights gives
Thus is dual feasible. This is the discrete -transform of Remark Remark: Discrete -transform, with the same sign convention as in the general and semi-discrete formulations.
The discrete Laguerre cells are
They can overlap at ties. They are the finite counterparts of the general semi-discrete Laguerre cells in Definition Definition: Laguerre Cells and Power Diagrams: the displayed cell is that definition restricted to row indices. If every row has a unique minimizer, then
An overfull cell therefore calls for a decrease of its dual weight. Proposition Proposition: Dual Certificate for an Assignment shows that a perfect matching in the contact graph certifies optimality of ; conversely, assignment duality and complementary slackness produce such a matching at every maximizer.
For , define
When the cell is nonempty, the largest maximizing decrement along the negative th coordinate is the largest such bid Mérigot & Thibert, 2020. At a tie, even this largest maximizing decrement can vanish, so naive coordinate ascent may jam before reaching a dual maximizer.
Bids and Relaxed Contacts¶
Auction avoids jamming by moving an unassigned row beyond its next indifference point. Let and be its best and second-best targets:
The winning dual weight is updated by
Unlike exact coordinate maximization, this update uses the selected row’s bid rather than the maximum bid over the whole cell. Afterward, the reduced cost of is exactly above that of the unchanged alternative . The row nevertheless takes ; its former owner, if any, becomes unassigned. Because of this overshoot, a bid need not increase the nonsmooth semi-dual. Coordinate ascent motivates the update, but -complementary slackness is the invariant used in the convergence proof.
A bid gives the newly assigned row this property. Decreasing can only make less attractive to rows assigned elsewhere, and the previous owner of is removed. Every iteration therefore preserves the condition.
Figure Div shows actual iterates on the planar point clouds used in Div. For the current target potential, define the auction reduced costs
Exact zeros are the discrete Laguerre contacts of row , whereas an owned edge only needs to satisfy by -complementary slackness.
At an intermediate state, the current ownership matching is ; the labels in the figure report its cardinality.
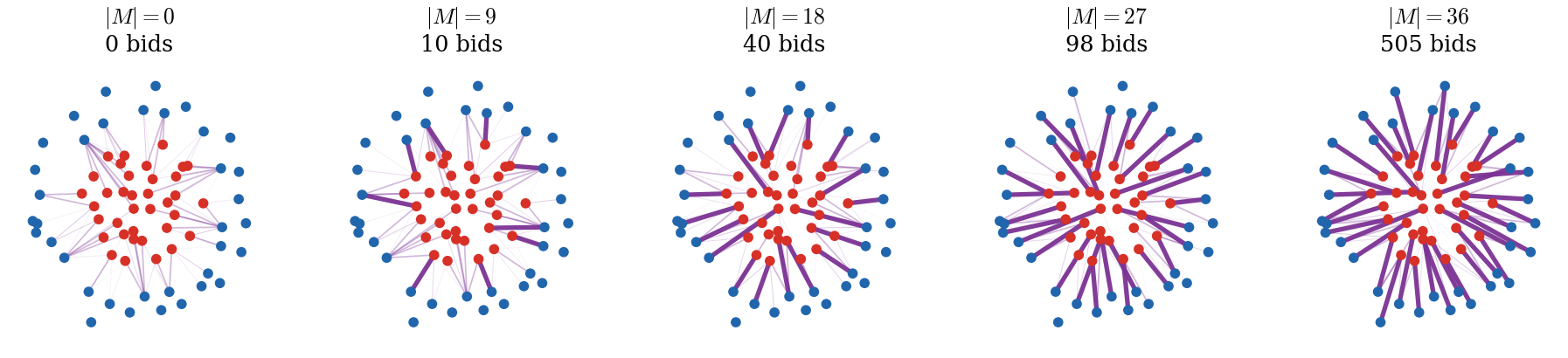
Geometric progression of the unit-mass transportation auction. Thick violet segments form the current partial ownership matching, while thin translucent segments show the unmatched edges with smallest auction reduced costs. The labels report matching cardinality and cumulative bid count. With , the final assignment is reached after 505 bids and coincides with the exact squared-distance optimum.
Interactive panel. Vary the bid increment and inspect how assignments and target dual weights evolve toward complementary slackness.
