Once W2 is a dynamic metric, one can run gradient descent directly on
the space of measures. This chapter derives the formal Wasserstein gradient,
explains the JKO minimizing-movement scheme, records the role of geodesic
convexity in convergence, and then applies the same calculus to mean-field
neural-network training.
from pathlib import Path
import sys
from IPython.display import Image as DisplayImage
from IPython.display import display
here = Path.cwd()
myst_dir = None
for candidate in [here, here.parent, here / "myst", here.parent / "myst", here.parent.parent / "myst"]:
if (candidate / "ot4ml_web.py").exists():
myst_dir = candidate.resolve()
sys.path.insert(0, str(myst_dir))
break
if myst_dir is None:
raise RuntimeError("Could not locate myst/ot4ml_web.py")
repo_root = myst_dir.parent
thumbnails = repo_root / "notebooks-figures" / "thumbnails"
def show_book_figure(name, width=760):
display(DisplayImage(filename=str(thumbnails / f"{name}.png"), width=width))
This first section explains how a variational implicit-Euler step on measures
gives rise, in the small-step limit, to a continuity equation driven by the
Wasserstein gradient of the energy.
We consider a function f(α) and seek a minimizing evolution
(αt)t. The minimizing-movement strategy over a metric space builds a
discrete-time evolution using an implicit Euler scheme:
The implicit Euler scheme has the advantage that it does not require h or
f to be smooth. For f, this is crucial when evolutions over measures may
have densities, atoms or other singular parts.
As τ→0, under suitable conditions on f, (1) defines a
continuous evolution t↦αt. As in the dynamic formulation, this
evolution can be described by a Lagrangian evolution. We use the following
first-variation convention: for any β∈P(Rd) and the signed
zero-mass perturbation η=β−α,
By definition of the Riesz representative for the L2(α) metric, this
representative is ∇δf(α).
The Wasserstein gradient-flow viewpoint already appears in John D. Lafferty’s
PhD work, published as “The Density Manifold and Configuration Space
Quantization”, under the name “density manifold”. It was then systematically
developed by Otto, who exposed the formal Riemannian structure of this space
Otto, 2001. Rigorous metric-space treatments and numerical
JKO schemes can be found in
Ambrosio et al., 2006Benamou et al., 2016Peyré, 2015Gallouët & Monsaingeon, 2017.
A first-order expansion of the JKO step explains why (8)
uses the vector field ∇∇f(α). Write (1) as a
minimization over displacement fields v such that
α=(Id+τv)♯αt:
The same descent principle admits a coordinate-free formulation, which is the
right language for limits of JKO schemes. Let (X,d) be a metric space
and let x:(0,T)→X be an absolutely continuous curve. Its metric
derivative is
for a.e. t. Equivalently, ∣x˙t∣ is the smallest
g∈Lloc1(0,T) such that
d(xs,xt)≤∫stg(r)dr for all 0<s<t<T. If
f:X→(−∞,+∞] is lower semicontinuous, its local metric
slope at a point x with f(x)<+∞ is
When this slope is a strong upper gradient for f, meaning that
∣f(yt)−f(ys)∣≤∫st∣∂f∣(yr)∣y˙r∣dr along absolutely
continuous curves yr, an absolutely continuous curve xt is called a curve
of maximal slope if it satisfies the energy-dissipation inequality
This is the metric-space formulation of gradient descent
Ambrosio et al., 2006; the inequality is stable under weak limits,
while in smooth Hilbert or Wasserstein settings it is usually saturated. In
X=P2(Rd) with d=W2, an absolutely continuous curve admits
a continuity-equation velocity vt and satisfies
∣α˙t∣W2≤∥vt∥L2(αt), with equality for the
minimal velocity. For smooth energies,
∣∂f∣(αt)=∥∇∇f(αt)∥L2(αt), so the
maximal-slope condition reduces to the velocity-field equation
vt=−∇∇f(αt) derived above. The energy consequences of this
viewpoint are used below in Section
Geodesic Convexity and Convergence.
We now detail examples of such Wasserstein gradient flows.
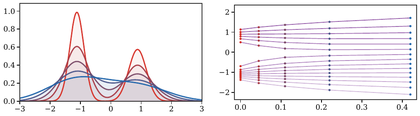
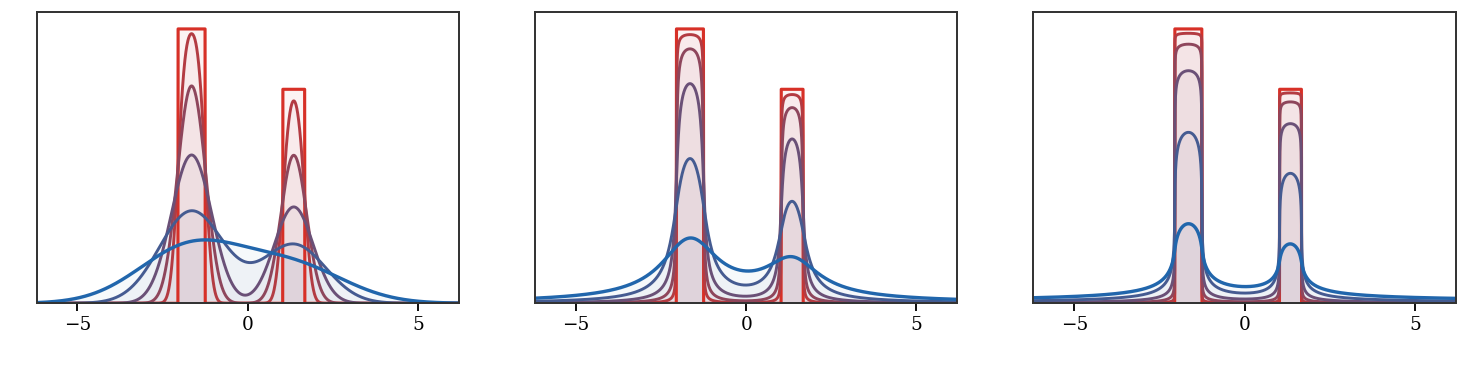
Figure Div shows the same minimizing-movement construction both in density coordinates and through the motion of quantiles.
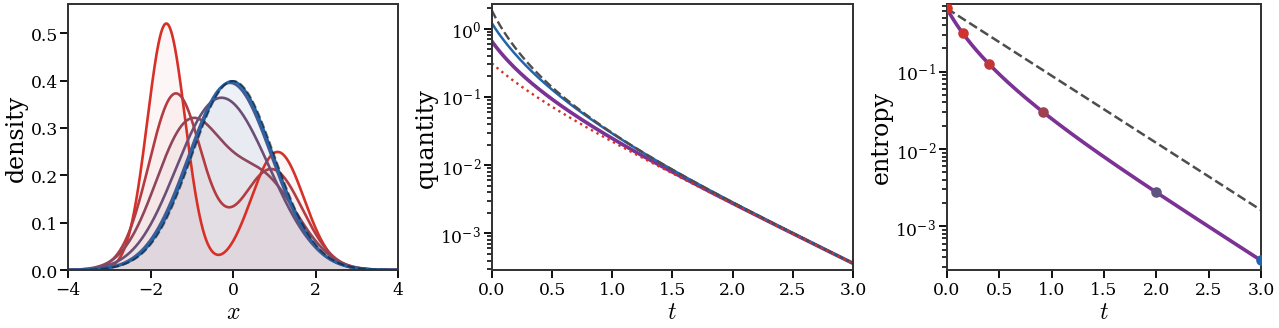
show_book_figure("gradflow-jko-entropy-steps")
JKO minimizing movements for the entropy flow in one dimension. The left
panel displays successive implicit-Euler minimizers for the heat equation,
colored from red to blue. The right panel tracks inverse CDF values
Qt(s)=Ft−1(s) for selected probability levels s, giving a
Lagrangian view of the proximal movement in Wasserstein space.
The interactive demo uses the heat-flow representative of the entropy JKO scheme:
changing the step size changes the spacing between implicit Euler iterates,
while the quantile panel shows how the same movement is seen in Lagrangian
coordinates.
Interactive panel. Use the step size and iteration controls to inspect the JKO scheme as successive implicit steps of the entropy gradient flow.
The JKO viewpoint also handles nonsmooth energies. A basic example is a
linear-in-measure energy, generated by a potential, together with a hard upper
bound on the density,
where Ω⊂Rd is convex and Kκ is assumed
nonempty; if Ω has finite volume, this requires
κ∣Ω∣≥1. The indicator term is not represented by an ordinary
first variation; it contributes the normal cone to Kκ in
the Wasserstein first-order condition. The JKO step becomes the constrained
minimization
This is the mechanism behind macroscopic crowd-motion models with
congestion, where the desired velocity −∇h is projected onto
velocities that do not increase the density beyond the maximal value κMaury et al., 2010Santambrogio, 2018.
The hard cap is not especially benign numerically: the projection in the JKO step and the pressure field below can be difficult to compute accurately. Its advantage is geometric. Proposition Proposition: Geodesic Convexity of Density Caps in Section Geodesic Convexity and Convergence shows that Kκ is geodesically convex, so the indicator of the constraint is harmless for the usual geodesic-convex convergence guarantees.
Formally, the constrained flow contains a pressure field pt, the Lagrange
multiplier of the density cap. With the no-flux boundary condition
ρt∇(h+pt)⋅n=0 on ∂Ω, where n is the
outward normal, this gives the complementarity system
Equivalently, vt=−∇h−∇pt. The pressure vanishes away from
the saturated set and pushes mass away from congested zones where
ρt=κ, keeping the density cap satisfied. For nonsmooth solutions
these conditions are read in the variational sense associated with the normal
cone to Kκ. Thus even when the driving potential
∫hdα is linear, the constraint couples distant particles through
the pressure field.
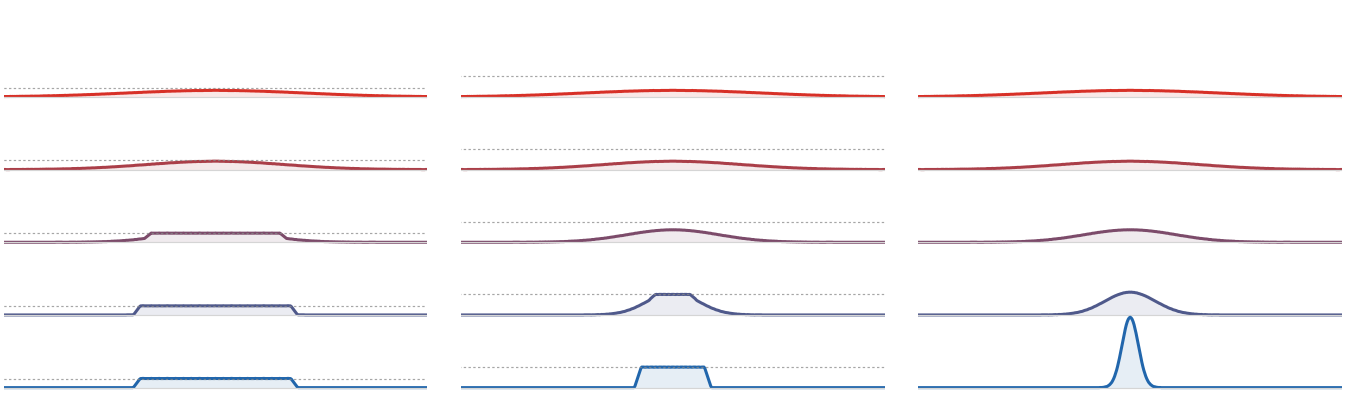
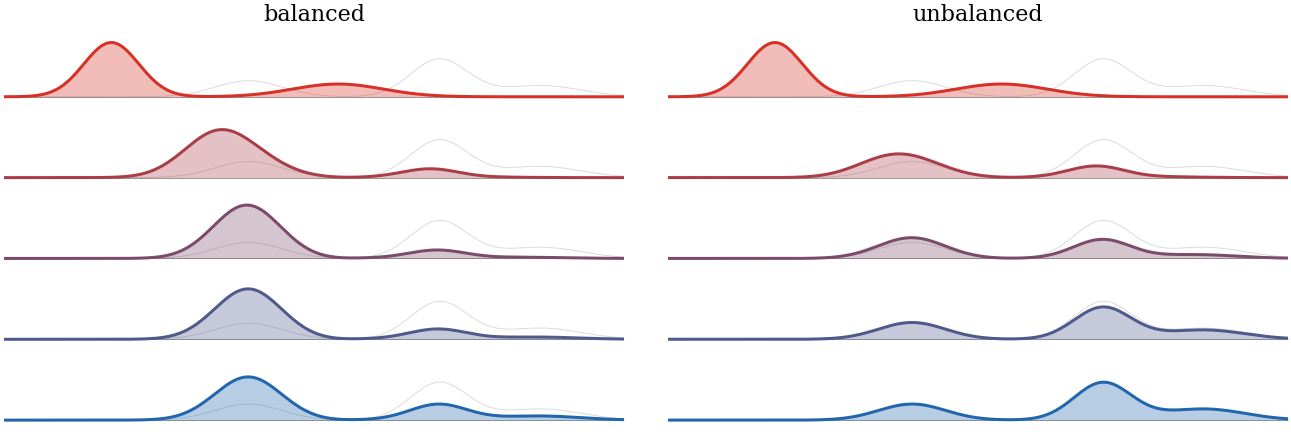
Figure Div shows how decreasing the cap converts free concentration into a saturated region whose width is fixed by mass conservation.
