The goal of this chapter is to pass from finite matching to transport between
arbitrary probability laws. The central stakes are to define measures,
push-forwards and Monge maps carefully enough that the discrete picture
survives, while exposing why deterministic maps can fail to exist. Monge’s
original formulation Monge, 1781 and modern treatments
Villani, 2003Villani, 2009Santambrogio, 2015Rachev & Rüschendorf, 1998 are the
conceptual background for this transition.
The previous chapter handled two sets with the same number of points. To relax
this to a more general setting, one needs probability distributions, so that
points may carry unequal masses and continuous densities can be treated in the
same language as finite clouds.
from pathlib import Path
import sys
from IPython.display import Image as DisplayImage
from IPython.display import display
here = Path.cwd()
myst_dir = None
for candidate in [here, here.parent, here / "myst", here.parent / "myst", here.parent.parent / "myst"]:
if (candidate / "ot4ml_web.py").exists():
myst_dir = candidate.resolve()
sys.path.insert(0, str(myst_dir))
break
if myst_dir is None:
raise RuntimeError("Could not locate myst/ot4ml_web.py")
repo_root = myst_dir.parent
thumbnails = repo_root / "notebooks-figures" / "thumbnails"
def show_book_figure(name, width=760):
display(DisplayImage(filename=str(thumbnails / f"{name}.png"), width=width))
Measures are the language that lets point clouds, densities and singular
objects be handled uniformly. We only recall the facts needed later:
integration, total variation, densities and probabilistic laws.
In applications, it is useful to manipulate both the positions xi and the
weights ai. Moving the positions is a Lagrangian discretization; changing
the weights is an Eulerian one. The Lagrangian view is often more adaptive, but
it tends to break convexity.
We write M(X) for the finite signed Borel measures on a metric space
(X,d). The Borel sets form the smallest σ-algebra containing the
open subsets of X, obtained by closing the open sets under complements and
countable unions. Unless otherwise stated, all measures are finite.
A Dirac measure is defined by δx(A)=1 if x∈A and 0 otherwise.
For the discrete measure above,
Many measure-theoretic statements used later require a mild regularity
assumption on the underlying space. The point is not to restrict applications,
since Euclidean spaces, complete separable manifolds and separable Hilbert
spaces are covered, but to exclude pathological measurable spaces where
disintegration, tightness or weak convergence can fail to behave properly.
This assumption already includes genuinely infinite-dimensional spaces. In the
Euclidean dynamical formulations used later, the path space
is Polish. Completeness follows because a uniformly Cauchy sequence of
continuous paths converges uniformly to a continuous path, and separability
follows by approximating paths uniformly by piecewise-linear paths with
rational breakpoints and rational values. This example is used later as the
state space for laws of trajectories: the endpoint evaluation maps are
continuous on S, which makes endpoint constraints well behaved for
dynamical optimal plans and Schrodinger bridges; see the path-space formulation in
Path-Space Formulation and Section Path-Space Schrodinger Problem.
Polish spaces are the natural ambient category for probability measures. Borel
probability measures on them are regular, tightness gives compactness
criteria, regular conditional probabilities and disintegrations exist under
standard assumptions, and Wasserstein spaces remain Polish; see Proposition
Proposition: Wasserstein Spaces As Ground Spaces.
A positive Borel measure is Radon if it is inner regular, meaning that the mass
of every Borel set is the supremum of the masses of its compact subsets. Every
finite Borel measure on a Polish space is Radon. Such a measure integrates
measurable functions, and we write the pairing as
Integration against a finite measure on a compact space defines a continuous
linear form on the Banach space (C(X),∥⋅∥∞), since
∣∫fdα∣≤∥f∥∞∣α∣(X). Conversely, the
Riesz--Markov--Kakutani representation theorem identifies every continuous
linear form on C(X) with integration against a finite signed Radon
measure Rudin, 1987Bogachev, 2007. This is the
duality M(X)=C(X)∗ that later supports convex duality.
where the supremum is over finite or countable measurable partitions of A.
If α=∑iaiδxi with distinct atoms, then
∣α∣=∑i∣ai∣δxi. If
dα(x)=ρ(x)dλ(x), then
d∣α∣(x)=∣ρ(x)∣dλ(x).
For the reverse inequality, write the Jordan decomposition
α=α+−α−. The measurable sign
s=dα/d∣α∣ takes values in {−1,1} outside a null set and satisfies
dα=sd∣α∣. By regularity of Radon measures on compact spaces, s can
be approximated in L1(∣α∣) by continuous functions fk with
∥fk∥∞≤1. Hence
∫fkdα→∫sdα=∣α∣(X).
For absolutely continuous measures
dα=ραdλ and dβ=ρβdλ,
Then α=∑k=1rakδzk and
β=∑k=1rbkδzk.
This convention merges masses located at the same point before comparing the two
measures. If the two input supports are already enumerated without repetitions
and are disjoint, this simply amounts to taking
(zk)k=(x1,…,xn,y1,…,ym) and padding the weights as
a=(a~,0m) and b=(0n,b~). With this common-support notation,
Probability measures represent laws of random variables. Let
(Ω,F,P) be an abstract probability space and let X be Polish. A
random variable with values in X is a measurable map
X:(Ω,F)→(X,B(X)), or simply X:Ω→X once the measurable
structures are understood. Its law is the Radon probability measure
α=X♯P defined by
Push-forwards encode how maps move mass. This short section is the bridge
between deterministic maps and linear operations on measures.
For a measurable map T:X→Y, the push-forward operator
T♯:M(X)→M(Y) records the distribution of image points. It
sends a Dirac mass to T♯δx=δT(x). For discrete
measures,
The operation is linear in the input measure, although its definition for a
general measure uses inverse images rather than a decomposition into Dirac
masses. Moving from T to T♯ thus linearizes the action of a map at
the price of moving from X to the measure space M(X).
Proof
Apply the push-forward identity to a compactly supported continuous function
h and use the change of variables y=T(x):
Uniqueness of Lebesgue densities gives the target-variable identity; setting
y=T(x) gives the source-variable formula.