Fixed Tolerance¶
For a prescribed tolerance, relaxed contact gives both an optimality certificate and a finite bound on the number of bids.
Proof
Each bid decreases one target potential by at least . Once a target has an owner, later bids may change that owner but never leave the target empty. While the algorithm is incomplete, an unassigned target therefore retains its initial zero potential. A selected target is either unassigned, hence has zero potential, or has value at least by comparison with a zero-potential target. Each target can consequently receive at most bids. At termination every row and column has one active entry.
For the cost certificate, summing -complementary slackness over the returned permutation gives the first inequality below. The second is the dual lower bound of Proposition Proposition: Dual Certificate for an Assignment, applied to :
One dense bid scans reduced costs, proving the complexity bound. For integer costs, the unnormalized assignment gap is an integer smaller than one and must therefore vanish.
-Scaling¶
The cold-start estimate above exposes the limitation of a single tolerance. A large is fast but gives only a coarse certificate, whereas the small required for high accuracy can produce a bid count proportional to . Continuation first learns a rough dual-potential landscape and then sharpens it instead of restarting from zero.
Algorithm Algorithm: Auction With -Scaling starts at the cost scale and halves the tolerance until it reaches the requested value . Each phase rebuilds the ownership matrix but retains the target potential from the preceding phase. The previous complete assignment already certifies approximate contact for this potential, so the next auction refines an existing dual landscape.
Proof
The initial tolerance is . If it equals , the fixed-tolerance proposition gives the result in one phase. Otherwise the first phase starts from the zero potential and costs because .
Consider a later -phase initialized from a target potential obtained at preceding tolerance . The preceding assignment satisfies -complementary slackness. Lemma 25 of Mérigot and Thibert Mérigot & Thibert, 2020, expressed in the present sign convention, bounds the decrease of each potential component during the new phase by . Since each bid decreases one component by at least , the phase uses at most
bids. Consecutive tolerances satisfy , hence each warm-started phase costs dense operations. Halving gives the stated phase count. The last phase enforces -complementary slackness, so the fixed-tolerance proposition yields the accuracy and integer-cost conclusions.
A cold-started -auction has bound , while scaling uses a logarithmic number of phases. Thus scaling is a high-accuracy guarantee, not an unconditional speedup: its bound improves the cold-start estimate when is large compared with . For integer costs, choosing gives an exact assignment in operations.
Semi-discrete¶
The semi-discrete case is the setting where dual potentials become weights of Laguerre cells. This gives both geometry and algorithms for quantization and density fitting.
Discrete Targets and Laguerre Cells¶
Consider the case where
has distinct atoms and positive weights; zero-weight atoms can be removed. The same construction applies if is discrete, after exchanging the roles of and . Restricting the minimization in Definition Definition: -Transform to the support of , equivalently applying that definition with the discrete target space and identifying a vector with the function defined by , gives the discrete -transform
This maps a vector to a continuous function because it is the minimum of finitely many continuous functions. Using this transform when is discrete yields the finite-dimensional semi-dual
The objective is invariant under , so one may impose the gauge .
The geometric object encoded by the dual weights is a weighted nearest-neighbor diagram: each source point is assigned to the target atom that realizes the discrete -transform.
For quadratic costs, varying the dual weights moves the walls between adjacent cells while keeping them parallel. This is the geometric mechanism by which the cell masses are adjusted.
Figure Div follows this adjustment from unweighted Voronoi cells to a power diagram whose cell masses match the prescribed discrete target weights.
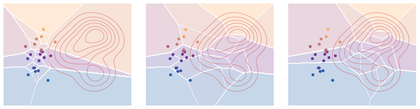
Laguerre cells for semi-discrete quadratic transport. The red contours show a continuous source density given by a three-component Gaussian mixture on the right. The twenty-one colored circular sites are the atoms of the discrete target , sampled from a compact cloud on the left; each site color matches its Laguerre cell. Starting from ordinary Voronoi cells, semi-dual weight updates deform the cells so that the -mass captured by each cell approaches the prescribed target mass.
The interactive demo exposes the dual-weight mechanism directly. Increase the number of weight updates to watch cells with too little mass expand and cells with too much mass shrink.