Density-constrained gradient flow for the attractive quadratic potential
h(x)=∥x∥2/2 in one dimension, computed in quantile variables by explicit
Lagrangian descent followed by the isotonic projection enforcing
∂sq≥1/κ. Each panel stacks five times vertically, colored
from red to blue. The dashed gray line marks the maximal density κ for
the constrained runs. A small cap forces the mass to form a wide saturated
block, a medium cap allows a narrower congested region, and the unconstrained
flow concentrates freely near the minimizer of h.
Interactive panel. Vary the density cap, attraction strength, and final time in a projected one-dimensional model of congestion.
Several applications involve several densities living on the same physical
space: chemical species, color channels, cell populations or competing phases.
Let Ω⊂Rd be the physical domain and assume that the component
masses m=(m1,…,mp) are positive and fixed. A convenient
notation is
Since the components are finite measures rather than necessarily probabilities,
the Wasserstein distance below is understood after normalization and with the
natural homogeneous weight:
This is the diagonal, or independent-channel, geometry: each species is
transported by its own scalar Wasserstein metric, while cross-effects may still
enter through the energy or through constraints. In the dynamic language used
later for vector-valued measures, this is the special case of a diagonal
mobility; see Proposition: Diagonal Positive Vector Benamou--Brenier. The corresponding JKO
step for a functional f is
The equations are independent only if f is separable. Otherwise the coupling
enters through the first variations ϕi, not through the metric tensor.
Carlier, Chizat and Laborde
Carlier et al., 2024 use displacement
smoothness of entropic OT to prove well-posedness of Wasserstein gradient flows
that include multi-species systems. Congestion and shared-density variants are
closely related to crowd and traffic models
Maury et al., 2010Carlier et al., 2008Santambrogio, 2018.
A second useful model imposes a pointwise composition constraint. Given a fixed
reference density β=bdx with total mass ∑imi, set
This describes, for instance, several chemical species whose total material
density is prescribed, so that only the composition vector can change. The
constrained JKO step is
with no-flux boundary conditions
ρi∇(ϕi−λt)⋅n=0. The scalar field λt is the
Lagrange multiplier enforcing ∑iρi=b at all times: summing the first
equations and imposing ∂t∑iρi=0 gives the elliptic equation
for λt. For the separable Shannon entropy
When b is constant, for example on a periodic box, the pressure can be chosen
constant and the system reduces to independent heat equations which nevertheless
preserve the pointwise sum ∑iρi=b. This product geometry should be
contrasted with the vector-valued Benamou-Brenier distances of
Vector and Matrix-Valued Measures, where the metric itself can couple
the components through a non-diagonal mobility.
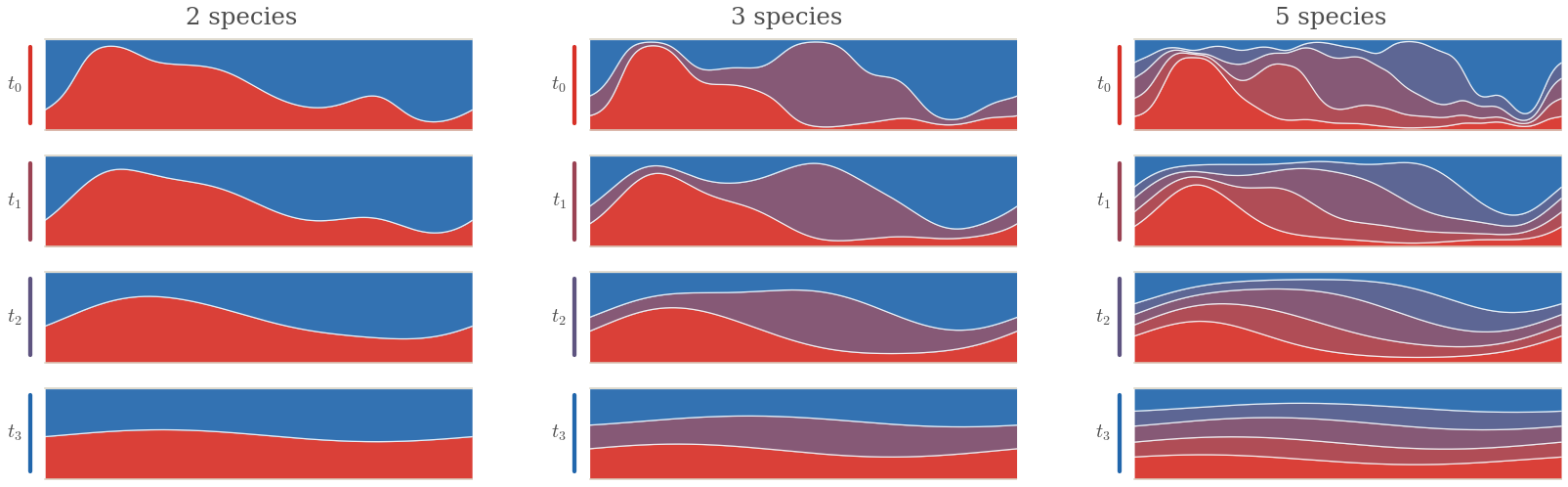
Figure Div visualizes this constant-total-density case for two, three, and five species.
Multi-species entropy flow under the shared-density constraint
∑iρi=1 on the periodic interval. Each row is a time snapshot of the
stacked densities, with the species shown as colored bands and time increasing
from top to bottom. For a constant total density, the pressure in
(37) is constant, so each component follows the
heat equation while the sum of the bands remains exactly flat.
Interactive panel. Change the number of species and diffusion strength while preserving the pointwise total density.
Other entropy functionals lead to nonlinear diffusion equations; finite-volume
and particle discretizations are discussed in
Carrillo et al., 2015Gianazza et al., 2009Maas, 2011Erbar, 2010.
where the pressure P satisfies P′(s)=sg′′(s). For
g(s)=slogs, one has P(s)=s and recovers (38); for
g(s)=sm/(m−1) with m>1, one obtains P(s)=sm up to an additive
constant and the porous-medium equation.
A celebrated theorem by McCann McCann, 1997 states that an
internal energy of the form (40), for
g:R+→R∪{+∞} with g(0)=0, is geodesically convex on
P(Rd) when g is convex and the map
r↦rdg(r−d) is convex and nonincreasing on (0,+∞).
Examples include g(s)=sq for q>1 and Shannon entropy
g(s)=slogs.
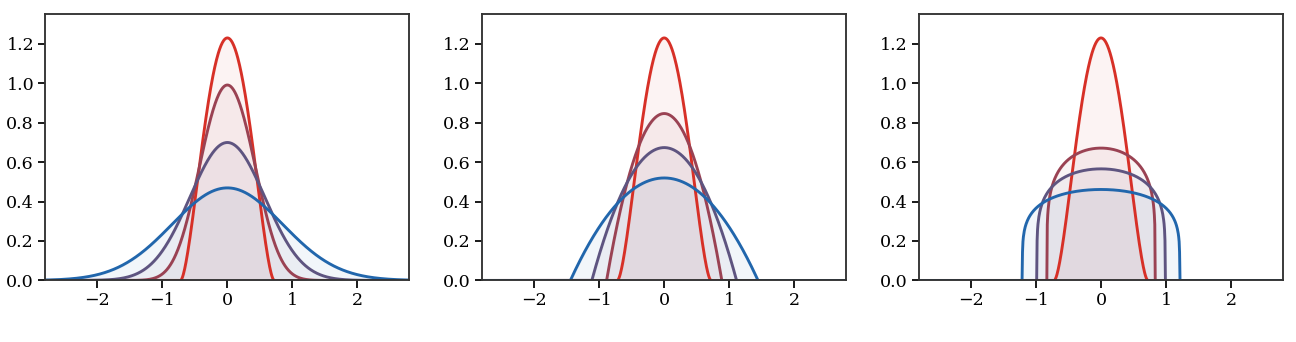
Figure Div contrasts the spreading induced by the linear heat equation with the compactly supported, density-dependent propagation of two porous-medium flows.
Entropy-driven Wasserstein gradient flows from the same compact initial
density. The heat flow is generated by Shannon entropy
g(ρ)=ρlogρ and instantly develops Gaussian tails. The
porous-medium flows use the power entropy g(ρ)=ρm/(m−1), hence
∂tρ=Δ(ρm): the middle panel has m=2, while the right
panel has the stronger nonlinearity m=6, i.e.
∂tρ=Δ(ρ6). Larger powers diffuse mainly where the
density is high, producing a flatter core and a sharper compact free boundary.
The interactive demo isolates the effect of the entropy exponent. The heat curve
keeps Gaussian tails, while increasing m keeps a compact front and spreads
mass mainly from the high-density core.
Interactive panel. Use the diffusion exponent and time controls to compare linear heat flow with nonlinear porous-medium spreading.
If k is positive definite, or more generally conditionally positive definite
on signed measures of zero total mass as for the energy-distance kernel
k(x,y)=−∥x−y∥, and one minimizes the squared kernel discrepancy to a
teacher distribution β, then
Thus MMD-type training energies are exactly an interaction energy plus a
linear potential. The teacher distribution appears through the potential
x↦−2∫k(x,y)dβ(y), and the corresponding empirical
Wasserstein gradient flow is
The first term is a kernelized self-interaction; the second is the attraction
induced by the continuous teacher kernel mean. At the continuum level,
characteristic positive-definite kernels, and the Euclidean energy-distance
kernel on probability measures, have β as the unique minimizer of
∥α−β∥k2. For finitely many particles, however, the flow can
only form a kernelized quadrature of β, and small particle systems may
cover the target modes poorly. The particle-count figure below illustrates
this finite-particle effect.
