This chapter compares optimal transport with divergence-based and adversarial
ways of measuring discrepancy. The main stake is topological:
ϕ-divergences are cheap but strong, while dual norms and GAN objectives
can be weak enough to compare singular measures. The discussion connects
classical information divergences Ciszár, 1967Ali & Silvey, 1966
with modern integral probability metrics and generative modeling
Sriperumbudur et al., 2009Goodfellow et al., 2014Arjovsky et al., 2017.
from pathlib import Path
import sys
from IPython.display import Image as DisplayImage
from IPython.display import display
here = Path.cwd()
myst_dir = None
for candidate in [here, here.parent, here / "myst", here.parent / "myst", here.parent.parent / "myst"]:
if (candidate / "ot4ml_web.py").exists():
myst_dir = candidate.resolve()
sys.path.insert(0, str(myst_dir))
break
if myst_dir is None:
raise RuntimeError("Could not locate myst/ot4ml_web.py")
repo_root = myst_dir.parent
thumbnails = repo_root / "notebooks-figures" / "thumbnails"
def show_book_figure(name, width=760):
display(DisplayImage(filename=str(thumbnails / f"{name}.png"), width=width))
This section isolates the test-function viewpoint behind weak discrepancies.
Dual norms generalize the W1 test-function principle and are useful in
statistics because they compare distributions through a restricted
discriminator class.
The Kantorovich--Rubinstein formula for W1 is a special case of a dual
norm. This viewpoint designs weak discrepancies by testing signed differences
of measures against a controlled class of functions.
Symmetry makes the supremum equal to
supf∈B∣∫fdξ∣, while convexity makes B a natural unit ball.
The choice of the test-function class B determines both the topology and the
statistical behavior of the discrepancy Sriperumbudur et al., 2012Sriperumbudur et al., 2009Sriperumbudur et al., 2008.
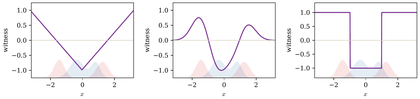
Figure Div compares the optimal test functions selected by several integral probability metrics for the same pair of one-dimensional densities.
show_book_figure("dualnorms-ipm-witnesses")
Dual witnesses for integral probability metrics. The red and blue curves are
two one-dimensional probability densities and the violet curve is a normalized
optimal dual witness fα,β⋆ for the IPM variational problem.
W1 restricts the slope through Kantorovich--Rubinstein duality, MMD
restricts the RKHS norm, and total variation can saturate pointwise and
therefore reacts sharply to signed density differences.
The interactive demo makes the topology visible. As the two densities move, the
total-variation witness jumps with the sign of the density difference, the
Wasserstein witness keeps a unit-slope geometry, and the MMD witness is
smoothed by the kernel bandwidth.
Interactive panel. Use the kernel, bandwidth, and separation controls to see how witness functions detect differences between measures.
The following proposition gives a compact-space criterion. The dual ball
should be rich enough to approximate continuous observables, but compact
enough for weak convergence to imply uniform convergence over the
discriminator class.
Proof
For the first implication, ∥αn−α∥B→0 and the symmetry of
B imply
Taking the limsup as n→∞ and then letting η→0 gives weak
convergence.
For the second implication, assume αn⇀α and choose
a subsequence (αnk)k realizing the limsup of
∥αn−α∥B. Since B is compact and
f↦∫fd(αnk−α) is continuous on B, the supremum
is attained by some fnk∈B. Extract a further subsequence with
fnk→f uniformly. Then
The first term tends to zero by weak convergence and the last two by uniform
convergence. Hence the limsup is zero.
Proof
For p=1, take B={f:Lip(f)≤1}. The span of B contains
all Lipschitz functions, which are dense in C(X) on compact metric
spaces. This gives
W1(αn,α)→0⇒αn⇀α.
Conversely, constants do not change the pairing with αn−α. Fix
x0∈X and normalize potentials by f(x0)=0. The normalized unit
Lipschitz ball is uniformly bounded by diam(X) and
equicontinuous, hence compact in ∥⋅∥∞ by Arzela--Ascoli. The
previous proposition gives W1(αn,α)→0. On compact spaces,
all Wp distances induce the same topology.