Interactive panel. Use the weight and seed controls to deform Laguerre cells and watch how their areas respond to semi-discrete masses.
Mass Balance¶
The semi-dual energy can be rewritten as
Proof
The first-order optimality condition says that solving the semi-discrete dual amounts to choosing weights so that
The gradient components sum to zero, consistently with the gauge invariance. Conversely, balanced cells define the piecewise-constant map on . Its graph lies in the contact set , so continuous complementary slackness proves that both the map and the weights are optimal. For the quadratic cost, uniqueness follows from Brenier’s theorem when has a density.
The sign of the gradient has a direct geometric interpretation. Increasing lowers the corresponding power distance and expands ; decreasing shrinks it. The dotted outline marks the balanced cell, so semi-dual ascent can be read as a mass-balancing procedure on a power diagram.
Figure Div makes the sign of this gradient geometric.
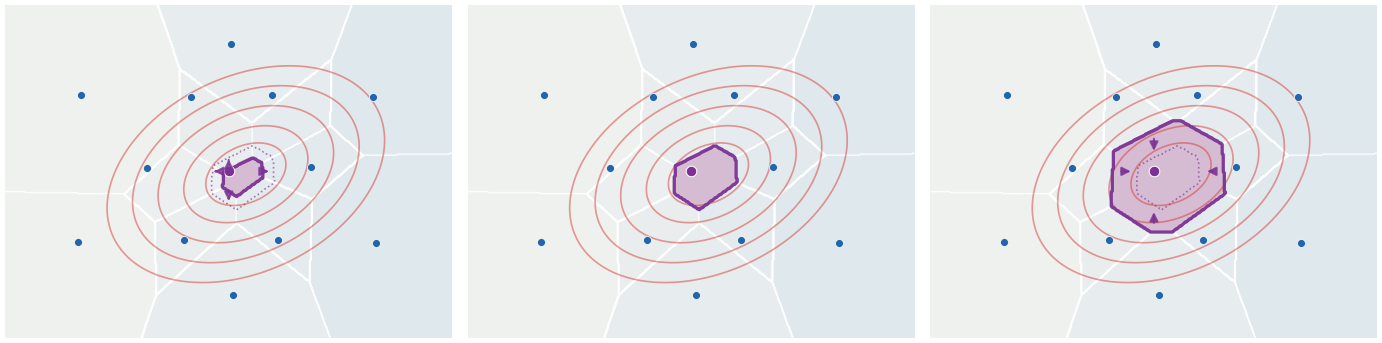
Dual weights control Laguerre cell masses in the semi-discrete quadratic problem. The same blue target sites and red Gaussian source density are used in all panels; only the highlighted violet weight is changed. The dotted violet outline is the balanced cell. If the highlighted cell has too little source mass, then and the ascent update increases the weight, expanding the cell outward. If it has too much mass, the update decreases the weight, shrinking it inward. At balance, the cell mass matches the prescribed target mass and the first-order update vanishes.
Interactive panel. Vary the target weights and the number of dual updates to watch Laguerre cells rebalance their masses.
Quadratic power diagrams have polyhedral cells and can be computed efficiently using computational-geometry algorithms Aurenhammer, 1987Aurenhammer et al., 1998Mérigot, 2011. Expanding the cost shows that a cell minimizes . The lower envelope of these affine functions gives the power diagram, while the lower hull of the lifted sites gives its dual regular triangulation. For a planar source, this is a three-dimensional hull and Chan’s output-sensitive algorithm costs for hull vertices Chan, 1996. A three-dimensional source lifts to four dimensions and is not covered by that particular bound.
Stochastic Optimization¶
The semi-discrete formulation is useful because the objective is an expectation with respect to :
Away from cell boundaries, the stochastic gradient of the integrand is
an unbiased estimator of when cell boundaries have -measure zero. One can therefore maximize the semi-dual without first discretizing : the measure is used as a black box from which independent samples are drawn, a natural setup in high-dimensional statistics and machine learning.
Starting from , stochastic gradient ascent draws and performs
The stochastic supergradient has zero coordinate sum and preserves the gauge. For almost-sure stochastic-approximation convergence, one typically imposes
For example, one may use with . The standard finite-horizon rate instead concerns averaged iterates.