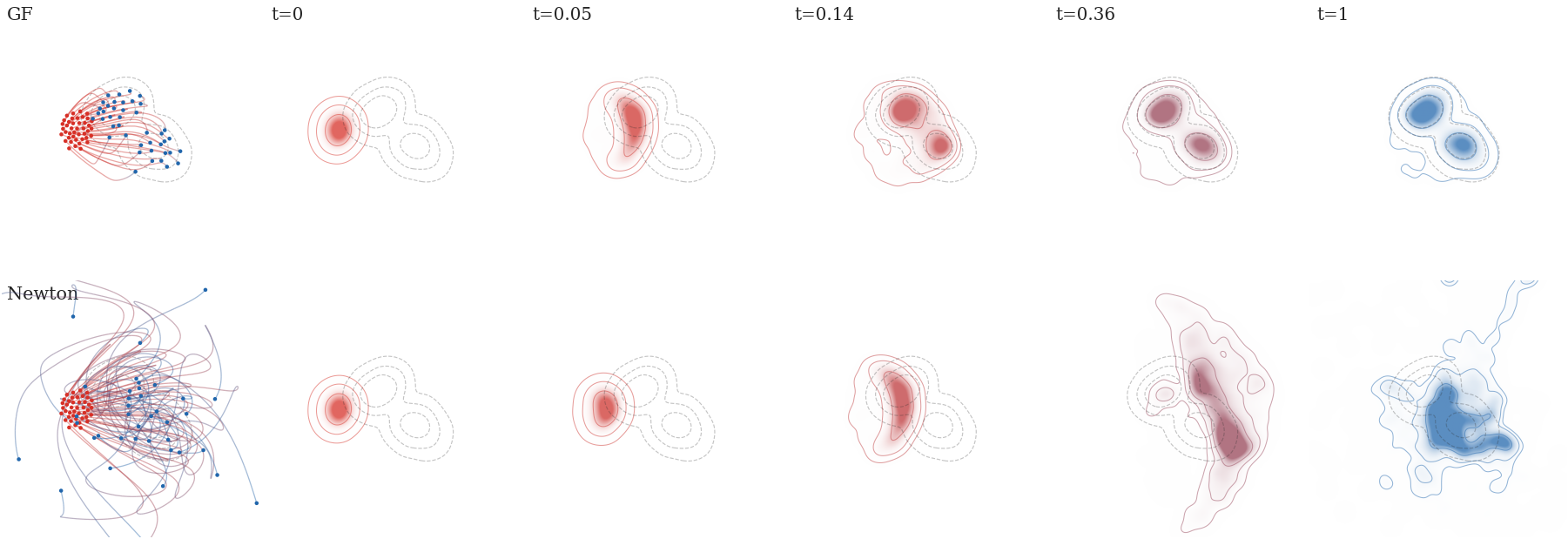
Figure Div illustrates this finite-particle effect.
show_book_figure("gradflow-mmd-particle-count")
Particle count in the deterministic Wasserstein gradient flow of the squared
MMD-type discrepancy to a smooth two-Gaussian teacher distribution, using here
the energy-distance kernel k(x,y)=−∥x−y∥. The teacher itself is shown
only through true density contours, while red dots are a compact shifted
Gaussian initialization placed away from the target, red-to-blue curves show a
thinned subset of particle trajectories, and blue dots show the stabilized
long-time particles. With too few particles, the empirical measure forms a
sparse kernelized quadrature and may under-cover the target modes; increasing
n makes the particle cloud approximate the continuous target geometry more
faithfully.
The interactive demo turns this finite-particle effect into a parameter: increasing
the number of particles makes the same deterministic force field approximate
the teacher geometry more faithfully.
Interactive panel. Use the particle count and kernel controls to see how MMD geometry drives a particle flow toward the target law.
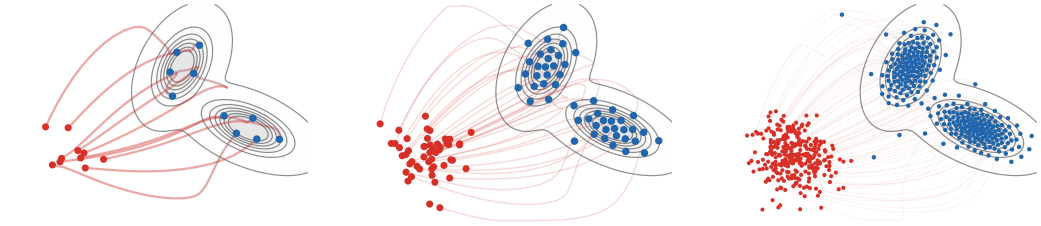
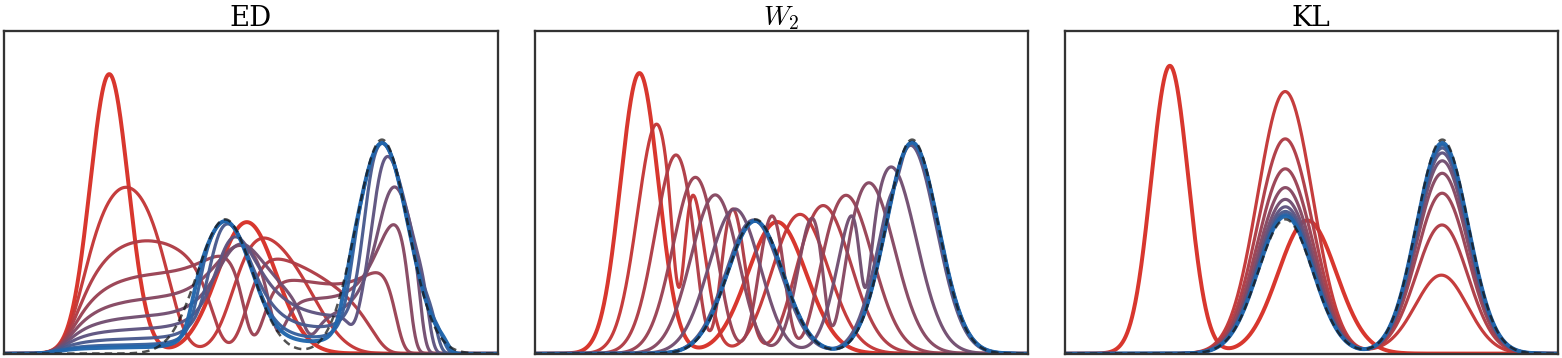
The preceding particle flow minimizes a squared kernel discrepancy.
Figure Div contrasts this
with flows generated by three discrepancies toward the same target. For the
energy distance and W2, the energy is the unsquared distance, so the
Wasserstein velocity is normalized by the current discrepancy value away from
the target. The KL case is different: it is a relative-entropy gradient flow and
therefore follows the Fokker--Planck diffusion toward the target. The comparison
keeps the endpoint fixed and makes the geometry visible through the transient
densities.
Figure Div contrasts this with flows generated by three discrepancies toward the same target.
Wasserstein gradient flows of three discrepancies toward the same
one-dimensional Gaussian-mixture target, shown as a dashed black density. The
source density is also a Gaussian mixture. Red-to-blue curves are snapshots of
αt. The energy-distance and W2 panels use many equal-weight
quantile particles and descend the unsquared distances: in one dimension the
energy distance is obtained from
ED2=2∫∣Fα−Fβ∣2dx, while W2 uses monotone
quantile matching. The relative-entropy panel solves the reversible Fokker--Planck
equation ∂tρ=∂x(ρβ∂x(ρ/ρβ))
by an implicit finite-volume scheme, so that ρβ is the discrete
stationary density.
Figure Div complements this target-matching example by isolating three self-interaction regimes.
Interaction-energy particle flows for three choices of k. A positive
Gaussian kernel k(x,y)=exp(−∥x−y∥2/(2σ2)) produces short-range
repulsion under Wasserstein descent; changing its sign produces attraction
and collapse; adding a quadratic long-range attraction to the repulsive kernel
yields a balanced attraction--repulsion dynamics. The curves use
arclength-based red-to-blue coloring along a longer integration of the coupled
particle ODE (23).
The interactive demo lets the sign and strength of the interaction change without
editing the hidden particle solver. This is the quickest way to see how the
same formal ODE can repel, collapse, or self-organize.
Interactive panel. Use the interaction strength and time controls to watch particles move under attraction, repulsion, and confinement.
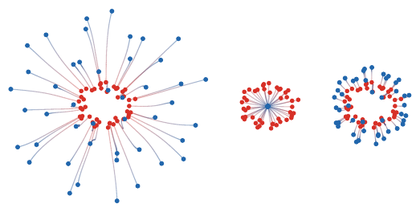
Figure Div then compares the trajectory geometries produced by several discrepancies on common source and target clouds.
Particle trajectories induced by different discrepancy geometries. The red
particles and blue target cloud are the same in all panels. Straight OT
displacement produces rays from an optimal matching; an MMD-type witness field
gives smoother nonlocal forces; the Sinkhorn-divergence force is an entropic,
debiased transport attraction; and the normalized drifting field combines
attraction to data with self-repulsion. The figure is qualitative: it compares
geometric behavior, not solver performance.
The interactive demo keeps the source and target fixed while switching the
discrepancy geometry. The smoothing parameter controls how local or nonlocal
the induced force appears.
Interactive panel. Use the smoothing and geometry controls to compare how different discrepancies reshape the same particle objective.
Deterministic particle flows have stochastic counterparts, where Brownian
noise at the particle level becomes an entropy term at the measure level. If
the drift does not depend on the empirical measure, each particle evolves
independently according to
For finite n, the empirical law αtn is random. Under suitable
Lipschitz, growth and chaotic-initialization assumptions, propagation of
chaos states that finitely many particles become asymptotically independent
as n→∞, all with the same deterministic law ρtdx.