Kernel methods turn probability measures into mean elements of a reproducing
kernel Hilbert space. The resulting Hilbertian dual seminorms are quadratic
discrepancies, handled with Euclidean geometry while retaining a weak
test-function interpretation.
Here ``positive definite’’ has its standard kernel-theory meaning of positive
semidefinite. Strict positivity is an additional property, and its absence can
make the induced discrepancy degenerate.
The conditional version is the right notion for probability distances,
because one applies the quadratic form to signed measures
ξ=α−β of total mass zero. Adding a(x)+a(y) to the kernel does
not change ∬K(x,y)dξ(x)dξ(y) on such measures, and many
natural distance kernels are only conditionally positive definite.
These seminorms are usually called maximum mean discrepancies in statistics and
machine learning Gretton et al., 2012Muandet et al., 2017, and kernel
norms in shape analysis Hofmann et al., 2008. For a positive-definite kernel,
if X,X′ are independent with
law α, then
∥α∥K2=EX,X′(K(X,X′)), whenever this expression is finite.
For a conditionally positive kernel, fixing x0∈X and replacing K by
and the last term tends to zero. Conversely, if
αn⇀α, then
αn⊗αn, αn⊗α, and
α⊗α converge weakly on the compact product space. Applying
this to the continuous bounded function K in
Further background on RKHS spaces can be found in
Berlinet & Thomas-Agnan, 2003Hofmann et al., 2008Schölkopf & Smola, 2002.
The preceding discrepancies are widely used as sample-based criteria, both for
testing whether two populations agree and for evaluating generative models.
In the special case where α=∑i=1naiδxi is discrete,
one obtains
where (KX)i,i′=K(xi,xi′). In particular, if
α=∑iaiδxi and
β=∑ibiδxi are supported on the same point cloud, then
∥α−β∥K2=(a−b)⊤KX(a−b), a Euclidean seminorm on
the simplex. It is nondegenerate exactly when r⊤KXr>0 for every
nonzero zero-sum vector r. For two arbitrary discrete measures,
This section develops divergences based on pointwise density ratios. They are
computationally simple and statistically classical, but on nondiscrete spaces
they generally induce a topology much stronger than weak convergence and do
not see small spatial displacements between mutually singular measures.
On a common discrete support, phi-divergences cost only O(n) to evaluate,
but on a continuous space they generally fail to metrize weak convergence.
Bregman divergences provide a different convex construction and should not be
conflated with density-ratio divergences.
If ϕ∞′=+∞, then ϕ grows faster than any linear function
and is called superlinear. Any entropy function induces a ϕ-divergence,
also known as a Ciszar divergence or f-divergence
Ciszár, 1967Ali & Silvey, 1966.
Here α⊥ is the part of α singular with respect to β.
The singular term is the recession contribution of the perspective
functional. It gives the weak-∗ lower-semicontinuous extension of the
density-ratio integral when singular mass appears. This is essential for
linear-growth entropies such as total variation. For superlinear entropies,
such as the usual entropy, ϕ∞′=+∞, so the divergence is
infinite when α is not absolutely continuous with respect to β.
Joint 1-homogeneity follows directly. In the discrete case,
Dϕ(a∣b)=∑iψ(ai,bi), so it is enough to show that ψ is
convex. For v1,v2>0, λ∈[0,1], τ=1−λ, set
Convexity of ϕ gives convexity of ψ on v>0; the case v=0 follows
by lower semicontinuity of the recession value. In the measure case,
weak-∗ lower semicontinuity is the standard theorem for convex integral
functionals with recession extension.
Proof
Let m=α+β and write
a=dα/dm, b=dβ/dm. Using the perspective,
The following examples calibrate the strength of ϕ-divergences. KL is
sensitive to absolute continuity, while total variation gives the strong
topology and therefore behaves very differently from Wasserstein-type weak
metrics.