Proof
Concavity and the squared-distance recursion yield
Summing, discarding the final squared distance, and using concavity at gives . Substitution of proves the claim.
This stochastic viewpoint is one of the main algorithmic advantages of the semi-discrete formulation Mérigot, 2011Genevay et al., 2016.
Optimal Quantization¶
Optimal quantization asks for the best discrete approximation of a measure by codepoints. It is the geometric core of vector quantization, compression and -means clustering.
Free Masses and Prescribed Weights¶
The classical problem optimizes both codepoint positions and their probabilities. For a measure , define
This problem is classical in approximation theory and information theory Graf & Luschgy, 2000Lloyd, 1982.
The equal-weight case, , prescribes the weights and is treated at the end of this section.
Proof
Enclose in a cube and subdivide it into congruent cubes, where . Placing one codepoint in each nonempty cube gives the upper bound.
For the lower bound, fix any set of codepoints and write . Since the density is bounded above, the mass of the -neighborhood of has mass at most . For , one has for . Hence
Taking the -th root and minimizing over proves the lower bound.
This deterministic rate mirrors the empirical optimal-transport sample-complexity rate: both are governed by the spacing of points in dimension . Quantization is best-case and deterministic, while empirical OT is random, but both display the same curse of dimensionality. Zador’s theorem further identifies the sharp asymptotic constant and limiting codepoint density Graf & Luschgy, 2000.
For fixed codepoints , the powered cost is convex. Its -th root need not be convex. The dependence on is nonconvex and is generally computationally hard. The rest of this section distinguishes the free-mass Lloyd reduction from the fixed-weight geometry underlying finite-particle gradient flows.
Lloyd Algorithm¶
The computational appeal of quantization comes from splitting the nonconvex search over sites into two elementary operations. For fixed sites, the optimal assignment is purely local: each point is sent to one of its nearest sites, and the resulting cells are Voronoi cells. This is the assignment step behind Lloyd’s algorithm and the -means method.
Proof
For any coupling between and a measure supported on , the conditional destination of a point belongs to , so its conditional cost is at least . Integrating gives the lower bound. Conversely, choose a measurable nearest-codepoint map , breaking ties measurably, and set . Then and the induced transport reaches the displayed lower bound.
Consequently, the quantization energy can be written in nearest-centroid form:
At a differentiability point of this energy, any local minimizer with nonempty cells satisfies the centroid condition
For the squared Euclidean cost, this becomes
Lloyd’s algorithm, also known as the -means algorithm, iterates this fixed point: assign points to nearest sites, then replace each site by the centroid of its cell Lloyd, 1982. The assignment and centroid steps each minimize the appropriate block, so the objective cannot increase. Nonconvexity means this does not guarantee a global minimizer. For a finite data set with squared Euclidean loss, -means++ gives an expected logarithmic approximation guarantee Arthur & Vassilvitskii, 2007.
Continuous Lloyd Flow¶
There is also an infinitesimal version of Lloyd’s fixed point, but it should first be understood on finite labelled configurations. Assume that and that does not charge Voronoi boundaries. For a configuration , define, on nonempty cells,
as the cell mass and centroid. Empty cells are singular points of the vector field; one either freezes them, as in the algorithm below, or reseeds them. The relaxed step
is an explicit-Euler step for the cell-mass preconditioned gradient flow of the quantization energy ,
Indeed, at differentiability points of , the envelope theorem gives
so that
Equivalently, this is the gradient flow of for the site metric ; it is not the unweighted Euclidean gradient flow unless the masses are absorbed into the time step. Along smooth portions of the flow,
If carries fixed positive weights, independent of the Voronoi masses , this labelled particle ODE is equivalently a weak continuity equation,
in the sense of the measure evolutions introduced in Chapter Paragraph. The weights in this transport equation are auxiliary weights for the moving labelled particles; they are not the Voronoi masses used to define the quantization energy. If one records instead the free-weight projection
then, formally,
Thus the free-weight quantizer evolves by a balance equation, not by pure transport. This is why the construction is intrinsically finite-dimensional: Voronoi cells, centroids and labels define the velocity, and a canonical extension to arbitrary measures is not obtained by replacing with the support of a measure. Indeed, any measure with dense support would have zero support-distance quantization error.