Equivalently, αtn converges in probability to this law. The limiting
density solves the nonlinear Fokker--Planck, or McKean--Vlasov, equation
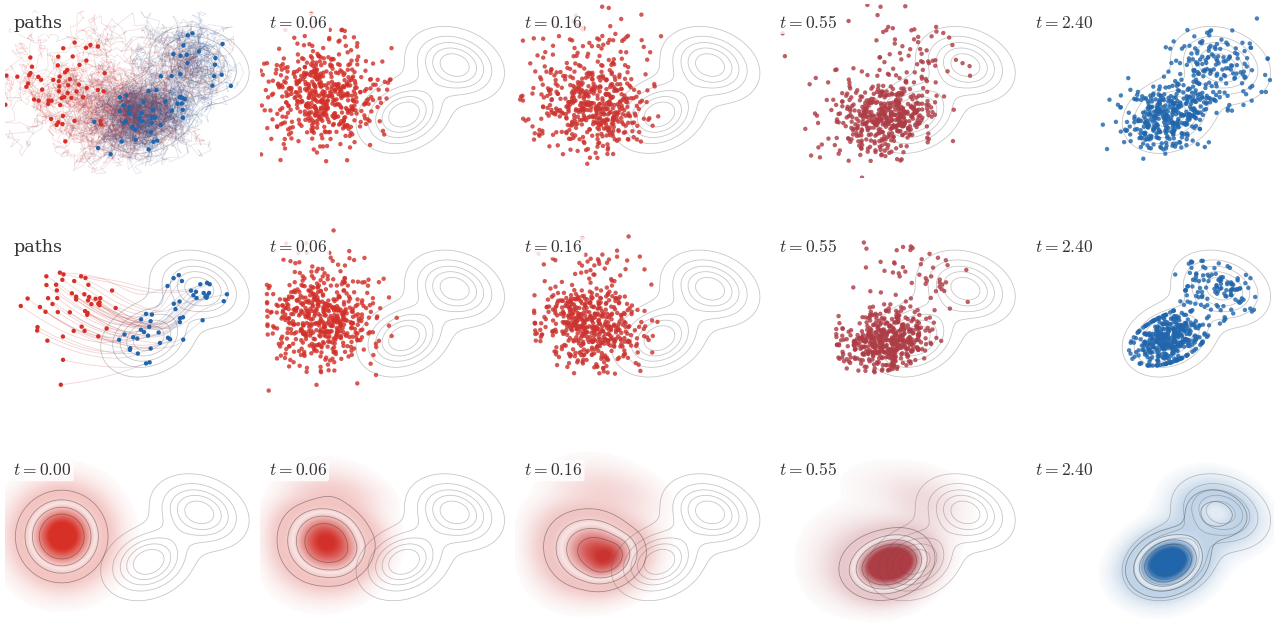
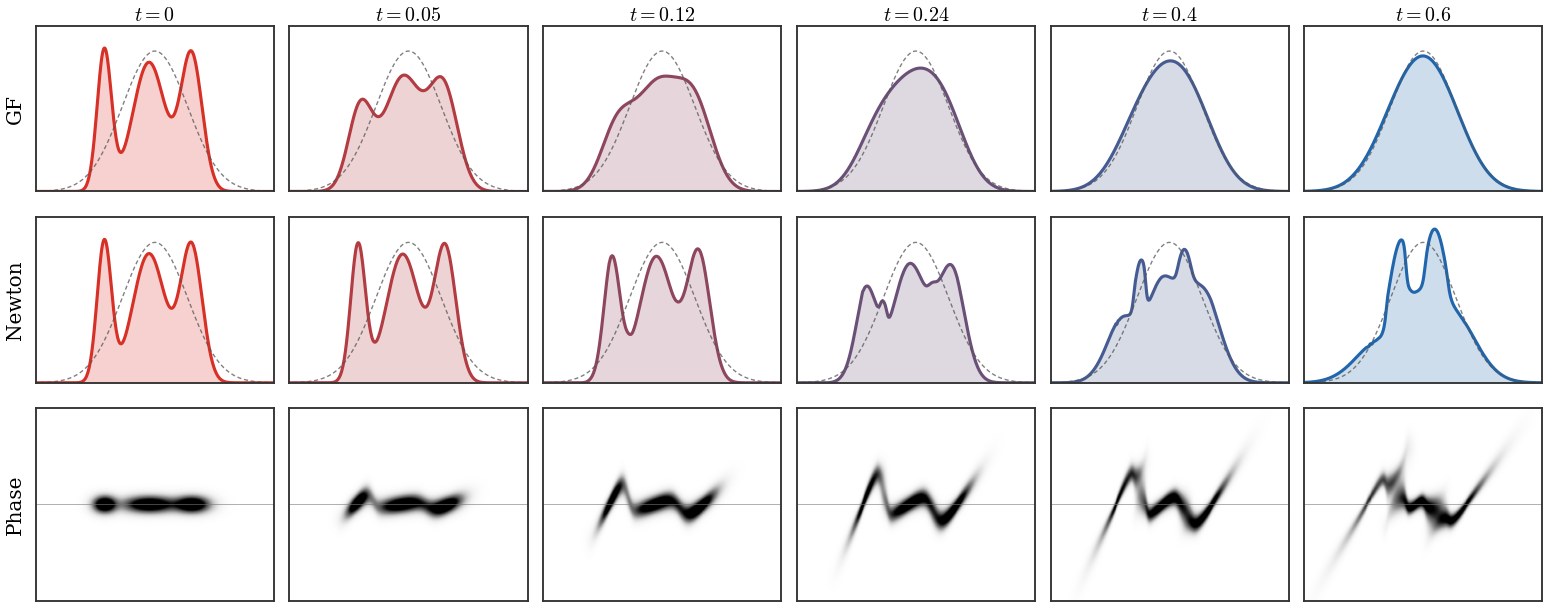
Three numerical representations of the same entropy-regularized
Wasserstein gradient flow of KL(ρ∣β), where β is a
two-Gaussian target shifted to the right of an initially isotropic Gaussian
density. The first row simulates independent Langevin particles and displays
a thinned set of trajectories in the left panel. The second row evolves many
deterministic particles with the score velocity in
(54), estimating ∇logρt
by a kernel-density estimator; only representative trajectories and particle
subsets are displayed. The third row solves the corresponding Fokker--Planck
equation on a grid, starting from the initial density in the left panel. The
remaining columns use front-loaded times, so that the onset of the flow and
the later deformation toward a bimodal law are both visible.
The interactive demo compares three views of the same entropy-regularized
relaxation: stochastic Langevin particles, deterministic score particles, and
a smoothed grid density. The noise slider controls the entropy strength.
Interactive panel. Use the drift and noise controls to compare trajectories, particles, and density evolution for the same Fokker-Planck dynamics.
Geodesic convexity is the convexity notion adapted to Wasserstein geometry. It
is the condition that turns the formal gradient-flow calculus into a
convergence theory.
where P0(x,y)=x and P1(x,y)=y. If the optimal plan is induced by a
Brenier map T, this reduces to ((1−t)Id+tT)♯α0. The coupling
formula matters because geodesics exist even when no Monge map exists, for
instance when a Dirac mass must split.
Proof
Let π be an optimal coupling between α0 and α1, and write
Xt=(1−t)X0+tX1 under (X0,X1)∼π. Convexity of h gives the
linear-energy statement after integration; testing on Dirac masses gives the
converse.
For the polynomial statement, take k independent copies of the same optimal
coupling. Then
Xtℓ=(1−t)X0ℓ+tX1ℓ, and convexity of Hk on the product
space gives
Integrating over the product coupling proves the claim.
The polynomial criterion is useful but restrictive for kernel losses. The
RKHS/MMD kernels introduced in Section Dual RKHS Norms and Maximum Mean Discrepancies are usually chosen
for positive definiteness and statistical smoothing, not for convexity as
functions of (x,y). Gaussian and Laplace kernels, for instance, are not
convex on Rd×Rd, so positive definiteness of k does not imply
that α↦MMDk2(α,β) is geodesically convex. In fact, such
MMD losses are not geodesically convex in general. One-dimensional monotone
transport gives a sharper exception for distance-type kernels, because ordered
quantiles keep the sign of pairwise differences fixed along geodesics; this is
the one-dimensional displacement-convexity mechanism emphasized, for instance,
in Santambrogio, 2015.
Proof
Let Q0,Q1 be the quantile functions of α0,α1, and let
Qt=(1−t)Q0+tQ1 be the quantile function of the one-dimensional W2
geodesic αt. For r>s, monotonicity gives
Qi(r)−Qi(s)≥0 for i=0,1, and hence
Convexity of φ on R+ gives the desired convexity after
integration.
Conversely, test geodesic convexity on two-point measures
αi=21(δ0+δai), with ai≥0. Their monotone
geodesic is
αt=21(δ0+δ(1−t)a0+ta1). Since
geodesic convexity of Iφ gives the ordinary convexity
inequality for φ on R+, after the identical
41φ(0) terms cancel.
For the energy distance, the function φ(r)=−r is affine on R+, so
the self-interaction −∬∣x−y∣dα(x)dα(y) is affine along
one-dimensional Wasserstein geodesics even though z↦−∣z∣ is not convex
on R. Write Qβ for the quantile function of β. Expanding the
MMD and dropping the term depending only on β gives
Here the constant is independent of α. The positive cross-distance term
is convex in Qα, since the absolute value is convex and Qt is affine
in t. The self-distance term is affine along quantile geodesics because
This one-dimensional result is the mechanism behind the favorable behavior of
energy-distance particle flows discussed earlier in this chapter and in recent
analyses of distance-kernel MMD flows
Duong et al., 2024. It should not be read as a
general MMD statement: for a typical positive definite kernel k, the
decomposition
contains neither a convex self-interaction nor a convex cross term along
Wasserstein geodesics.
Internal energies require a different mechanism: convexity is hidden in the
Jacobian determinant of the transport map, not in a pointwise convex integrand
along particles. The precise criterion is McCann’s displacement-convexity
theorem.
Proof
For smooth positive densities, let T be the Brenier map from
α0=ρ0dx to α1=ρ1dx, set
Tt=(1−t)Id+tT, and write
Jt=det((1−t)I+t∇T). Since
ρt(Tt)Jt=ρ0 and det1/d is concave,
The monotonicity and convexity of ψ then yield the geodesic convexity
inequality. The general case follows by approximation and lower
semicontinuity.
This theorem applies to g(s)=slogs and to porous-medium powers
g(s)=sm/(m−1), m>1, and more generally to the fast-diffusion range
m≥1−1/d when the energy is well defined, with m=1 understood as
the entropy limit. The same criterion also clarifies which Csiszár
divergences inherit displacement convexity from an internal-energy structure.
Proof
For the flat reference case, write α=ρdx. Up to affine terms in
ρ, which only add constants on probability measures, the integrand
bϕm(ρ/b) has non-affine part b1−mρm/(m(m−1)) for
m=1, and ρlogρ for m=1. For m=1, McCann’s criterion gives
ψ(r)=−dlogr. For m=1, the transformed non-affine part is, up to the
irrelevant factor b1−m,
For each x, the function t↦V(Tt(x)) is convex, and
t↦−logJt(x) is convex because logdet is concave on positive
definite matrices. Since m−1>0, the exponential of their sum is convex in
t. Integrating gives geodesic convexity. The nonsmooth case follows by
approximation.
Geodesic convexity is also useful for hard constraints. If a feasible set is geodesically convex, then adding its indicator to an energy does not destroy the variational structure used by minimizing movements and convergence arguments. The density cap from (26) is the model example: it is numerically delicate, because one must compute a projection or a pressure, but it is geometrically compatible with Wasserstein descent.
Proof
Assume first that the endpoints have smooth positive densities
αi=ρidx with
ρi≤κ, and let T=∇φ be the Brenier map from
α0 to α1. The interpolation is
αt=((1−t)Id+tT)♯α0, and
so ρt≤κ. For general endpoints, approximate
α0,α1 by smooth positive densities bounded by κ+η,
apply the estimate above, and let η↓0 using stability of
optimal plans and lower semicontinuity of the L∞ bound. This is the
standard density-bound argument in McCann’s displacement-convexity theory
McCann, 1997.
Proof of the Wasserstein estimate
Write
αt=((1−t)P0+tP1)♯π01 with π01 optimal between
α0 and α1. Fix t, put Z=(1−t)X0+tX1, take an optimal
coupling between αt and β, and glue it with a disintegration of
π01 over Z. This gives random variables (X0,X1,Y) such that
((Z,Y)) is optimal between αt and β, while (X0,X1) is
optimal between α0 and α1. Since
(Xi,Y) are admissible couplings between αi and β,
then gives the claim after taking expectations. The sliced estimate follows by
repeating the same argument after projection, using the projected coupling
induced by π01, and integrating over directions.
Before asking for convergence rates, one should first extract the basic
information already contained in energy dissipation. For the classical gradient
flow of a smooth function h:Rd→R, x˙t=−∇h(xt), the chain
rule gives
The Wasserstein analogue uses the metric derivative
∣α˙t∣W2 of an absolutely continuous curve. The following
estimate isolates the only ingredient needed at this stage: energy dissipation
controls the metric length of the path.
The exact energy-dissipation identity substitutes the last integral by
f(αs)−f(αt). In the metric theory of curves of maximal slope
Ambrosio et al., 2006Santambrogio, 2015, the energy-dissipation
inequality gives instead
21∫st∣α˙r∣W22dr≤f(αs)−f(αt),
and the same argument yields the additional factor 2.
Proposition Proposition: Finite Metric Length from Dissipation is weaker than a convergence
rate: it does not identify a minimizer and it gives no decay law. It does,
however, rule out escape to infinity in finite metric time whenever the energy is
bounded below on finite time intervals. Indeed the trajectory segment remains in
the W2-ball centered at αs with radius given by
(105). It also gives a concrete modulus of
continuity. If mT≤f(αr) for 0≤r≤T, then for
0≤s<t≤T,
with an additional factor 2 under the energy-dissipation inequality.
Thus an energy-dissipating trajectory is 1/2-Hölder continuous as a curve in
Wasserstein space on every time interval where the energy remains bounded from
below. Non-coercivity of the objective means that sublevel sets need not be
compact, but an energy-dissipating curve still cannot travel an infinite
W2-distance in finite time without an infinite energy drop. The convex estimate below adds a first quantitative conclusion under geodesic
convexity; the PL viewpoint then gives sharper coercive rates toward minimizers.
Proof
The chain rule and the formal Wasserstein-gradient proposition give
In general, analyzing (8) is delicate. Geodesic convexity
gives the familiar convex-gradient-flow picture, but rates are driven more
directly by a first-order coercivity inequality. The relevant quantity is the
squared Wasserstein slope
in the smooth formal setting. Along a smooth gradient flow, this is both the
squared metric speed and the energy-dissipation term.