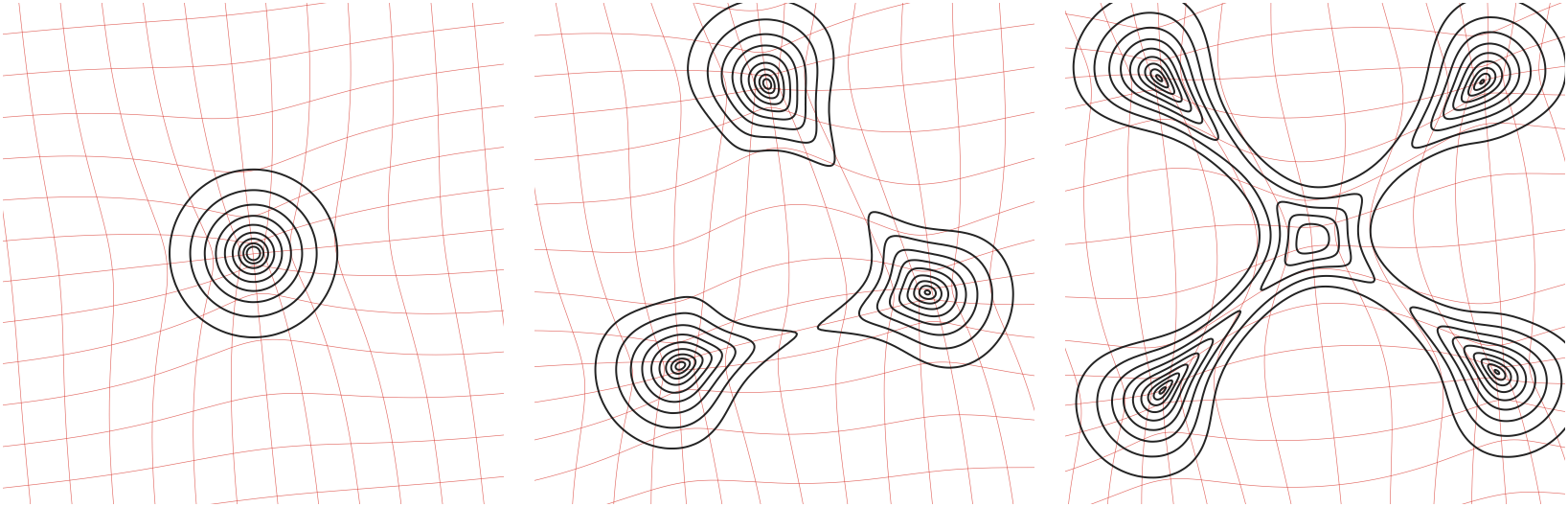
Figure Div makes the determinant
factor visible. Even when the source density is uniform, nonlinear
diffeomorphisms can compress area around one or several centers and expand it
elsewhere; the target density is therefore not obtained by the naive composition
ρα∘T−1 alone. The high-density bumps appear exactly where the
deformed grid cells have small area.
Jacobian determinant in the density push-forward formula. The three panels show
smooth diffeomorphisms that strongly compress a uniform source grid around one,
three, and five centers. The deformed grid is drawn as a dense red mesh, and the pushed density
is shown through black level sets of
ρβ(y)=∣detT′(T−1y)∣−1. The tighter crop focuses on the
bump region, where small grid cells coincide with large values of the pushed
density.
Interactive panel. Change the compression strength, width, and residual
rotation to see how the determinant controls the density amplification.
Monge’s problem asks for a deterministic map transporting one law onto another
while minimizing a prescribed cost. It is geometrically direct, because every
source point is assigned one destination, but analytically fragile: the
feasible set is non-convex, it can be empty, and a map cannot split mass. These
limitations motivate Kantorovich’s relaxation in the next chapter.
This proves the counting statement. If every target atom has mass 1/n, each
target receives exactly one source atom, hence a permutation. The converse and
the cost identity follow by direct substitution.
Proof
A standard measure-isomorphism theorem identifies the atomless standard
probability space (X,α) with ([0,1],Leb) modulo null sets
Bogachev, 2007. Since the Polish target is a standard Borel
space, choose a Borel isomorphism from a full-β Borel subset of Y onto
a Borel subset of [0,1]. The generalized quantile of the pushed law sends
Lebesgue measure to that law. Composing with the inverse Borel isomorphism and
the source isomorphism gives the desired transport map, after arbitrary
definitions on discarded null sets.
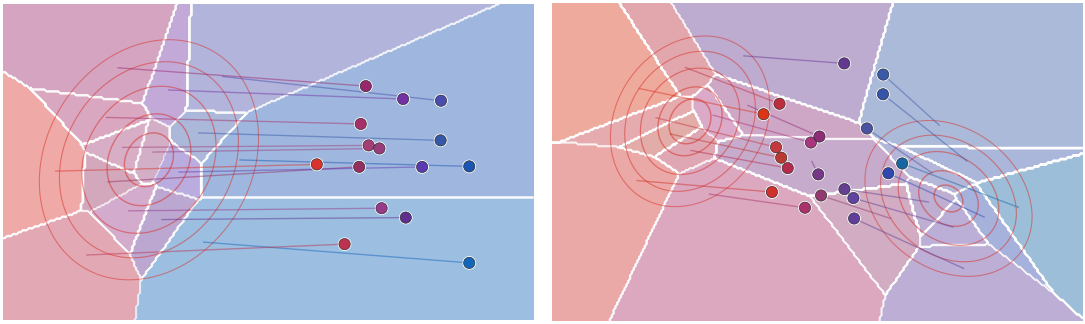
show_book_figure("monge-semidiscrete-maps")
Semi-discrete Monge maps. The red contours show the continuous source density
α. The colored regions extend the numerical Laguerre cells over the whole
displayed domain, while their masses are computed with respect to α. The circular atoms
form the discrete target β. Their colors are tied to horizontal position,
with a small random perturbation, and are reused for the cells. Faint segments
connect cell barycenters to their images under the piecewise-constant Monge
map.
Interactive panel. Vary the target masses, source density and number of
dual-weight updates to see how ordinary Voronoi cells deform into Laguerre
cells with the prescribed semi-discrete masses.
The next figure shows a finite-dimensional instance of this deterministic
viewpoint. The source and target measures are empirical color clouds in RGB
space, and the map transports colors while leaving pixel positions fixed.
Grayscale equalization is one-dimensional, but full palette transfer requires
transporting empirical measures in a three-dimensional color space. Early
methods used affine statistics or iterated one-dimensional projections
Reinhard et al., 2001Pitié et al., 2005; replacing these projections by a
three-dimensional OT map gives a more intrinsic palette match
Rabin et al., 2011.
Figure Div shows a finite-dimensional instance of this deterministic viewpoint.
show_book_figure("monge-color-transfer-rgb")
Color transfer as a Monge map in RGB space, from a beach photograph to a
flower photograph. The top row applies the palette map to the source image; the
bottom row shows the empirical color clouds in the RGB cube. Only colors are
transported here, not pixel locations.
Interactive panel. Use the interpolation, resolution, target palette, and contrast controls to replay the RGB color transport while keeping pixel locations fixed.
Since bounded Lipschitz functions separate probability measures on Polish
spaces, α=β. The identity map proves the converse.
If either term on the right of the triangle inequality is infinite, there is
nothing to prove. Otherwise take ϵ-minimizers
S♯α=γ and T♯γ=β. The composition
T∘S is feasible from α to β, and Minkowski’s inequality gives
The directed value Wp is useful conceptually, but it is too
rigid to be the main distance between measures: it can be infinite and
asymmetric. Kantorovich’s formulation remedies both issues by replacing maps
with couplings.