Mean-Field Limit and Ultrafast Diffusion¶
There is nevertheless a precise high-resolution continuum theory when the number of codepoints tends to infinity. If , the limiting Eulerian variable is the density of sites, meaning heuristically that codepoints lie in . Thus the limit is , not a limit in the exponent of the PDE. In one dimension, Caglioti, Golse and Iacobelli embed the ordered particle configuration in and prove quantitative convergence of the discrete gradient flow toward a limiting flow Caglioti et al., 2015. A perturbative two-dimensional analysis around the optimal hexagonal lattice is developed in Caglioti et al., 2018. For -quantization in dimension , set , so for the quadratic cost used in this section, and write . For well-prepared configurations whose empirical site distributions converge to , the rescaled energy is described, up to a universal cell-shape constant, by
Formally,
Since the first variation is , the formal -gradient flow is the weighted ultrafast diffusion equation
with periodic or no-flux boundary conditions. Iacobelli studies the associated one-dimensional very-fast-diffusion equation and its convergence to equilibrium Iacobelli, 2019; Iacobelli, Patacchini and Santambrogio then use the JKO scheme and Wasserstein-gradient-flow tools to prove well-posedness, regularity estimates and convergence for a multidimensional weighted version Iacobelli et al., 2019. When , set and . The same equation becomes
which makes the negative exponent, hence the ultrafast-diffusion character, explicit. Its stationary site density is proportional to .
Figure Div shows the relaxed Lloyd flow in a two-dimensional toy problem.
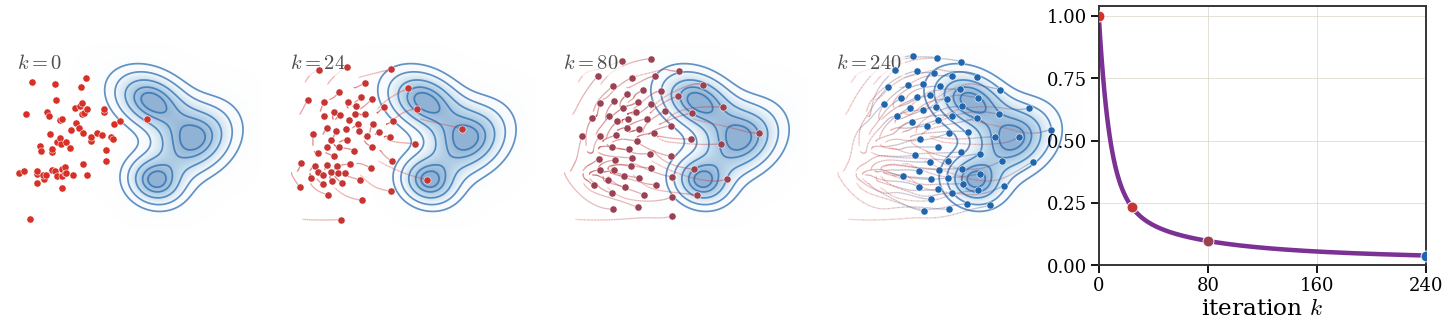
Relaxed Lloyd flow from a source Gaussian-mixture initialization toward a different target Gaussian-mixture density. The blue contours and shading show the target density , while the colored disks are the moving codepoints initialized from the source mixture. The faint curves trace the labelled sites under the explicit-Euler Lloyd ODE. The right panel displays the relative quantization energy, illustrating the monotone decay of the objective along the relaxed iterations.
Figure Div follows the associated Voronoi cells and generators through Lloyd iterations, making the decrease of the quantization energy visible.
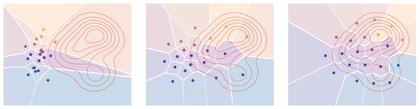
Lloyd quantization for the same continuous density and twenty-one initial sites as the Laguerre-cell figure. The red contours show the density , while the colored disks are the current codepoints and have the same colors as their Voronoi cells. The iterations move the initially left-located sites toward the high-density region and reshape the cells according to centroidal Voronoi geometry.
The interactive demo separates the nonconvex geometry from the fixed-point update: increase the iteration counter and watch sites migrate toward the density before settling into a local centroidal configuration.