The terminology mirrors the finite-dimensional Polyak-Łojasiewicz condition
introduced by Polyak Polyak, 1963 and now standard in
nonconvex optimization Karimi et al., 2016. It is also part of
the broader family of Łojasiewicz and Kurdyka-Łojasiewicz gradient inequalities
used to prove convergence of dissipative dynamics
Attouch et al., 2010Hauer & Mazón, 2019Dello Schiavo et al., 2024.
The Wasserstein version simply replaces the Euclidean gradient norm by the
metric slope associated with W2.
Proof
The energy estimate is immediate from the full energy-dissipation identity and
the Wasserstein-PL inequality:
If E vanishes on a subinterval, then the flow is stationary there, and the
same estimate follows by applying the argument on the part where E>0. Since
Wasserstein distance is bounded by metric length, the same upper bound controls
W2(αs,αt).
Letting t→+∞, the energy estimate gives E(t)→0, and the length
estimate shows that the tail of (αt)t is Cauchy. Since
(P2(Rd),W2) is complete, there is a limit α∞. Lower
semicontinuity yields
Combining this with the exponential energy decay gives the stated distance
rate. The distance-to-the-set bound follows because α∞ is one
minimizer.
The exponential decay of the energy gap is the direct metric-gradient-flow
analogue of the classical PL argument. The tail-length estimate used in the
theorem above is a convenient way to turn this energy decay into a
W2-distance-to-Argminf bound; this exact formulation was
communicated to us by Raphaël Barboni. More refined accounts of KL/PL-type
inequalities, global convergence and rates for gradient flows and proximal point
sequences in general metric spaces are given by Hauer and Mazón
Hauer & Mazón, 2019 and by Dello Schiavo, Maas and Pedrotti
Dello Schiavo et al., 2024.
Strong geodesic convexity is the cleanest geometric assumption behind the
Wasserstein-PL inequality: it turns displacement convexity into a quantitative
lower bound on the metric slope, so that the abstract convergence theorem above
applies automatically.
Equivalently, g≤ar−λr2/2. Maximizing the right-hand side over
r≥0 gives g≤a2/(2λ), which is the desired PL inequality.
Together, Proposition Proposition: Strong Geodesic Convexity Implies Wasserstein-PL and
Theorem Theorem: Wasserstein-PL Convergence recover the exponential energy
rate e−2λt for positively geodesically convex Wasserstein gradient
flows, and also give the distance rate e−λt toward the minimizer
selected by the flow. The PL formulation is useful because it separates the
first-order energy-dissipation mechanism from the stronger curvature
requirement of geodesic convexity.
The PL condition is the quadratic case of a broader slope--energy principle.
The classical starting point is the gradient inequality of Lojasiewicz for
real-analytic functions Łojasiewicz, 1963, later
extended by Kurdyka to functions definable in o-minimal structures
Kurdyka, 1998. Modern nonsmooth optimization uses
the same idea as the Kurdyka-Lojasiewicz property to prove convergence of
descent algorithms and subgradient flows; see, for instance, Bolte,
Daniilidis, Ley and Mazet Bolte et al., 2010 and
Attouch, Bolte, Redont and Soubeyran Attouch et al., 2010. For
displacement-convex functionals, Bolte and Blanchet
Bolte & Blanchet, 2016 develop a family of
Lojasiewicz-type functional inequalities in Wasserstein space and relate them
to convergence of the associated gradient dynamics. In the metric-space setting
relevant here, the Euclidean gradient norm is replaced by the metric slope, as
in the general theory of curves of maximal slope and recent KL/PL convergence
results for metric gradient flows
Hauer & Mazón, 2019Dello Schiavo et al., 2024.
The Kurdyka-Lojasiewicz viewpoint replaces the linear relation between the
energy gap and the squared slope by a power law. It is useful for degenerate
convex landscapes, homogeneous energies, and transport discrepancies whose
minimizers form a flat set; in those cases the same energy-dissipation
computation still gives convergence, but typically with polynomial rather than
exponential rates. We use “KL” in this paragraph for Kurdyka-Lojasiewicz, not
for Kullback-Leibler divergence.
Proof
If E reaches zero at some time, then the flow is already at a global
minimizer. Indeed, the integrated energy-dissipation identity forces both
∣α˙t∣ and ∣∂f∣(αt) to vanish afterwards. We therefore
argue on intervals where E>0. For a.e. t,
Letting T→+∞ shows that the tail has finite length. Hence
(αt)t is Cauchy in (P2(Rd),W2), which is complete, and
converges to some α∞. Since the energy bound gives E(t)→0,
lower semicontinuity gives f(α∞)=f⋆. The distance to
α∞ is bounded by the remaining tail length.
Theorem Theorem: Sublinear Convergence Under Wasserstein-KL is the Wasserstein analogue of the
standard KL-rate argument for curves of maximal slope in metric spaces; see
Attouch, Bolte and Svaiter Attouch et al., 2010, Hauer and Mazon
Hauer & Mazón, 2019, and Dello Schiavo, Maas and Pedrotti
Dello Schiavo et al., 2024. The endpoint
θ=1/2 is the PL theorem above. Exponents θ>1/2 correspond to
flatter landscapes and slower polynomial rates; formally, θ<1/2 would
instead lead to finite-time convergence in the scalar comparison inequality.
The same language is not restricted to subsets of Rd. If
(X,d,m) is a geodesic metric-measure space, W2
geodesics can be defined by transporting each pair of endpoints along metric
geodesics, or more intrinsically by dynamical optimal plans on path space.
Given a reference measure m, the entropy relative to
m is
On a smooth Riemannian manifold (M,g), the Ricci curvature tensor
Ricg is the trace of the Riemann curvature tensor. The lower
bound Ricg≥λg means that
Ricg(v,v)≥λ∣v∣g2 for every tangent vector v. The
fundamental link between curvature and optimal transport is that this tensor
lower bound is exactly encoded by geodesic convexity of entropy.
This equivalence was developed in the smooth Riemannian setting by
Cordero-Erausquin, McCann and Schmuckenschlaeger and by von Renesse and Sturm
Cordero-Erausquin et al., 2001Renesse & Sturm, 2005; it is a central
theme of the optimal-transport approach to curvature in Villani’s monograph
Villani, 2009. Lott--Villani and Sturm then used the same
entropy-convexity principle to define synthetic lower Ricci curvature bounds
on metric-measure spaces
Lott & Villani, 2009Sturm, 2006Sturm, 2006. Outside this
convex, curvature-controlled regime, such as in the mean-field
neural-network example below, the flow may still be informative but its
convergence analysis requires problem-specific arguments.
Optimal transport proves inequalities by turning comparison into geometry. One
transports a density by a monotone or Brenier map, interpolates along the
resulting rays, and converts concavity of a Jacobian determinant or convexity of
an energy into an integral estimate. The first two examples illustrate this
geometric mechanism. The remainder concerns entropy, where comparing an energy
gap with its squared Wasserstein slope gives a Wasserstein-PL inequality and
hence convergence rates through Theorem
Theorem: Wasserstein-PL Convergence. We work in the smooth Euclidean setting
so the main calculation remains visible; standard approximation arguments
recover the usual Borel and Sobolev formulations. Systematic accounts include
McCann’s displacement-convexity principle, the Riemannian interpolation
inequalities of Cordero-Erausquin, McCann and Schmuckenschläger, and Villani’s
treatment of concentration and functional inequalities
McCann, 1997Cordero-Erausquin et al., 2001Villani, 2009.
The most geometric use of OT is to prove that transporting two uniform measures
and looking at the interpolated support increases volume at least concavely.
The perimeter inequality is then obtained by differentiating this volume
estimate after adding a small ball.
Proof
We first give the argument for regular sets, the general Borel case following
by approximation from inside and outside. Let α and β be the
uniform probability measures on A and B, and let T=∇ϕ be the
Brenier map with T♯α=β. The interpolating map
Tt=(1−t)Id+tT sends α to a measure αt
supported in (1−t)A+tB. At points where T is differentiable,
The change-of-variables identity for the uniform measures gives
det(DT)=Vol(B)/Vol(A) almost everywhere. If
ρt denotes the density of αt, a second application of the same
formula gives
where
ct=(1−t)Vol(A)1/d+tVol(B)1/d. Since
ρt≤ct−d almost everywhere, while αt has unit mass and is
supported in (1−t)A+tB. Therefore
Vol((1−t)A+tB)≥ctd, which is the displayed
Brunn-Minkowski inequality.
For isoperimetry, use the homogeneity of Brunn-Minkowski and apply it to A
and ϵB1. Writing A+ϵB1 for the parallel set gives
Using
Vol(A+ϵB1)=Vol(A)+ϵPer(A)+o(ϵ) and
differentiating at ϵ=0 yields the claimed perimeter bound. Balls attain
equality, so the constant is optimal.
Figure Div isolates the
determinant-concavity step in the special case where the optimal map is affine.
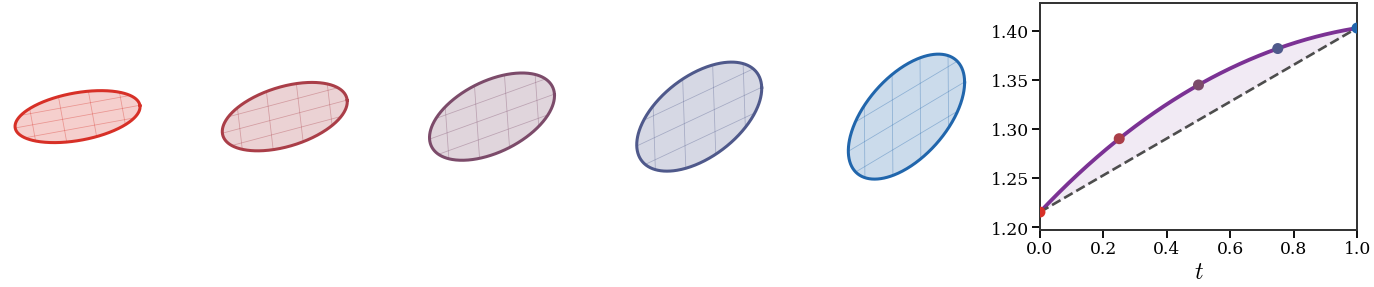
Interactive panel. Move the affine stretch and interpolation time to see determinant concavity behind the Brunn-Minkowski transport proof.
:class: ot4ml-book-figure
show_book_figure("gradflow-brunn-minkowski-ot")
Brunn-Minkowski through an affine optimal-transport interpolation between two
ellipses. For ellipses, the Brenier map is affine, so the transported support
Tt(A) remains an ellipse and its area is computed exactly from the
determinant of (1−t)Id+tDT. The right panel shows that
∣Tt(A)∣1/2 lies above the linear interpolation of the endpoint
square-root areas, which is the two-dimensional determinant concavity behind
the proof of Brunn-Minkowski.
### Prékopa-Leindler
The functional analogue of Brunn-Minkowski replaces sets by densities. The
transport proof is the same argument with the Jacobian no longer constant.
(prop-ot-prekopa-leindler)=
:::{admonition} Proposition: Prékopa-Leindler Inequality
:class: important
Let $u,v,w:\RR^d\to[0,+\infty)$ be integrable, and let $t\in[0,1]$. Assume that
```{math}
w((1-t)x+ty)\geq u(x)^{1-t}v(y)^t
\qquad
\text{for all }x,y\in\RR^d.
```
Then
```{math}
\int_{\RR^d} w
\geq
\left(\int_{\RR^d}u\right)^{1-t}
\left(\int_{\RR^d}v\right)^t .