KL and total variation are two very different ϕ-divergences: the former
is smooth and sensitive to density ratios, whereas the latter is a nonsmooth
norm. Pinsker’s fundamental inequality nevertheless controls the square of the
latter by the former Pinsker, 1964.
Proof
The result is immediate when KL(α∣β)=+∞, so assume
α≪β. Let A be a positive Hahn set for the signed measure
α−β, and set a=α(A) and b=β(A). Since
(α−β)(X)=0,
For fixed b∈(0,1), subtract 2(a−b)2 from the binary relative entropy.
The resulting function has value and first derivative zero at a=b, while
its second derivative is 1/a+1/(1−a)−4≥0. The binary divergence is thus
at least 2(a−b)2=21∥α−β∥TV2. Boundary cases follow
by lower semicontinuity, and the finite-space statement uses
∥α−β∥TV=∥a−b∥ℓ1.
interpolates, up to conventional multiplicative normalizations, between
Pearson’s χ2 divergence at γ=2, Hellinger behavior at
γ=1/2, and, by taking limits, the KL
divergence as γ→1 and the reverse KL or Burg entropy
ϕ0(s)=−logs+s−1 as γ→0. The Hellinger divergence is often
written with ϕH(s)=(s−1)2. If
α=ραλ and β=ρβλ, then
Hellinger(α,β)=∥∥ρα−ρβ∥∥L2(λ). The
Jensen--Shannon distance Endres & Schindelin, 2003Österreicher & Vajda, 2003 is the square root of the symmetrized, bounded
KL-to-the-mixture divergence
Total variation,
generated by ∣s−1∣, is exceptional because it is both a ϕ-divergence
and an integral probability metric.
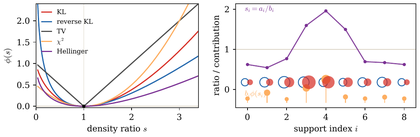
Figure Div places the principal generators and their induced scalar density-ratio penalties side by side, clarifying how their different growth and boundary behavior affect measure comparison.
show_book_figure("dualnorms-phi-generators")
ϕ-divergences through density ratios. The left panel shows normalized
generators for common divergences as functions of s=dα/dβ; all
curves vanish at s=1 up to affine normalization. The right panel shows the
discrete formula Dϕ(a∣b)=∑ibiϕ(ai/bi): hollow blue circles
encode bi, filled red circles encode ai, the violet curve gives the
ratios ai/bi, and orange lollipops show local KL-type contributions.
The interactive demo changes the generator family and the amount of mismatch
between two discrete histograms. The near-zero control deliberately creates
small target bins, making the recession and singularity behavior visible:
ratio-based penalties react to overlap and density ratios rather than to
spatial displacement.
Interactive panel. Use the divergence and ratio controls to compare convex generators and their dual penalties around density ratio one.
The following formula turns a pointwise density-ratio penalty into a dual
optimization problem over test functions. It is the analogue, for
ϕ-divergences, of the Kantorovich dual formula for transport costs.
Proof
First assume ϕ∞′=+∞, so the divergence is infinite unless
α has a density ρ≥0 with respect to β. The
Legendre--Fenchel transform of Dϕ(⋅∣β) is
This is the displayed integral of ϕ∗. For finite ϕ∞′, the
upper endpoint of domϕ∗ encodes the singular recession
term. Convexity, weak-∗ lower semicontinuity, and Fenchel--Moreau then give
the dual expression.
GANs fit naturally into the dual viewpoint: the discriminator is a
parameterized potential and the generator moves a reference measure. This
section first explains the original divergence-based GAN objective, then
contrasts it with integral probability metrics such as MMD and Wasserstein
distances.
The goal is to fit a generative parametric model
αθ=(gθ)♯ζ to empirical data
For fixed θ, restricting the discriminator gives a lower bound on the
exact divergence. This distinction is essential for empirical data: if
β is discrete and αθ is non-atomic, a superlinear
divergence is +∞, while the restricted objective can remain finite.