Interactive panel. Use the iteration and site controls to compare Lloyd-style quantization steps with the semi-discrete geometry.
Quantization with Fixed Equal Weights¶
The free-mass formulation above optimizes the positions and the weights of the atoms. A different problem is obtained by prescribing the weights. In the equal-weight case, set
and minimize only over the positions . Assume that the sites are distinct, that has a density, and that cell boundaries have zero -mass. Let be the Laguerre cell transported to , so that , and define its centroid
At differentiability points, the envelope theorem gives
Locally, while labels remain optimally matched, the metric on equal-weight empirical measures induces the particle metric . Hence the associated gradient flow is the coupled system
Equivalently, satisfies a continuity equation with velocity . This is the so-called finite-particle gradient-flow viewpoint developed more systematically in Chapter Paragraph; the fixed-weight cells are Laguerre cells rather than the free-mass Voronoi cells used by Lloyd’s method.
Equal-Weight Quantization on the Line¶
The following classical scalar quantization result gives the precise form of the inverse-CDF rule for equal-weight quadratic quantization Graf & Luschgy, 2000. The atoms are not exactly the midpoint quantiles in general; they are the averages of the quantile function over equal mass bins. Midpoint inverse-CDF samples are nevertheless asymptotically equivalent and are often the most convenient rule in numerical examples.
Proof
After sorting the atoms, the quantile formula for gives
The minimization decouples over the intervals , and the best constant approximation of on is its average. These averages are nondecreasing because is nondecreasing, so they satisfy the sorting constraint. Strict convexity gives uniqueness.
Denote by the interval average. If is , set and write . Uniform Taylor expansion gives, for ,
Subtracting the average over and integrating gives
uniformly in . Summing over yields a Riemann sum for .
Thus the common deterministic rule should be read as a midpoint approximation of the optimal bin-average formula. Orthogonal projection onto constants shows that it has the same leading squared error under the same smoothness assumptions; for the uniform law on , both rules coincide and give the regular grid . Random sampling has a different asymptotic regime.
Proof
Let be the empirical quantile function. The one-dimensional formula gives
Write with i.i.d. uniform on , and let be the empirical quantile function of the . Then . The classical uniform quantile-process theorem Vaart & Wellner, 1996Bobkov & Ledoux, 2019 gives
Uniform continuity of and the functional delta method give
Since and have the same law, the sign disappears in the squared norm. The continuous mapping theorem gives the distributional convergence. Standard fourth-moment bounds for the uniform quantile process give uniform integrability, hence convergence of expectations. Since , Fubini’s theorem gives the displayed expectation limit.
Combining these propositions gives a sharp contrast between optimal placement and random placement on the line. Deterministic equal-weight quantization has squared error of order , hence error of order , while i.i.d. empirical sampling has expected squared error of order , hence root-mean-square error of order . This is consistent with broader empirical OT sample-complexity theory Dereich et al., 2013Fournier & Guillin, 2015Weed & Bach, 2019.
Figure Div illustrates both parts of this comparison: optimal atoms are uniform in quantile coordinates, and their error decays one power of faster than the root-mean-square empirical error.
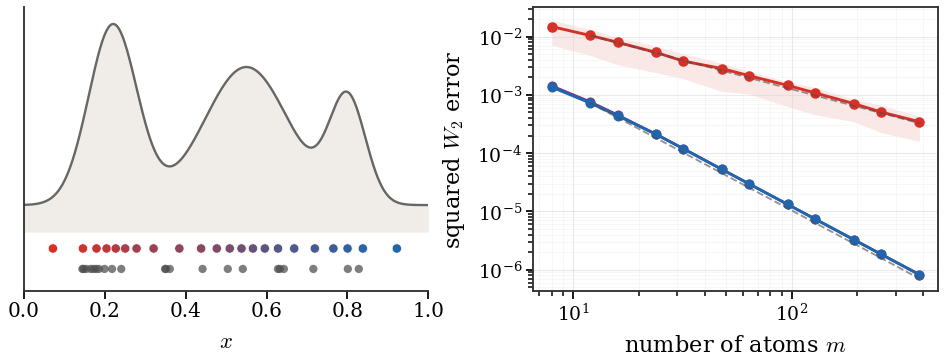
One-dimensional equal-weight quantization in quantile coordinates. Left: for a smooth positive density on , the colored atoms are bin averages of the inverse CDF over equal quantile intervals, while the gray atoms show one i.i.d. empirical draw with the same number of particles. Right: expected squared errors. The deterministic bin averages and midpoint quantiles follow the squared-error law, whereas i.i.d. empirical measures follow the slower expected squared-error law.