```
Proof
The endpoint cases are immediate, so fix t∈(0,1). Set U=∫u and
V=∫v. If U=0 or V=0, the conclusion is trivial; hence assume
U,V>0. Let
α=(u/U)dx and β=(v/V)dx, and let T be the Brenier map from
α to β. Put Tt=(1−t)Id+tT. On a smooth
positive regularization, Tt is the gradient of a strictly convex function
and is therefore one-to-one almost everywhere. The area formula gives
For each eigenvalue s≥0 of DT, weighted arithmetic-geometric mean gives
(1−t)+ts≥st. Hence
det((1−t)Id+tDT)≥det(DT)t. Combining this with the
assumption on w gives
The logarithmic Sobolev inequality, introduced by Gross
Gross, 1975, controls relative entropy by its dissipation. Let
β=ρβdx be a reference probability measure. For
α=hβ, define
with the lower-semicontinuous convention I(α∣β)=+∞
outside its natural domain. The measure β satisfies a logarithmic Sobolev
inequality with constant λ>0 if
KL(α∣β)≤2λ1I(α∣β)for every probability measure α.
This is a coercivity property of the reference measure, not a universal
inequality. Positive curvature of the potential is a standard sufficient
condition.
With r=W2(α,β) and
s=I(α∣β), the inequality
rs−λr2/2≤s2/(2λ) gives the claim. Approximation yields the
standard nonsmooth statement. This is the Otto--Villani transport route
Otto & Villani, 2000; the Bakry--Emery Γ2 calculus
gives the same criterion directly
Bakry & Émery, 1985Bakry et al., 2014.
Transport also gives a short proof of the sharp Gaussian logarithmic Sobolev
inequality. In Cordero-Erausquin’s argument
Cordero-Erausquin, 2002, the Jacobian equation for
the Brenier map is bounded by
logdetA≤tr(A−Id), and Gaussian integration
by parts converts the trace term into Fisher information.
Proof
Let α=ργd, and let T=∇ϕ be the Brenier map with
T♯α=γd. Write T(x)=x+θ(x). The Monge-Ampère equation
reads
Thus the Gaussian logarithmic Sobolev inequality is exactly the
Wasserstein-PL inequality for f with constant 1. This interpretation turns
the static estimate into exponential convergence of the Ornstein-Uhlenbeck flow.
Poincaré as a Linearized Wasserstein-PL Inequality¶
Many quadratic functional inequalities arise by zooming in on a nonlinear
slope inequality near equilibrium. Assume that β minimizes an energy f, and
let ξ be a smooth bounded density modulation with ∫ξdβ=0.
For ∣ϵ∣ small enough, set
whenever these finite limits exist. The first is the quadratic part of the
energy gap and the second is the quadratic part of the squared Wasserstein
slope. Their comparison is the linearized Wasserstein-PL inequality.
Inserting these expansions in the logarithmic Sobolev inequality and letting
ϵ→0 gives the Poincaré inequality. The last assertion is the usual
Bakry-Emery implication from λ-convexity of V to the logarithmic
Sobolev inequality.
If dβ=ρβdx=Z−1e−Vdx, the Poincaré inequality is
equivalently a spectral gap for the β-weighted Laplacian
Thus Poincaré says that the bottom of the spectrum of −Lβ on mean-zero
functions is at least λ. When the resolvent is compact, this is the
first nonzero eigenvalue; on a noncompact space the spectral gap need not be
attained by an eigenfunction. This interpretation, classical for reversible
Markov diffusion generators
Ledoux, 2001Bakry et al., 2014, is the
infinitesimal shadow of the nonlinear Wasserstein-PL/log-Sobolev inequality.
This interpretation becomes exact after freezing the Wasserstein mobility at
equilibrium. For a mean-zero density perturbation h˙, define
For
E2(h)=21χ2(hβ∣β)=21∫(h−1)2dβ, integration
by parts gives
∣∂E2∣−1,β2=∫∥∇h∥2dβ. Thus Poincaré is
exactly PL for E2 in the linearized Wasserstein geometry. It is not the full
W2-PL inequality for the same energy: the nonlinear mobility is
hβ, and the corresponding squared slope is
∫h∥∇h∥2dβ.
The distance estimate in Theorem Theorem: Wasserstein-PL Convergence reveals
the general principle: logarithmic Sobolev with constant λ yields
W22(α,β)≤2KL(α∣β)/λ. This is the
Otto-Villani implication from logarithmic Sobolev to Talagrand’s T2
inequality Otto & Villani, 2000. For the standard Gaussian,
the same Jacobian estimate gives a direct sharp proof of Talagrand’s original
result
Talagrand, 1996Cordero-Erausquin, 2002Villani, 2009.
Proof
The infinite-entropy case is immediate. If α=ργd with ρ
smooth and positive, let T=∇ϕ be the Brenier map with
T♯γd=α, and write T(x)=x+θ(x). The change of variables
gives
The previous two Gaussian inequalities are not isolated facts. The HWI
inequality of Otto and Villani Otto & Villani, 2000 compares
three quantities at once: the entropy H, the Wasserstein distance W, and
the Fisher information I. It is one of the cleanest examples where
displacement convexity turns into a functional inequality.
Cauchy--Schwarz and
∫∥T−Id∥2dα=W22(α,β) give the
announced bound. The general case follows by standard approximation and lower
semicontinuity of entropy, Fisher information, and W2.
When λ>0, the HWI inequality is a bridge from curvature to PL. It is
not itself a PL inequality because it still contains the distance term
W2(α,β). Optimizing the right-hand side, or simply using
Young’s inequality rs−λr2/2≤s2/(2λ), gives the logarithmic
Sobolev estimate
Since I(⋅∣β)=∣∂KL(⋅∣β)∣2, this is the
Wasserstein-PL inequality with constant λ. This is precisely the
curvature-to-logarithmic-Sobolev implication used above; the entropy-decay
proposition below then converts it into exponential Fokker-Planck convergence.
Figure Div shows these inequalities on an
exact one-dimensional Ornstein-Uhlenbeck relaxation, where all quantities can be
evaluated accurately by grid quadrature and quantile inversion.
Interactive panel. Change the final time and mixture skew to recompute entropy, Fisher information, Wasserstein distance, and the HWI/log-Sobolev guides along an OU flow.
:class: ot4ml-book-figure
show_book_figure("gradflow-hwi-entropy-decay")
Functional inequalities along the Ornstein-Uhlenbeck flow from a
one-dimensional Gaussian mixture to the standard Gaussian. The left panel shows
the density relaxation, with the Gaussian target as a dashed curve. The middle
panel compares H=KL(αt∣γ1) with the HWI upper bound
WI−W2/2, the logarithmic-Sobolev upper bound I/2, and the Talagrand
lower bound W2/2, where W=W2(αt,γ1) and
I=I(αt∣γ1). The right panel displays the dynamic
consequence H(t)≤H(0)e−2t.
### Entropy Decay Along the Fokker-Planck Flow
Functional inequalities become convergence rates once they are combined with
the energy-dissipation identity of a Wasserstein gradient flow. In the notation
of Definition {ref}`def-wasserstein-pl`, log-Sobolev is simply the PL
inequality for relative entropy, and Theorem
{ref}`thm-wasserstein-pl-convergence` gives both energy decay and
convergence in $\Wass_2$. This is why the previous inequalities are not merely
static estimates: they quantify relaxation of the Fokker-Planck equation.
The logarithmic Sobolev assumption below is the curvature-controlled mechanism
introduced above. With the convention used here, the standard Gaussian
$\gamma_d=\mathcal N(0,\Id)$ satisfies it with $\lambda=1$, exactly as in
{ref}`prop-gaussian-log-sobolev-ot`. More generally, if
$\beta=Z^{-1}e^{-V}\d x$ and $\nabla^2V\succeq\lambda\Id$, then the
Bakry--Emery criterion gives the logarithmic Sobolev inequality with constant
$\lambda$. Thus the hypothesis covers strongly log-concave targets, and it is
the functional-inequality counterpart of the $\lambda$-geodesic convexity of
$\KL(\cdot|\beta)$ discussed in {ref}`sec-geodesic-convexity`.
(prop-lsi-entropy-decay)=
:::{admonition} Proposition: Log-Sobolev Inequality Implies Entropy Decay
:class: important
Let $\beta=e^{-V}\d x/Z$ be a smooth probability measure on $\RR^d$. Assume
that $\beta$ satisfies the logarithmic Sobolev inequality with constant
$\lambda>0$,
```{math}
\KL(\alpha|\beta)
\leq
\frac{1}{2\lambda}
\int \norm{\nabla\log\frac{\d\alpha}{\d\beta}}^2\,\d\alpha .
```
Let $\alpha_t$ solve the Wasserstein gradient flow of
$f(\alpha)=\KL(\alpha|\beta)$ with finite initial entropy, namely
```{math}
\partial_t\rho_t
=
\nabla\cdot(\rho_t\nabla V)+\Delta\rho_t,
\qquad
\alpha_t=\rho_t\d x .
```
Then
```{math}
\KL(\alpha_t|\beta)
\leq
e^{-2\lambda t}\KL(\alpha_0|\beta).
```
Moreover, if $\alpha_0,\beta\in\Pp_2(\RR^d)$, then
```{math}
\Wass_2(\alpha_t,\beta)
\leq
\sqrt{\frac{2}{\lambda}\KL(\alpha_0|\beta)}\,e^{-\lambda t}.
```
Proof
The first variation of f is log(ρ/ρβ) up to an additive
constant.
Along the smooth Wasserstein gradient flow,
and Gronwall’s lemma gives the entropy estimate. Equivalently, the
logarithmic Sobolev inequality is the Wasserstein-PL inequality for f,
because its squared Wasserstein slope is the relative Fisher information.
Applying Theorem Theorem: Wasserstein-PL Convergence and using that the
unique minimizer of f is β gives the displayed W2 distance rate.
Mean-field limits recast the training of wide neural networks as transport of
a distribution of neurons. This section shows how the particle ODE of
gradient descent becomes a Wasserstein flow in parameter space. This
viewpoint, often summarized as treating parameters as interacting particles,
was developed in closely related forms by Mei, Montanari and Nguyen
Mei et al., 2018, Rotskoff and Vanden-Eijnden
Rotskoff & Vanden-Eijnden, 2022, and Chizat and Bach
Chizat & Bach, 2018. These works pass from the
finite-width empirical neuron dynamics to a limiting nonlinear PDE for the
neuron law.
Wasserstein training of two-layer MLPs. The key modeling step is to forget
the ordering of the hidden neurons and to regard the network weights as a
probability measure on parameter space. A finite-width network is then an
empirical measure, and the population loss becomes a functional of this
measure. Gradient descent on the particle positions is precisely the
finite-dimensional discretization of a Wasserstein gradient flow for this
functional, with the Wasserstein metric acting on neuron parameters rather
than on data samples. This is the sense in which training a two-layer
mean-field MLP becomes a transport problem for the law of its neurons.
We use z∈Rd for the input data and y∈Rd′ for the label. A
neuron is a particle
and the empirical risk is the special case
ζ=ζN:=N−1∑k=1Nδ(zk,yk). Since
α↦Gα is linear, f is convex as a function of α
whenever ℓ(⋅,y) is convex. For the empirical neuron law
αX=n−1∑iδxi, the Wasserstein metric induces on
particles the rescaled metric n−1∑i∥x˙i∥2. The
corresponding particle flow is
This is the gradient flow of F(X)=f(αX) for the Wasserstein particle
metric, equivalently Euclidean gradient descent with time scale multiplied by
n. It gives a particle discretization of (8).
Assume that ℓ is differentiable in its first variable. The first
variation is
These kernels are generally not convex in the particle variable, so the
geodesic-convex convergence theory above does not apply directly.
Figure Div illustrates the resulting transport of neurons for a homogeneous ReLU model.