This section records the main regimes where Monge’s deterministic formulation
becomes well posed. Brenier’s theorem is the central result: for the squared
Euclidean cost, absolute continuity of the source restores existence,
uniqueness and convex-potential structure.
Brenier’s theorem Brenier, 1987Brenier, 1991 ensures that in Rd, for the
quadratic cost, absolute continuity of the source is enough for Monge’s problem
to have a unique solution. It also gives the decisive structural description:
the optimal map is the gradient of a convex potential.
Proof Sketch
The proof uses Kantorovich relaxation and duality, developed later in the book.
Choose optimal c-concave potentials (f,g) and set
ϕ(x)=∥x∥2/2−f(x)/2. Then ϕ is convex, and complementary slackness
is equivalent to the Fenchel equality
ϕ(x)+ϕ∗(y)=⟨x,y⟩, or y∈∂ϕ(x), for almost
every pair under an optimal plan. Since α has a density and convex
functions are differentiable Lebesgue-almost everywhere,
∂ϕ(x)={∇ϕ(x)} for α-almost every x. Every optimal
plan is therefore concentrated on the same graph, proving existence and
uniqueness of the Brenier map.
Brenier’s theorem is the higher-dimensional analogue of the one-dimensional monotone rearrangement theorem. In one dimension, the derivative of a convex function is an increasing map; in several dimensions, the corresponding object is the gradient of a convex function. Such gradients are monotone fields:
Radial symmetry gives a useful higher-dimensional case where the Brenier map
reduces to a one-dimensional monotone rearrangement. A measure α on
Rd is radial if Q♯α=α for every orthogonal map Q. Such a
measure is determined by the law of the radius ∥x∥, and the optimal map
transports this radius while keeping the angular direction fixed.
Proof
Let αR=(∥⋅∥)♯α and
βR=(∥⋅∥)♯β be the radial laws. Since α is
absolutely continuous, αR has no atoms. The map
τ=Fβ−1∘Fα is therefore the monotone one-dimensional
transport from αR to βR. If X∼α and R=∥X∥, then
τ(R) has law βR. Moreover, by radiality, the conditional direction
X/∥X∥ given R=r is uniform on the sphere for αR-a.e. r>0.
Thus T changes only the radius, from R to τ(R), and keeps the uniform
angular distribution. It follows that T♯α is radial with radial law
βR, hence T♯α=β.
It remains to check optimality. The function τ is nondecreasing and
nonnegative. Define ψ(r):=∫0rτ(s)ds on R+. Then
ψ is convex and nondecreasing, so ϕ(x):=ψ(∥x∥) is convex
on Rd. Since α is absolutely continuous, it does not charge the origin
nor the radii where the monotone function τ is discontinuous. Thus
The map T is therefore a gradient of a convex potential and pushes α to
β. Brenier’s theorem identifies it as the unique quadratic optimal Monge
map. The displayed cost formula follows by substituting T(x) in
∫∥x−T(x)∥2dα(x).
If α is not absolutely continuous, the same radial idea is still useful but
has to be interpreted at the level of couplings of the radial variables: atoms
on spheres may have to be split, so a Monge map need not exist.
Brenier’s theorem provides a canonical way to extract the monotone part of a
nondegenerate square-integrable map u:Ω→Rd. Its law
β=u♯λ records where the mass ends up, but forgets how the
points of Ω were labelled. Brenier’s polar factorization
Brenier, 1987Brenier, 1991 separates these effects: a measure-preserving
rearrangement changes labels, then the unique convex-gradient map sends the
uniform source to the output law.
Proof
Let T=∇ϕ be the Brenier map from λ to β and let S be
the reverse Brenier map. The two maps are inverse almost everywhere. Hence
s=S∘u satisfies s♯λ=λ and
T∘s=u almost everywhere. The same inverse identity gives uniqueness.
Absolute continuity is a sufficient form of Brenier’s nondegeneracy
hypothesis. Without such a hypothesis, deterministic polar factorization may
fail or be nonunique.
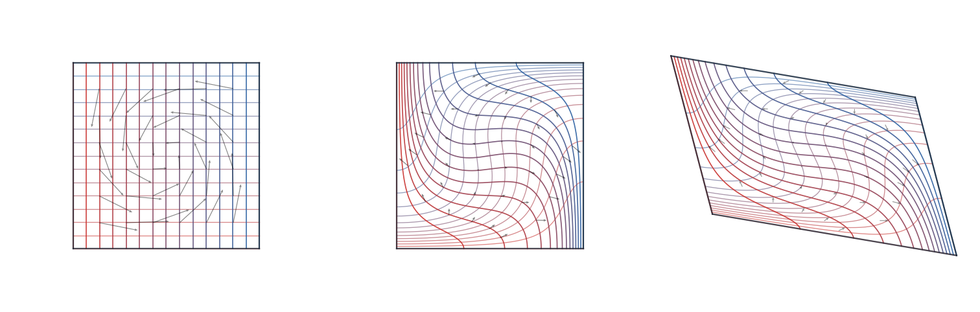
Figure Div separates these two factors on a
colored grid. Its three panels display x, s(x), and
u(x)=(∇ϕ∘s)(x). The map s swirls the square grid while
preserving area, whereas ∇ϕ is a symmetric positive definite affine
map and hence the gradient of a convex quadratic potential.
show_book_figure("monge-polar-factorization")
Polar factorization as a relabeling followed by a Brenier map. From left to
right, the panels show x, s(x) with s♯λ=λ, and
u(x)=∇ϕ(s(x)). Here s is generated by the area-preserving flow of a
divergence-free Hamiltonian vector field, while the Brenier factor is the
symmetric positive definite affine map ∇ϕ(z)=Bz. Faint arrows indicate
the successive maps.
Interactive panel. Vary the area-preserving swirl and the SPD stretch to
separate relabeling from the Brenier factor.
For linear maps under a Gaussian reference, this reduces to the usual matrix
polar decomposition. If X∼N(0,Id) and u(x)=Ax, then
u♯N(0,Id)=N(0,AA⊤). The Brenier map from
N(0,Id) to this Gaussian is x↦Sx, where
S=(AA⊤)1/2 is symmetric positive semidefinite. Hence
When A is invertible, O=S−1A is orthogonal. In the singular square case,
S†A is only a partial isometry and must be extended on its kernel to
an orthogonal matrix O before Ox preserves the full standard Gaussian law.
The factor Sx is the convex-gradient transport part, whereas Ox is the
measure-preserving relabeling.