Interactive panel. Change the one-dimensional law, the number of atoms and the Monte Carlo seed to compare optimal equal-weight quantization with random empirical sampling. The right panel recomputes the squared error curves from the quantile formula.
Wasserstein-1 Norm¶
The distance has an especially transparent dual: the admissible potentials are exactly 1-Lipschitz test functions. This makes the meeting point between transport, PDE formulations and weak norms on signed measures.
c-Transform for Wasserstein-1¶
Assume that is a distance on and take the ground cost .
Proof
First suppose for some . For ,
where the last inequality is the reverse triangle inequality. Thus .
If , then , so for all , hence . Taking gives . Therefore . Applying the same property to gives , so every 1-Lipschitz function is -concave.
By the preceding proposition, a closed dual pair has the form with . The Kantorovich dual therefore becomes the Kantorovich--Rubinstein formula
This expression depends only on the signed measure . On compact , the same supremum defines the Kantorovich--Rubinstein norm on finite signed measures with zero mass Kantorovich & Rubinstein, 1958. Homogeneity and the triangle inequality are immediate, while definiteness follows because Lipschitz functions separate finite Radon measures. On a noncompact pointed space, one uses normalized Lipschitz functions and measures with finite first moment.
For a discrete signed measure with ,
This finite-dimensional linear program can be solved by generic interior-point or first-order methods. If support points are involved, however, it still contains Lipschitz constraints, mirroring the coupling variables of the original discrete Kantorovich LP; the dual formulation alone does not remove the all-pairs structure. The gain comes on structured metric spaces where the distance is generated locally: it is then enough to impose Lipschitz inequalities on neighboring pairs, because summing along paths recovers the constraints between arbitrary points. The one-dimensional ordered case is the first example; the graph-geodesic case is described later in Proposition Proposition: and Beckmann Flow on a Graph.
When on , ordering the support points reduces the constraints to neighboring pairs:
In one dimension this is equivalent to the cumulative formula given in the one-dimensional transport section.
Wasserstein-1 on Euclidean Spaces¶
In Euclidean space, the Lipschitz constraint has a local differential form and its dual variable is a flux. Let have finite first moments and set . Rademacher’s theorem gives
The flux need not have a Lebesgue density: Dirac-to-Dirac transport already produces a measure concentrated on a segment. Let be a vector-valued Radon measure, let denote its total variation, and define .
Proof
For every feasible and smooth 1-Lipschitz , . The Lipschitz dual gives one inequality. Conversely, if is an optimal plan, define
The fundamental theorem of calculus gives , and .
This is the Beckmann formulation Beckmann, 1952Santambrogio, 2015. If , its cost is . Outside the source and target mass, , expressing local conservation.
Once discretized with finite elements, the dual Lipschitz problem and the Beckmann problem become nonsmooth convex optimization problems. The same formulation extends to complete Riemannian manifolds by replacing straight segments with minimizing geodesics and using tangent-valued Radon measures.
Graph Distances and Beckmann Flows¶
Finite graphs give a simple discrete instance where a metric is generated by local moves, so the all-pairs Lipschitz constraints collapse to edge constraints.
This graph distance turns into a finite-dimensional flow problem.
Proof
The edge constraints imply the all-pairs bound by summing along paths and minimizing over paths. Conversely, a 1-Lipschitz function for satisfies on every edge. The first equality is therefore the Kantorovich--Rubinstein formula on the metric space .
For the second equality, write the graph Beckmann problem and dualize its equality constraint with a potential :
Using , the coupling term is . The minimization over each scalar flow is finite exactly when , and is then equal to zero. The dual problem is the graph Lipschitz dual above. Strong duality holds because this is a finite-dimensional linear program with a nonempty feasible set: connectedness and allow the signed surplus to be routed along paths.