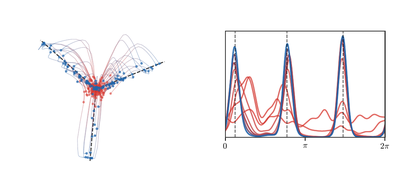
show_book_figure("gradflow-mlp-homogeneous-relu")
Mean-field training of a homogeneous two-layer model as transport in neuron
space. The left panel shows the Wasserstein particle gradient flow in the
reduced homogeneous coordinates (∣u∣v1,∣u∣v2), with black dashed rays
marking the teacher directions. The right panel shows the weighted angular
density along a front-loaded sequence of times, colored from red to blue, so
that the early concentration of neuron directions is visible. The display
follows the rendering of the auxiliary MLP experiment but keeps only the
W2 flow, not the spectral-flow comparison.
The interactive demo gives a lightweight version of the same phenomenon: particles
move in reduced neuron coordinates, while their angles concentrate around the
teacher directions.
Interactive panel. Use the width, homogeneity, and time controls to see the mean-field movement of ReLU neurons and the induced angular density.
Before using the specific homogeneity mechanism of Chizat and Bach, it is
useful to isolate a simpler convex-analytic principle behind many mean-field
arguments. Consider an energy
This is ordinary convexity of the functional on the convex set of measures,
not displacement convexity along W2 geodesics.
Proof
Energy dissipation and the lower bound on f(αt) imply that the squared
slope is integrable in time. Hence it tends to zero along a sequence
tn→∞, and lower semicontinuity gives
Positivity, continuity, and connectedness imply that
δf(α∞) is constant. Thus its integral against
β−α∞ vanishes for every probability measure β.
Classical convexity of f then gives
Strict positivity is essential: without it, stationarity controls the first
variation only on the explored support. For square-loss two-layer mean-field
models, (223) is exactly of this
quadratic-plus-linear form, and positive semidefiniteness of the induced
kernel k is the classical convexity assumption.
The convergence theory then separates two regimes. Chizat and Bach prove
global convergence for the unregularized, noiseless Wasserstein flow of
positively homogeneous models Chizat & Bach, 2018.
Mei, Montanari and Nguyen prove convergence for the noisy, regularized
dynamics Mei et al., 2018: at the PDE level the
noise adds a diffusion, or Laplacian, term, so an initially singular neuron
law is immediately smoothed and acquires a density. Rotskoff and
Vanden-Eijnden emphasize the parameters-as-particles interpretation,
long-time convergence and asymptotic error scaling with the network width
Rotskoff & Vanden-Eijnden, 2022. The following formal
statement isolates the noiseless Chizat--Bach mechanism and ignores the
technical issues due to ReLU non-smoothness, support propagation and
compactness.
Additive constants in first variations do not affect the Wasserstein gradient or first-order inequalities between probability measures; this normalization is useful because it inherits the homogeneity of ψ. By two-homogeneity of ψ,
hα(λx)=λ2hα(x) for λ>0. Taking x=0 and any λ=1 also gives hα(0)=0. We first record that stationarity forces
hα to vanish on
supp(α). Indeed, if
x=rω∈supp(α) with r>0 and ∥ω∥=1, then
The left-hand side is negative, while ∫hαdα=0, so
∫hαdβ<0. Since hα(0)=0, this strict negativity must
occur away from the origin: there exists a nonzero point x=rω with
r>0, ∥ω∥=1, and hα(x)<0. Equivalently
hα(ω)=hα(x)/r2<0. By full directional support, there is
rω>0 such that
rωω∈supp(α). At this support point,
which contradicts the stationarity condition
∇hα=0 on supp(α). Thus no competitor has
smaller risk.
The rigorous Chizat-Bach theorem replaces the full directional support
assumption by propagation and overparameterization hypotheses ensuring that any
negative first-variation direction is represented by the evolving support. The
same radial-derivative contradiction, applied after this support-propagation
step, then rules out non-optimal stationary limits.
The JKO construction is not tied to the quadratic Wasserstein distance. Once a
space of probability measures is equipped with a metric or extended metric
d, one can define a
minimizing movement by the implicit Euler step
This is the metric-gradient-flow framework of Ambrosio, Gigli and Savaré
Ambrosio et al., 2006Ambrosio & Gigli, 2013: under compactness, coercivity and
lower-semicontinuity assumptions adapted to d, the piecewise-constant
interpolants of (237) can converge, as τ→0, to a
curve of maximal slope. A nonmetric discrepancy can still be inserted in the
same update, but the metric theory does not then apply automatically. In the
local mass-preserving metrics considered below, a smooth limiting curve is
again represented by a continuity equation of the type
introduced in (3) and used for Wasserstein flows in
(8),
but the velocity vα is selected by the local steepest-descent rule
associated with the geometry induced by d, not necessarily by the classical
W2 rule. Unbalanced variants replace this continuity equation by a
balance law, while nonlocal variants replace vector fields by jump fluxes.
The metric ingredient needed below is the squared-speed action
A(α,w) introduced in
Generalized Dynamic Wasserstein Distances. Its length distance is
already defined in (38); the present
section only uses the local cost in the infinitesimal variational step defined
below. Some actions are pointwise integrals, such as ordinary W2 with
A(α,w)=∫∥w∥2dα. Others are built from a
homogeneous local density but then squared at the metric level: for Wp,
the local densities are Ap(a,w)=a∥w∥p and
Jp(a,m)=∥m∥p/ap−1, while the action paired with the JKO penalty is
the squared Finsler speed
For an energy f, the formal small-step expansion of
(237), when the distance is generated by the
squared-speed action A and the JKO displacement admits an admissible
finite-action tangent representative, selects the PMO direction
If A(α,⋅) has zero-action directions, the minimization in
the PMO is understood on the quotient tangent space, or after projecting onto
finite-action directions modulo the kernel of A(α,⋅). Along
smooth solutions of (243), whenever the
minimizer is attained and A(α,⋅) is 2-homogeneous, one
obtains
with the inverse understood on the range of Qα, or as a Moore--Penrose
inverse after projecting onto admissible directions when constraints create
null directions. For ordinary W2, Qα=Id on Tα and one
recovers vα=−∇∇f(α). The linear inverse formula is special to
Hilbertian actions. A basic non-Hilbertian example is Wp: for
1<p<+∞, the squared Finsler tangent action associated with the distance is
with the conventions that the right-hand side is 0 when U=0, and that
∥u(x)∥q−2u(x)=0 when u(x)=0. This is nonlinear in u, and it
reduces to −u only for p=2. Endpoint cases such as p=1 are interpreted
through subgradients of the dual norm.
The examples below are organized by the same dictionary. Concave-mobility flows
use the action Aθ,λ from Homogeneous Momentum Actions; spectral flows
use the action Aγ from the spectral dynamic-distance
construction; kernelized Benamou--Brenier flows use
Ak(α,v)=∥v∥Hkd2 with a restricted RKHS tangent
space. Nonlocal logarithmic-mean geometries also have quadratic actions, but
their tangent variables are edge potentials or jump velocities rather than
vector fields in Rd; their flows are treated separately in
the nonlocal Wasserstein-flow section below. WFR, studied separately in
Dynamic Unbalanced OT and WFR Flows, is another quadratic geometry, but its
tangent variable is a pair (v,g) combining displacement and mass modulation.
The notation Qα is reserved for Hilbertian vector-field subcases where a
linear preconditioner represents the tangent geometry.
The generalized distances of Generalized Dynamic Wasserstein Distances
are useful precisely because they change what descent means. The energy
functional can be the same, while the local metric tensor, Finsler norm,
mobility, spectral gauge or RKHS constraint changes the PDE selected by the
minimizing movement. The rest of this section focuses on local or vector-field
mass-preserving geometries. Nonlocal pair-space geometries are separated in
the nonlocal Wasserstein-flow section below, and the transport--reaction case is
separated in Dynamic Unbalanced OT and WFR Flows, because their tangent
variables are structurally different.
The concave-mobility distances of Homogeneous Momentum Actions replace the scalar
linear mobility a by a concave mobility θ(a). For a density field
a=ρt(x), this changes the Onsager operator of the gradient flow while
keeping a continuity equation.
Let λ be Lebesgue measure, write α=ρλ, and let
u=∇(δf/δρ). For the velocity action
Aθ,λ, the PMO introduced in
Definition 1 is the pointwise minimizer of
Thus the flux ρw is −θ(ρ)∇(δf/δρ). For a
smooth density ρt and an energy f, the formal gradient flow associated
with the pointwise momentum action Jθ(a,m)=∣m∣2/θ(a) is
Thus θ(a)=a and U(a)=aloga gives the usual heat or Fokker--Planck
equation, while θ(a)=a(1−a/M) gives a volume-filling drift--diffusion
whose mobility vanishes at saturation. Power internal energies and power
mobilities tune nonlinear diffusion; this viewpoint is useful for nonlinear
diffusions, exclusion models, volume-filling models and finite-volume
discretizations Dolbeault et al., 2009.
The spectral tangent action (62), and the
dynamic distance (63) it generates, normalize
the whole velocity covariance through a monotone spectral gauge. Using this
geometry for gradient descent replaces the pointwise Wasserstein direction by a
globally preconditioned direction. This is close to many large-scale
optimizers: normalized gradient methods solve norm-constrained linear
minimization problems Pethick et al., 2025; related ideas
appear in normalized SGD Murray et al., 2019Cutkosky & Mehta, 2020,
tensor-aware optimizers such as Shampoo Gupta et al., 2018, and
Muon-type spectral normalizations Jordan et al., 2024Liu et al., 2025.
We now describe the mean-field version developed in Peyré, 2026.
The trace gauge gives the classical W2 flow, while the operator gauge
γ(M)=λmax(M) gives the idealized Muon geometry.
Specializing Definition 1 to the spectral
action Aγ, the descent direction associated with a field
g∈L2(α;Rd) is simply
PMOAγ,α(g). The field g should be read as the Wasserstein gradient
g=∇∇f(α)=∇δf(α). Since
v↦Aγ(α,v) is 2-homogeneous, fixed-speed normalized
algorithms keep the same descent ray as this PMO and only change the scalar
normalization; equivalently, the rescaled field minimizes
∫⟨g,w⟩dα over
Aγ(α,w)≤1. In the trace case,
Atr(α,v)=∫∥v∥2dα and
PMOAtr,α(g)=−g. For other gauges, the
velocity is globally preconditioned by the covariance of g under α.
Proof
Using the polar formula
γ(M)=supA∈Bγtr(AM), the PMO objective
(241) with
A=Aγ is the supremum over A∈Bγ
of
For fixed A≻0, this quadratic expression is minimized by
vA=−A−1g. The first-order optimality of Aα⋆ over the polar
set implies that it is active in the polar representation at
v⋆=−(Aα⋆)−1g. Hence equality holds in the lower bound
defined by Aα⋆, and v⋆ minimizes the original objective.
For the trace gauge, the minimizer is Aα⋆=Id. For the operator
gauge γ(M)=λmax(M), one has
Bγ={A⪰0:tr(A)≤1}; if Sα(g)≻0, then
This is the continuum covariance-normalization formula that becomes the Muon
polar factor for empirical measures.
The static/dynamic equality identifies Wγ with the length distance
generated by Aγ. The infinitesimal descent direction is
therefore defined directly by the PMO in
(241). Static/dynamic equality alone does not
give a tangent expansion for every prescribed smooth field, because that field
need not be the minimal-action representative of the induced perturbation.
Proof
The action-based steepest-descent rule gives
vt=PMOAγ,αt(∇∇f(αt)).
Inserting this field in the continuity equation gives the stated PDE. The
dissipation identity follows from the first-variation formula and the
2-homogeneity of the action.
The effect of this spectral normalization is visible already in the homogeneous
two-layer ReLU model discussed earlier in this chapter. Figure
Div reproduces, in the style of the book
figures, the numerical comparison from Peyré, 2026: the same
teacher network, initialization and empirical first variation are evolved
either by the W2 particle flow or by the operator-gauge Muon direction.
Interactive panel. Change the number of neurons and teacher angle in a lightweight normalized-dynamics companion to the full MLP/Muon experiment.