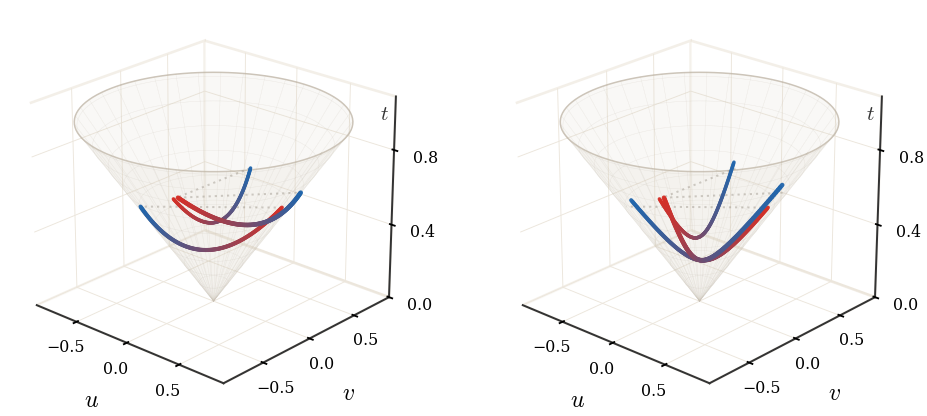
An optimal map does not only match two endpoint measures; it tells how to draw
a path between them. Each particle keeps its identity and travels at constant
speed from its initial position to its image.
Proof
For s<t, define Ss,t=Tt∘Ts−1 along transported particles.
Then (Ss,t)♯αs=αt and
The reverse inequality follows by applying the triangle inequality to the
three legs α→αs→αt→β. For a Brenier map
T=∇ϕ, Tt is the gradient of
(1−t)∥x∥2/2+tϕ(x), which is strongly convex for every t<1 and hence
injective on the differentiability set of ϕ.
Figure Div illustrates this displacement geodesic on two non-convex silhouettes, both through representative particle paths and through the evolving transported density.
McCann displacement interpolation between a cat silhouette and a heart
silhouette. The first row displays a small farthest-point subset of transported
particles along Tt(x)=(1−t)x+tT(x). The second row renders kernel-smoothed
densities from a denser transported cloud as color images: white means zero
density, while high density saturates in the red-to-blue interpolation color of
the corresponding time.
Interactive panel. Use the interpolation and particle controls to compare the particle motion with the evolving density during McCann displacement interpolation.
The previous results identify the optimal map. Regularity theory asks when this
map is a classical smooth deformation rather than only an almost-everywhere
gradient. For quadratic costs this becomes the regularity theory of the
Monge--Ampere equation.
in the Alexandrov sense, with second boundary condition
∇ϕ(Ω)=Λ. Density bounds and convexity of the domains give
strict convexity and localization of sections. Caffarelli’s interior theory
then yields the Cloc2,α estimates
Caffarelli, 2003Villani, 2009.
Figure Div illustrates the geometric role
of the convexity assumption through a finite-sample stress test rather than a
counterexample. A quadratic assignment transports a dense farthest-point sample
of the disk to a dense farthest-point sample of a connected non-convex target
made of two disks joined by a thin rectangle. The panels show the corresponding
empirical McCann interpolation, so the loss of convex target geometry is visible
directly along the transported particles.
Empirical quadratic OT interpolation from a disk to a connected non-convex
two-disk domain. A 5200-point farthest-point sample of the disk is matched to a
5200-point farthest-point sample of two disks connected by a thin rectangle. The
panels display (1−t)xi+tTN(xi) for the empirical optimal assignment TN.
Colors are inherited from the horizontal coordinate of xi in the initial
disk, making the transported material regions visible throughout the
interpolation.
Interactive panel. Change the neck strength and number of displayed rings to see how a smooth source foliation bends when the target develops a non-convex throat.
For smooth densities, the change-of-variables formula gives the
Monge--Ampere equation
With suitable boundary conditions, this characterizes the Brenier potential up
to an additive constant among convex solutions. The convexity constraint forces
det(∇2ϕ(x))≥0 and is necessary for this fully nonlinear elliptic
equation to be well posed.
The following proposition records the infinitesimal form.
The quadratic Euclidean cost is the model case, but optimal-map theory also covers many non-quadratic costs. The key point is to separate three roles: a convexity-like structure gives potentials, a twist condition prevents splitting, and curvature-type conditions give regularity.
The quadratic cost is special because it identifies the optimal map with the
Euclidean gradient of an ordinary convex potential. For the Wasserstein cost,
normalized as c(x,y)=∥x−y∥p/p with p>1, the same Monge-map picture
survives, but the potential is adapted to the cost. More generally, for
c(x,y)=h(x−y) with h smooth and strictly convex, absolute continuity of the
source again rules out splitting and yields a unique optimal map. This map is
characterized by a c-convex potential f: at differentiability points of
f,
Thus the Brenier formula T=∇ϕ should be read as the quadratic
representative of a broader c-convex theory. The Euclidean theory for
strictly convex displacement costs is developed in Gangbo--McCann’s work on
the geometry of optimal transportation Gangbo & McCann, 1996; see also
the general treatment in Villani, 2009.
On a Riemannian manifold, the natural analogue of the quadratic Euclidean cost
is the squared geodesic distance c(x,y)=dM(x,y)2/2. The optimal map is no
longer written with a vector-space subtraction, but with the exponential map
where ϕ is c-convex. This is the intrinsic version of the formula
T=x−∇ϕ in normal coordinates. The main additional issues are the cut
locus, possible non-uniqueness of minimizing geodesics, and regularity of the
exponential map, which is why the Euclidean statement is usually presented
first. The Riemannian polar-factorization theorem of McCann
McCann, 2001 gives the corresponding optimal-map framework, and
these ideas feed into displacement convexity and the general manifold theory of
optimal transport McCann, 1997Villani, 2009.
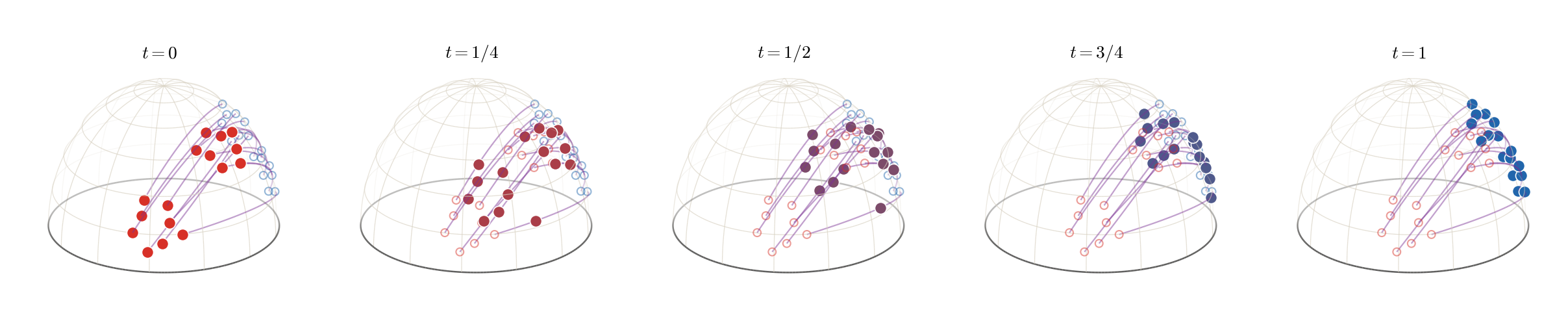
Figure Div makes this intrinsic
interpolation explicit on the closed upper hemisphere
M=S+2={x∈R3:∥x∥=1,x3≥0}. Consider two
equal-weight empirical measures α=n−1∑iδxi and
β=n−1∑jδyj and the intrinsic cost
Each γi is a constant-speed minimizing spherical geodesic, and
αt=n−1∑iδγi(t) is the intrinsic McCann
interpolation. The paths stay in the hemisphere because both sine
coefficients are nonnegative on [0,1].