Figure Div shows the optimal edge flux on both a quasi-regular and a nonuniform Delaunay graph, emphasizing that the Beckmann variables live only on graph edges.
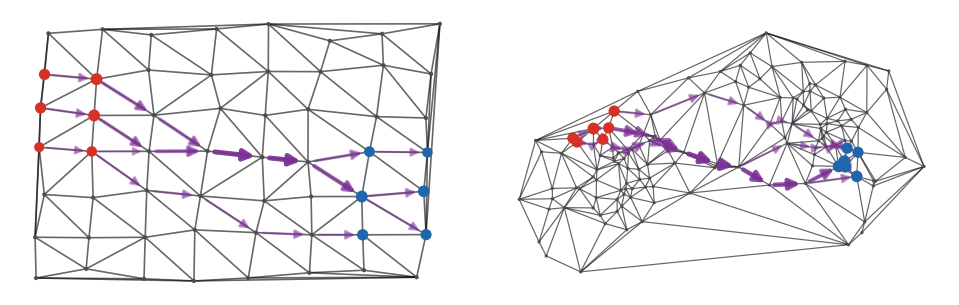
Graph Beckmann formulation of on a Delaunay graph. Red and blue disks encode the positive and negative parts of . Violet arrows display the signed edge flow : orientation gives the sign, width is proportional to , and the flow satisfies the conservation constraint .
The interactive graph view lets the source and sink clusters move and changes the graph resolution. It makes the transshipment interpretation of visible: signed mass is routed through local edges rather than matched only by straight source-to-target segments.
Interactive panel. Use the graph and demand controls to inspect how Wasserstein-1 transport becomes a flow problem on edges.
This graph formulation is the transshipment version of . It is the natural discrete analogue of the Beckmann formulation: gradients are edge differences, divergences are incidence-matrix balances, and geodesic distance is shortest-path length. It can be solved by min-cost flow methods on sparse graphs, while entropic or KL-projection variants lead to flow-Sinkhorn algorithms for graph Beckmann, 1952Peyré, 2026.
- Bertsekas, D. P. (1992). Auction algorithms for network flow problems: a tutorial introduction. Computational Optimization and Applications, 1(1), 7–66.
- Bertsekas, D. P., & Eckstein, J. (1988). Dual coordinate step methods for linear network flow problems. Mathematical Programming, 42(1), 203–243.
- Aurenhammer, F., Hoffmann, F., & Aronov, B. (1998). Minkowski-type theorems and least-squares clustering. Algorithmica, 20(1), 61–76.
- Mérigot, Q. (2011). A multiscale approach to optimal transport. Computer Graphics Forum, 30(5), 1583–1592.
- Mérigot, Q. (2013). A comparison of two dual methods for discrete optimal transport. In Geometric science of information (pp. 389–396). Springer.
- Kantorovich, L., & Rubinstein, G. S. (1958). On a space of totally additive functions. Vestn Leningrad Universitet, 13, 52–59.
- Beckmann, M. (1952). A continuous model of transportation. Econometrica, 20, 643–660.
- Mérigot, Q., & Thibert, B. (2020). Optimal Transport: Discretization and Algorithms. arXiv Preprint arXiv:2003.00855. 10.48550/arXiv.2003.00855
- Bertsekas, D. P. (1981). A new algorithm for the assignment problem. Mathematical Programming, 21(1), 152–171.
- Aurenhammer, F. (1987). Power diagrams: properties, algorithms and applications. SIAM Journal on Computing, 16(1), 78–96.
- Chan, T. M. (1996). Optimal output-sensitive convex hull algorithms in two and three dimensions. Discrete & Computational Geometry, 16(4), 361–368.
- Genevay, A., Cuturi, M., Peyré, G., & Bach, F. (2016). Stochastic optimization for large-scale optimal transport. Advances in Neural Information Processing Systems, 3440–3448.
- Graf, S., & Luschgy, H. (2000). Foundations of Quantization for Probability Distributions (Vol. 1730). Springer.
- Lloyd, S. (1982). Least Squares Quantization in PCM. IEEE Transactions on Information Theory, 28(2), 129–137.
- Arthur, D., & Vassilvitskii, S. (2007). k-means++: The Advantages of Careful Seeding. Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 1027–1035.