The original vanilla GAN Goodfellow et al., 2014 corresponds, up to an additive
constant and discriminator reparametrization, to the unscaled
Jensen--Shannon generator ϕJS=2ϕJS,
Thus DϕJS=2JS2. In practice
the min--max problem is solved by alternating stochastic gradient
descent/ascent. Although the unrestricted maximization is concave in f,
neural parametrization generally destroys concavity in ξ; the generator
problem is likewise nonconvex in θ. Density-ratio losses can also
saturate on singular measures: JS2 reaches its maximum
log2 on disjoint supports.
MMD-GANs take B to be a unit ball in an RKHS Dziugaite et al., 2015;
Wasserstein GANs take B to be a Lipschitz ball, following
Kantorovich--Rubinstein duality Arjovsky et al., 2017Frogner et al., 2015. The
advantage is topological: for a continuous kernel on a compact space, the
RKHS unit ball is uniformly bounded and equicontinuous, while the normalized
Lipschitz ball is compact by Arzela--Ascoli. The objective is therefore weakly
continuous. It can
therefore compare singular empirical and generated measures through test
functions instead of requiring pointwise density ratios. The price is that the
discriminator class must be controlled geometrically, either by a kernel norm,
a Lipschitz constraint, or a related regularization.
Ciszár, I. (1967). Information-type measures of difference of probability distributions and indirect observations. Studia Scientiarum Mathematicarum Hungarica, 2, 299–318.
Ali, S. M., & Silvey, S. D. (1966). A general class of coefficients of divergence of one distribution from another. Journal of the Royal Statistical Society. Series B (Methodological), 28(1), 131–142.
Sriperumbudur, B. K., Fukumizu, K., Gretton, A., Schölkopf, B., & Lanckriet, G. R. (2009). On integral probability metrics, ϕ-divergences and binary classification. arXiv Preprint arXiv:0901.2698.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. Advances in Neural Information Processing Systems, 2672–2680.
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein generative adversarial networks. In D. Precup & Y. W. Teh (Eds.), Proceedings of the 34th International Conference on Machine Learning (Vol. 70, pp. 214–223). PMLR. https://proceedings.mlr.press/v70/arjovsky17a.html
Sriperumbudur, B. K., Fukumizu, K., Gretton, A., Schölkopf, B., & Lanckriet, G. R. (2012). On the empirical estimation of integral probability metrics. Electronic Journal of Statistics, 6, 1550–1599.
Sriperumbudur, B. K., Gretton, A., Fukumizu, K., Lanckriet, G., & Schölkopf, B. (2008). Injective Hilbert space embeddings of probability measures. Proceedings of the 21st Annual Conference on Learning Theory, 111–122.
Hanin, L. G. (1992). Kantorovich-Rubinstein norm and its application in the theory of Lipschitz spaces. Proceedings of the American Mathematical Society, 115(2), 345–352.
Lellmann, J., Lorenz, D. A., Schönlieb, C., & Valkonen, T. (2014). Imaging with Kantorovich–Rubinstein discrepancy. SIAM Journal on Imaging Sciences, 7(4), 2833–2859.
Berg, C., Christensen, J. P. R., & Ressel, P. (1984). Harmonic Analysis on Semigroups. Springer Verlag.
Schoenberg, I. J. (1938). Metric spaces and positive definite functions. Transactions of the American Mathematical Society, 44(3), 522–536. 10.1090/S0002-9947-1938-1501980-0
Székely, G. J., & Rizzo, M. L. (2004). Testing for equal distributions in high dimension. InterStat, 5(16.10).
Wendland, H. (2005). Scattered Data Approximation. Cambridge University Press.
Gretton, A., Borgwardt, K. M., Rasch, M. J., Schölkopf, B., & Smola, A. (2012). A kernel two-sample test. Journal of Machine Learning Research, 13(Mar), 723–773.
Muandet, K., Fukumizu, K., Sriperumbudur, B., & Schölkopf, B. (2017). Kernel mean embedding of distributions: a review and beyond. Foundations and Trends in Machine Learning, 10(1–2), 1–141.