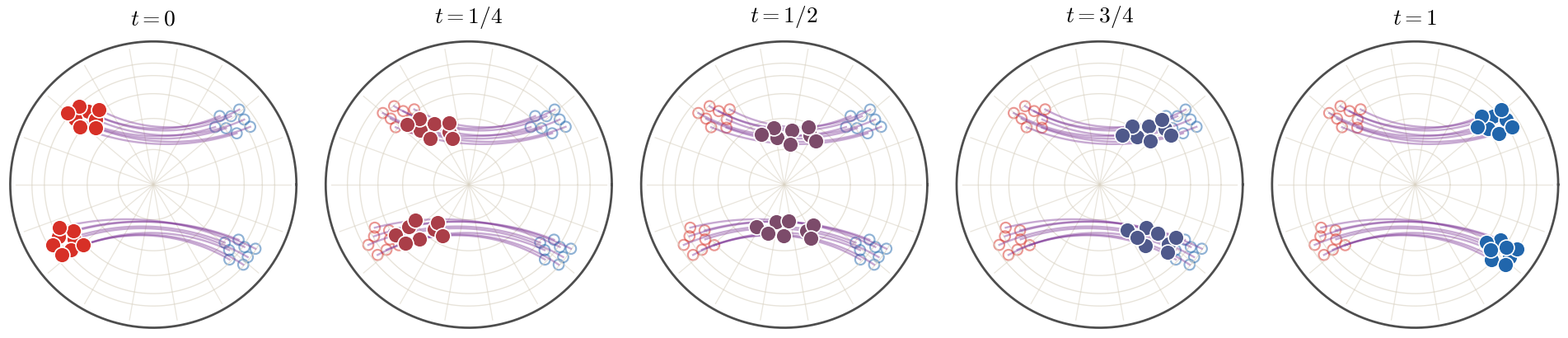
Intrinsic McCann interpolation on the upper hemisphere. The thin violet
great-circle arcs show the fixed optimal permutation coupling between the
hollow red and blue endpoint atoms. The filled atoms follow these arcs at
t=0,1/4,1/2,3/4,1, with color interpolated from red to blue.
For equal-weight point clouds, the cost
Cij=dD(xi,yj)2/2 again admits an optimal permutation
coupling, denoted by σ. Introduce the hyperboloid lift and Lorentz
product
In disk coordinates, its trace is a Euclidean circle orthogonal to the unit
circle, with diameters as the limiting case. Thus
αt=n−1∑iδγi(t) is the hyperbolic McCann
interpolation shown below. The sinh coefficients are the negative-curvature
counterparts of the sin coefficients in the spherical formula.
Intrinsic McCann interpolation in the Poincare disk. The black circle is the
ideal boundary, the faint grid gives hyperbolic radial and distance
coordinates, and the thin violet arcs are the fixed optimal geodesic coupling.
Filled atoms move from the hollow red source to the hollow blue target at
t=0,1/4,1/2,3/4,1.
The first non-degeneracy condition asks that the first-order information at a source point identifies at most one target point. This is the structural hypothesis that turns an optimal relation into a map.
Proof
The proof uses the Kantorovich duality formalism developed later in Chapter
Paragraph. Let (f,g) be optimal Kantorovich potentials and let π
be an optimal plan. Complementary slackness gives
f(x)+g(y)=c(x,y) for π-almost every (x,y), while dual feasibility gives
f(z)+g(y)≤c(z,y) for all z. Thus, for almost every contact pair, the
function z↦c(z,y)−g(y) touches f from above at x. At a point
where f is differentiable, this gives
If the cost is twisted, this equation determines at most one y. Hence no optimal plan can split the mass of such an x between several target points. Since differentiability holds on a full α-measure set, the plan is concentrated on the graph of a measurable map there.
The quadratic cost satisfies twist since ∇x∥x−y∥2=2(x−y); the bilinear cost c(x,y)=−⟨x,y⟩ satisfies twist since ∇xc(x,y)=−y; more generally c(x,y)=h(x−y) is twisted when h is smooth strictly convex and ∇h is injective. On a Riemannian manifold, the squared geodesic cost is twisted locally away from the cut locus. By contrast, a separated cost a(x)+b(y) is never twisted, since ∇xc does not see y.
Twist gives a map, but it does not by itself make this map continuous or smooth. For a general smooth cost, the relevant structural hypothesis is the Ma--Trudinger--Wang (MTW) condition, introduced for a priori estimates of the generated Jacobian equation associated with optimal transport Ma et al., 2005Trudinger & Wang, 2001.
The tensor above is often called the cost-sectional curvature. With this sign
convention, it measures how the negative x-Hessian of the cost bends when
the target point is varied through the dual momentum p.
Proof
This is the regularity theory of Ma--Trudinger--Wang, Trudinger--Wang and
Loeper, stated structurally rather than with all boundary hypotheses. The
c-convex potential solves a generated Jacobian equation. Weak MTW controls
the geometry of its contact sets and yields interior Hölder estimates. Strong
MTW adds a quantitative curvature lower bound; combined with smooth densities,
domain geometry and elliptic estimates, it yields higher regularity.
Conversely, Loeper proved that weak MTW is necessary for continuity for
arbitrary smooth positive data
Ma et al., 2005Trudinger & Wang, 2001Loeper, 2009Villani, 2009.
The flat quadratic and bilinear costs have zero MTW curvature, hence satisfy the weak condition. For the squared Riemannian distance, the MTW tensor is a refined curvature condition on the cost: near the diagonal it recovers sectional curvature, negative sectional curvature gives an obstruction, and global regularity also depends on cut-locus and domain-convexity issues. Many smooth strictly convex costs fail MTW, which is why twist is enough for existence of a map but not for regularity.
In one dimension, optimal transport is completely explicit. The cumulative
distribution function orders the mass, and the optimal coupling is obtained by
matching equal quantile levels. This case is both a computational tool and the
template for several linearized constructions used later.
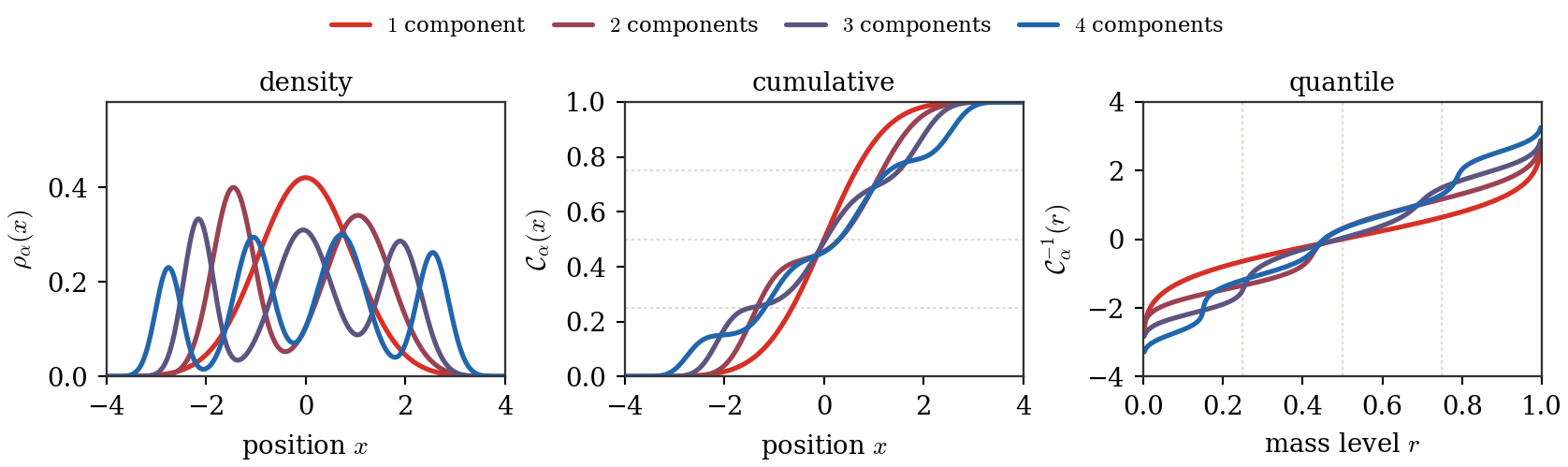
Figure Div follows four smooth laws through
these three representations. Each density mode produces a change of slope in
the cumulative function, while intervals of low density become steep portions
of the quantile function. The aligned quarter-mass guides make the inversion
between the last two panels explicit.
show_book_figure("monge-cdf-quantile-mixtures")
Densities, cumulative functions and quantiles for four Gaussian mixtures.
Red-to-blue colors identify mixtures with one through four components across
all three panels. The cumulative functions integrate the modes into successive
increases of mass, while inversion exchanges slowly varying cumulative regions
with steep quantile regions. Faint guides mark the same quarter-mass levels in
the last two panels.
Proof
Assume first that α has a strictly positive density, so that
Fα is strictly increasing and continuous. Let
γ=(Fα−1)♯Leb[0,1]. For every x,
General measures follow from the same argument with generalized inverses and
right-continuity. If α has no atoms, the probability integral transform
gives (Fα)♯α=Leb[0,1].
The quantile construction becomes a deterministic Monge map only when the source
has no atoms, because the cumulative distribution function can then be used as a
genuine change of variable. This gives an explicit one-dimensional Monge
solution in the atomless case. If α has atoms, a deterministic map may fail
to realize the same quantile matching because an atom cannot be split; the
corresponding relaxed statement is treated in Section
Relaxation For Arbitrary Measures, paragraph
Kantorovich solution in 1D.
Proof
By the quantile push-forward proposition, atomlessness of α gives
(Fα)♯α=Leb[0,1], while
(qβ)♯Leb[0,1]=β. Hence T♯α=β.
Let S be any admissible map and set πS=(Id,S)♯α. The
one-dimensional uncrossing theorem for relaxed couplings, proved later as
Theorem Theorem: One-dimensional Kantorovich solution, shows that the quantile
coupling π⋆=(qα,qβ)♯Leb[0,1] is optimal among
all couplings. Since α has no atoms, (Id,T)♯α=π⋆, and
therefore
The first formula follows from Theorem
Theorem: One-dimensional Kantorovich solution: the optimal coupling is obtained
by taking the same quantile level r for both measures. For p=1, use the
layer-cake identity. If qα and qβ are the quantile functions, then
and the measure of the set inside the integral is
∣Fα(x)−Fβ(x)∣ for almost every x.
For p=2, Bobkov and Ledoux
Bobkov & Ledoux, 2019 gave a complementary representation involving only
cumulative distribution functions. It gives the same exact value as the quantile
formula, but replaces the inverse-CDF step by an integral over CDF values. This
is useful when cumulative functions are easier to estimate or aggregate than
quantiles. This cumulative formula has recently been used to design
data-parallel estimators of sliced Wasserstein distances
Vauthier et al., 2026.
because, when u<v, the integration domain is the triangle
u≤x≤y<v, whose area is (v−u)2/2, and the case v<u is symmetric.
Apply this identity with u=qα(r) and v=qβ(r), where
qα=Fα−1 and qβ=Fβ−1, and integrate with
respect to r∈(0,1). Fubini’s theorem applies since the integrand is bounded.
For x≤y, the generalized inverse identities give, up to endpoint sets of
zero Lebesgue measure,
and the same argument with α and β exchanged gives the second positive
part.
The last panel of Figure Div is the one-dimensional specialization of the displacement interpolation introduced above.
show_book_figure("monge-1d-quantile-geodesic")
One-dimensional transport through quantiles. The same two smooth laws are
shown as densities, cumulative functions and quantile functions. The last
panel displays the displacement interpolation obtained by the linear quantile
path Qt=(1−t)Qα+tQβ, which is the explicit one-dimensional
W2 geodesic.
Interactive panel. Use the time and endpoint controls to follow the one-dimensional Wasserstein geodesic through quantiles, CDFs, and densities.
In quantile coordinates, the interpolating measure is characterized by
The line is the simplest tree. On a general tree, the order is no longer total,
but each edge still defines a cut and hence a cumulative imbalance. This gives
an exact formula for the W1 cost associated with the tree geodesic
distance. The formula is classical in fast earth-mover computations on tree
metrics Ling & Okada, 2007 and is also the mechanism behind tree-sliced
Wasserstein distances Le et al., 2019.
Proof
Let σ=α−β. Removing an edge e splits the tree into Ve and its
complement. For any coupling π, the net amount of mass crossing e from
Ve to V∖Ve minus the amount crossing in the reverse direction is
fixed and equals σ(Ve). Hence the total amount of transported mass whose
path uses e is at least ∣σ(Ve)∣. Since every unit of mass crossing e
pays the length ℓe, summing over edges gives
It remains to realize this lower bound. Process the rooted tree from the leaves
to the root. At a vertex v=o, compute the total signed mass in the subtree
below v, namely Fe=σ(Ve) for the edge e joining v to its parent.
If Fe>0, send Fe units of surplus from this subtree to the parent side; if
Fe<0, import −Fe units from the parent side into the subtree. After this
operation the subtree has zero net imbalance and can be collapsed into its
parent. Continuing upward balances all subtrees because σ(V)=0.
Decomposing these edge fluxes into source-to-target paths yields a coupling
whose traffic across each edge is exactly ∣Fe∣, and therefore whose cost is
the right-hand side of (90). The same postorder pass
computes all Fe, proving the complexity claim.
For a chain rooted at one end, the sets Ve are rays, so the tree formula is
the discrete version of the one-dimensional identity (84). This
edgewise cumulative decoupling is specific to the geodesic-distance cost
dT, i.e. to W1. For powers dTp with p>1,
the term (∑e∈[x,y]ℓe)p couples all edges along a path, so
the simple sum of absolute subtree imbalances no longer gives the optimal value.
The tree structure remains algorithmically useful in a different sense: tree
metrics give fast surrogates and embeddings for EMD-type computations on
histograms Indyk & Thaper, 2003Andoni et al., 2008Ling & Okada, 2007, and randomized or
data-adapted trees lead to tree-sliced Wasserstein distances that trade the
exact Euclidean ground metric for much faster one-dimensional/tree computations
Le et al., 2019.
The same tree can nevertheless be used as a genuine geodesic space. If π is
an optimal coupling for the squared tree distance dT2, the
associated displacement interpolation moves each packet of mass πij at
constant speed along the unique path from xi to xj. Figure
Div shows this tree analogue of McCann
interpolation. The intermediate measures are not necessarily supported on the
original vertices: mass may sit inside edges while it travels through the
branching structure.
McCann interpolation on a finite tree. A quadratic optimal plan is computed
between two non-uniform vertex histograms for the squared geodesic distance on
the tree. Each transported packet then moves along the unique tree path
connecting its source and target vertices. Circle areas encode transported
masses, colors interpolate from the source measure α in red to the target
measure β in blue, and faint colored corridors mark the tree branches
carrying transport.
There is another canonical way to build transport maps in several dimensions:
transport one coordinate at a time by conditional one-dimensional quantiles.
This construction is not usually cost-optimal, but it gives a deterministic
rearrangement under weak assumptions.
Proof
The construction is recursive. For k=1, let T1 be the monotone
rearrangement between the first marginals of α and β. Suppose
T1,…,Tk−1 have been constructed. Write
x<k=(x1,…,xk−1) and
T<k=(T1,…,Tk−1). Let αx<kk and
βy<kk be regular conditional laws of the k-th coordinate given
the previous coordinates. Define Tk(x<k,⋅) as the one-dimensional
monotone rearrangement from αx<kk to
βT<k(x<k)k. The chain rule for disintegrations shows that after
step k the first k coordinates of T♯α match those of β.
Figure Div shows the two-dimensional mechanism on image histograms.
Triangular rearrangement between the same cat and heart densities as in the
McCann interpolation figure. The panels are computed directly on image
histograms. The first three transitions move mass horizontally by the monotone
rearrangement between the x-marginals; the pivot has the target horizontal
marginal. The last three transitions keep each column fixed and move mass
vertically by one-dimensional monotone rearrangements between conditional
laws.
Interactive panel. Use the horizontal and vertical interpolation sliders to inspect the Knothe triangular rearrangement one coordinate update at a time.
This construction transports successively along coordinate axes and is often
called axis-wise transport. It depends on the chosen ordering of coordinates
and is not generally optimal for the quadratic cost. It is nevertheless a
useful limiting object: Brenier maps for increasingly anisotropic quadratic
costs converge to triangular rearrangements under suitable assumptions
Carlier et al., 2010.
Compactness gives a weakly convergent subsequence. Passing to the limit at the
leading scale forces its first-coordinate marginal to be the unique monotone
coupling. Optimality against the Knothe coupling and the lower bound
I1(πϵ)≥I1(πKR) then give, after cancellation
and division by ϵ,
Disintegration identifies the second coordinate as the conditional monotone
rearrangement. The scale-separated induction of
Carlier et al., 2010 controls the residual earlier-coordinate costs and
repeats this argument at every subsequent scale. Thus every weak limit is the
triangular graph coupling. A Lusin--Portmanteau argument and compact support
then upgrade convergence in law to convergence in L2(α).
Gaussian measures form the most important finite-dimensional family preserved
by quadratic optimal transport. The mean moves linearly, while the covariance
follows the Bures--Wasserstein geometry of positive semidefinite matrices.
Thus the OT geometry of one-dimensional Gaussians is the Euclidean geometry of
the closed half-plane (m,σ)∈R×R+. By contrast, the
Fisher--Rao boundary σ=0 is infinitely far from every nondegenerate
Gaussian, and the KL divergence from a nondegenerate Gaussian to a singular
one is infinite.
The positive square root gives the displayed formula for A. This map pushes
α to β and is a gradient of a convex quadratic potential, hence is
optimal by Brenier. If X∼α,
Letting η↓0 and using continuity of the matrix square root gives
the same trace bound with Σ,Λ. Hence every admissible coupling has
cost at least B(Σ,Λ)2. Conversely, the centered Gaussian laws
N(0,Σ) and N(0,Λ) satisfy the prescribed raw
second-moment constraints, and Proposition Proposition: Gaussian W2 Formula And Bures Covariance Term gives
equality, again by continuity in the singular case.
The covariance term B is the Bures--Wasserstein metric on positive
semidefinite matrices Bures, 1969Gelbrich, 1990Bhatia et al., 2019.
It separates Euclidean displacement of the mean from the intrinsic transport
geometry of covariance ellipsoids.
For 2×2 covariance matrices, this geometry can be seen inside a familiar
cone. The useful coordinates separate trace, anisotropy and correlation. Writing
identifies the vector space of symmetric 2×2 matrices with R3
through an orthonormal change of coordinates for the Frobenius inner product;
the inverse map is
Thus the cone of 2×2 covariance matrices is the Lorentz, or ice-cream,
cone. The Bures distance is not the ambient Euclidean distance in these
coordinates: on the positive definite interior it is the geodesic distance of a
smooth nonlinear geometry, whose geodesics are the covariance parts of Gaussian
optimal transport rather than the straight chords inherited from R3. The
cone panel below illustrates this distinction.
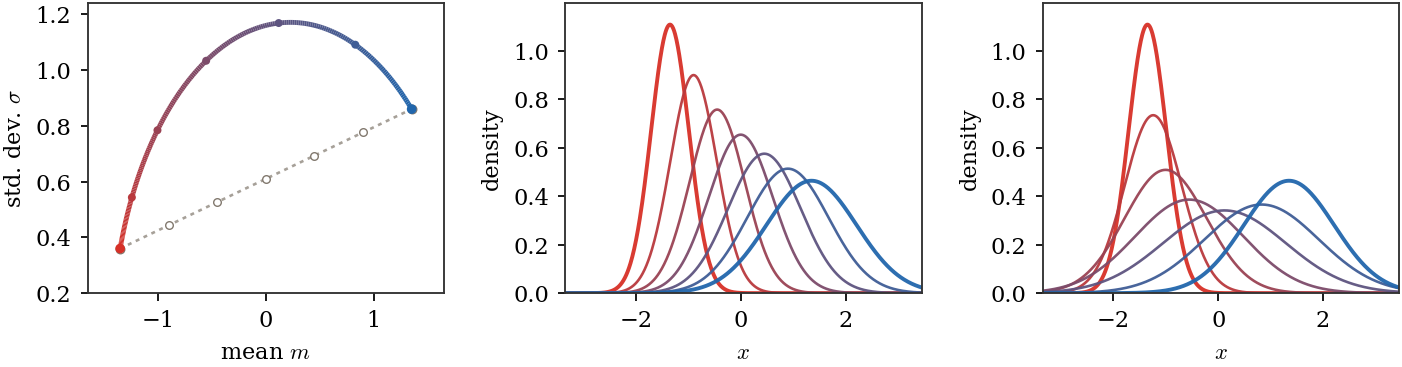
Figure Div displays this Euclidean half-plane geometry and the corresponding displacement interpolation of the Gaussian densities.
show_book_figure("monge-gaussian-w2-geodesic")
One- and two-dimensional Gaussian W2 geodesics. In one dimension, the
coordinates (m,σ) turn geodesics into Euclidean segments in the upper
half-plane. Both paths share red and blue endpoint colors; the first
interpolates directly between them, whereas the second passes through green at
mid-time. In two dimensions, means move linearly
while covariance ellipses
follow the Bures--Wasserstein interpolation. The cone panel displays the same
two covariance paths inside the 2×2 positive-semidefinite cone, with
u and v horizontal, t vertical, and faint gray chords showing the ambient
Euclidean segments for comparison.
Interactive panel. Use the target mean, variance, and angle controls to see
how the Gaussian Wasserstein geodesic moves means and covariance ellipses.
Wasserstein and Fisher--Rao geodesics in the one-dimensional Gaussian family.
Both interpolations share red and blue endpoint colors. The Wasserstein curves
interpolate directly between them, whereas the Fisher--Rao curves pass through
green at mid-time; the same palettes identify both geodesics in the left
parameter-space panel. The two
density panels use the same endpoint Gaussians and time samples, but the
Fisher--Rao path expands the standard deviation along its hyperbolic arc before
returning to the target scale.
Interactive panel. Move the endpoint and time controls to compare the
straight Wasserstein path with the Fisher--Rao hyperbolic path in the Gaussian
half-plane.
The cone panel in Figure Paragraph illustrates this distinction.
The two-dimensional Gaussian panels in the boxed figure show covariance
ellipses evolving along the Bures--Wasserstein interpolation, together with the
same covariance paths drawn in cone coordinates. The first path uses a direct
red-to-blue palette, whereas the second shares these endpoints but passes
through green. The interactive panel above
varies the same Gaussian ingredients in real time.
Bures--Wasserstein and Fisher--Rao covariance geodesics in the 2×2
positive-semidefinite cone. The three trajectories use distinct red-to-blue,
orange-to-violet, and teal-to-gold palettes, repeated identically in both
panels, while faint gray chords show the ambient Euclidean segments. The Bures
paths reach rank-one covariances on the cone boundary. The Fisher--Rao paths use
positive-definite regularizations with the same dominant directions because
the limiting rank-one covariances are not at finite Fisher--Rao distance.
Interactive panel. Move the rank-one limiting direction and the
positive-definite Fisher--Rao floor. The Bures path is allowed to touch the
closed covariance cone, while the Fisher--Rao path stays inside the open cone.
Symmetry, positivity and separation follow immediately. For the triangle
inequality, choose almost optimal orthogonal matrices Q1,Q2 for
(Σ,Λ) and (Λ,Γ). Since Q2Q1 is admissible for
(Σ,Γ),
Then UtUt⊤=(1−t)Σ0+tΣ1 and
VtVt⊤=(1−t)Λ0+tΛ1, while the squared Frobenius distance
is the same convex combination. Taking the infimum proves joint convexity.
Monge, G. (1781). Mémoire sur la théorie des déblais et des remblais. Histoire de l’Académie Royale Des Sciences, 666–704.
Villani, C. (2003). Topics in Optimal Transportation (Vol. 58). American Mathematical Society.
Villani, C. (2009). Optimal Transport: Old and New (Vol. 338). Springer.
Santambrogio, F. (2015). Optimal Transport for Applied Mathematicians: Calculus of Variations, PDEs, and Modeling. Birkhäuser.
Rachev, S. T., & Rüschendorf, L. (1998). Mass Transportation Problems: Volume I: Theory. Springer.
Rudin, W. (1987). Real and Complex Analysis (Third). McGraw–Hill.
Bogachev, V. I. (2007). Measure Theory. Springer.
Reinhard, E., Adhikhmin, M., Gooch, B., & Shirley, P. (2001). Color Transfer between Images. IEEE Computer Graphics and Applications, 21(5), 34–41.
Pitié, F., Kokaram, A. C., & Dahyot, R. (2005). N-dimensional Probability Density Function Transfer and Its Application to Color Transfer. IEEE International Conference on Computer Vision, 1434–1439.
Rabin, J., Peyré, G., Delon, J., & Bernot, M. (2011). Wasserstein barycenter and its application to texture mixing. International Conference on Scale Space and Variational Methods in Computer Vision, 435–446.
Brenier, Y. (1987). Décomposition polaire et réarrangement monotone des champs de vecteurs. C. R. Acad. Sci. Paris Sér. I Math., 305(19), 805–808.
Brenier, Y. (1991). Polar factorization and monotone rearrangement of vector-valued functions. Communications on Pure and Applied Mathematics, 44(4), 375–417.
Gangbo, W., & McCann, R. J. (1996). The geometry of optimal transportation. Acta Mathematica, 177(2), 113–161.
McCann, R. J. (1997). A convexity principle for interacting gases. Advances in Mathematics, 128(1), 153–179.
Caffarelli, L. (2003). The Monge-Ampere equation and optimal transportation, an elementary review. Lecture Notes in Mathematics, Springer-Verlag, 1–10.