:class: ot4ml-book-figure
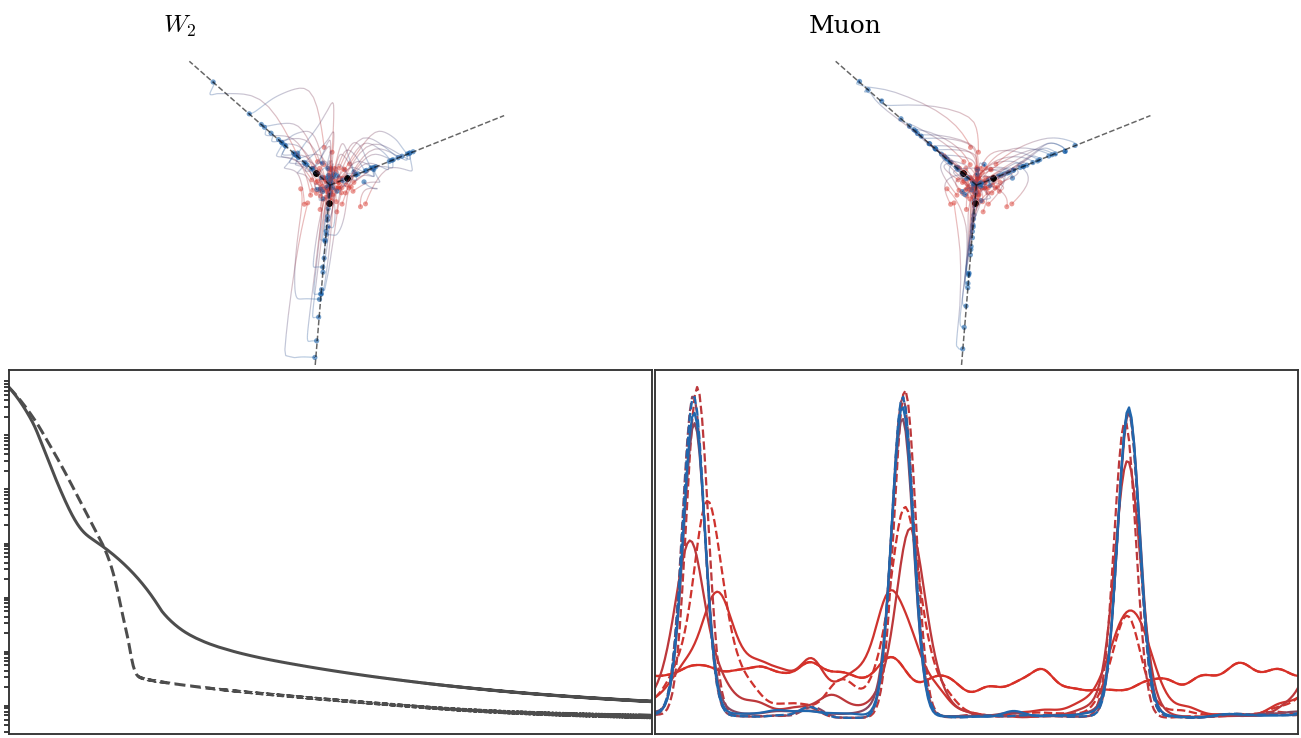
show_book_figure("gradflow-mlp-w2-vs-muon")
Wasserstein versus Muon mean-field training of a homogeneous ReLU model. The
first two panels display trajectories in reduced homogeneous coordinates; black
dashed rays are the teacher directions. The right panel compares empirical
square-loss decay, with a solid curve for the W2 flow and a dashed curve for
the operator-gauge Muon flow. Spectral normalization reaches the low-risk
regime earlier in normalized time.
(sec-nonlocal-wasserstein-flows)=
## Nonlocal Wasserstein Flows
The nonlocal distances of {ref}`sec-nonlocal-wasserstein-distances` replace
the local vector-field tangent model by pairwise exchanges. This separate
section records the corresponding gradient-flow interpretation in the same
order as the distance constructions: first continuum nonlocal Wasserstein flows
and fractional PDEs, then discrete Wasserstein flows on Markov chains. In the
continuum jump-kernel case, entropy descent gives nonlocal diffusion and, for
power-law kernels, fractional PDEs. On a finite state space, the same
logarithmic-mean edge calculus makes a reversible Markov chain exactly the
entropy gradient flow of the discrete Wasserstein distance. Both examples are
mass-preserving, but they are not local Benamou--Brenier flows: their tangent
variables live on pairs or graph edges rather than at individual points.
### Nonlocal Wasserstein Flows and Fractional PDEs
The continuum nonlocal distance $\mathcal W_K$ of
{ref}`sec-nonlocal-wasserstein-distances` replaces local velocities by
antisymmetric fluxes across jumps selected by a reversible kernel $K$. Its
logarithmic-mean mobility is chosen so that entropy dissipation produces the
Markov generator. This turns jump processes, fractional heat equations and some
heavy-tailed stochastic models into gradient flows for nonlocal transport
geometries.
(prop-nonlocal-entropy-gradient-flow)=
:::{admonition} Proposition: Entropy Gradient Flow for Reversible Jump Kernels
:class: important
Under the regularity and irreducibility assumptions of
{cite:t}`Erbar2012JumpEntropy`, $\mathcal W_K$ is an extended distance on the
set of probability measures absolutely continuous with respect to
$\mathfrak m$, finite-action pairs are connected by constant-speed geodesics,
and the Markov semigroup generated by the closure of
```{math}
L\psi(x)
=
\int\bigl(\psi(y)-\psi(x)\bigr)K(x,\d y)
```
is the gradient flow of the relative entropy
```{math}
\operatorname{Ent}_{\mathfrak m}(\alpha)
=
\int\rho\log\rho\,\d\mathfrak m,
\qquad
\alpha=\rho\mathfrak m,
```
for the distance $\mathcal W_K$. In weak form, the entropy flow is
```{math}
:label: eq-nonlocal-entropy-flow
\partial_t\rho_t=L\rho_t .
```
When $K$ is singular, the integral defining $L$ is understood in the
principal-value sense.
which is the weak form of ∂tρ=Lρ. The metric properties and
geodesic existence require compactness and lower-semicontinuity estimates for
the action and are the main content of Erbar (2014).
The construction becomes especially transparent for translation-invariant
kernels. A power-law jump kernel turns the entropy flow into a
fractional heat equation.
The figure below illustrates the qualitative effect of lowering s. Classical
heat diffusion, s=2, smooths local discontinuities by nearby averaging.
Fractional diffusion keeps a sharper memory of localized peaks but immediately
creates algebraic long-range tails, because mass can jump over macroscopic
distances.
Figure Div illustrates the qualitative effect of lowering s.
Classical and fractional heat flows from two localized indicator bumps. Each
panel evolves the same normalized mixture of two intervals by the Fourier
multiplier e−t∣ξ∣s, with time colored from red to blue. The classical
heat flow quickly rounds the discontinuities and spreads by local Gaussian
averaging. As s decreases, the diffusion becomes increasingly nonlocal:
peaks remain more localized near the bumps, while heavier tails appear across
the whole displayed window.
Interactive panel. Vary the fractional exponents and final time to compare
local heat smoothing with heavier-tailed nonlocal diffusion from the same two
localized initial blocks.
More generally, when a target-dependent jump kernel Kβ satisfies
detailed balance with a desired invariant measure
β=ρβm, the same construction can be applied to
rt=dαt/dβ. The gradient flow of KL(α∣β) is then
∂trt=Lβrt. This is the nonlocal analogue of the
Fokker-Planck gradient flow of relative entropy, and it is one of the
motivations behind more recent nonlocal diffusion gradient-flow frameworks
Warren, 2024.
The finite-state distance WK in Discrete Wasserstein Distances on Markov Chains
is designed so that the reversible Markov chain itself becomes an entropy
gradient flow. This is the discrete counterpart of the fact that the heat
equation is the Wasserstein gradient flow of Shannon entropy.
For masses ai=πiρi, or equivalently relative densities
ρi=ai/πi with respect to the invariant law π, the entropy relative
to π is
where (Kρ)i=∑jKij(ρj−ρi). Under smoothness and strict
positivity, ρk+1=ρk+O(τ), so the last expression also equals
Kρk+O(τ). Thus the discrete Wasserstein
geometry is engineered so that the entropy gradient flow is the Markov
semigroup; the proposition below makes this identity explicit.
Proof
The first variation of the entropy, with respect to the weighted pairing
∑iπiξiφi, is logρi+1. Constants do not contribute to
Kρ, hence the metric gradient-flow equation is
ρ˙=−Kρlogρ. Using
θ(a,b)(loga−logb)=a−b, one obtains
which is the density form of the Kolmogorov forward equation. Multiplying by
πi and using detailed balance gives the equation for the probability
masses.
The generalized dynamic Wasserstein flows of
Generalized Dynamic Wasserstein Flows are primarily
mass-preserving: their tangent vectors are generated by continuity equations
and are therefore velocity fields advecting the measure. Unbalanced transport
changes the state space from probabilities to positive finite measures, where
descent may both move and create or remove mass. The tangent variable is then
a pair (v,g): the vector field v displaces mass, while the scalar field
g modulates its local intensity. This transport--reaction geometry is the
dynamic counterpart of the unbalanced distances of Dynamic Unbalanced Wasserstein Distances,
especially the balance-equation formula (109), and it
is best treated separately from the purely advective geometries above.
Formally, a smooth curve αt=ρtdx has tangent vectors of the
form
with squared norm
∫(∥vt∥2+κ2gt2)ρtdx. The vector field vt accounts
for displacement, while gt is a Fisher--Rao growth rate. This is the
infinitesimal version of the balance-equation action in the dynamic OT chapter.
Proof
For an infinitesimal tangent pair (v,g), the density variation is
ζ=−div(ρv)+gρ. The first variation of f is
the Riesz representative is (∇ϕ,ϕ/κ2). Steepest descent
uses (v,g)=(−∇ϕ,−ϕ/κ2), which gives the PDE. Substituting
this pair in the first-variation formula gives the dissipation identity.
The reaction term makes additive constants in the first variation meaningful:
adding a constant to ϕ changes the global growth rate. This is not a
defect but the infinitesimal signature of optimizing over positive finite
measures, rather than on the probability simplex. Rigorous constructions of
Kantorovich--Fisher--Rao and WFR gradient flows are developed in
Gallouët & Monsaingeon, 2017Chizat et al., 2018Chizat et al., 2018. Chizat’s
measure-optimization framework relates weight-changing gradient methods to
mirror- and Bregman-type descents on positive measures
Chizat, 2022Chizat, 2022. In
machine learning, birth--death dynamics use the same reaction intuition to let
a particle population reweight, remove and create neurons during training
Rotskoff et al., 2019.
Figure Div contrasts this reaction-assisted relaxation with its mass-preserving Wasserstein counterpart.
show_book_figure("gradflow-wfr-unbalanced-flow")
Balanced and unbalanced gradient flows of KL(ρ∣β) for
one-dimensional Gaussian mixtures. In each panel the colored density stacks
correspond to five increasing times, from red to blue, and the faint gray
curve repeated on each row is the target mixture β. The balanced
Wasserstein flow is the conservative Fokker--Planck equation, so mass must
move through the low-density region between modes. The WFRκ flow adds
the birth--death reaction term in (282); it attenuates
overrepresented regions and creates missing mass near target modes, reaching
the target shape much faster.
Interactive panel. Change the transport and growth weights to compare
conservative motion with creation--destruction dynamics.
Conditional Wasserstein Training of Infinite ResNets¶
Residual networks learn small residual updates around the identity
He et al., 2016. This makes depth behave like time: very deep
residual architectures can be interpreted as discretizations of differential
equations, a viewpoint developed in stable architectures, neural ODEs and
mean-field optimal-control models of deep learning
Haber & Ruthotto, 2017Lu et al., 2018Chen et al., 2018E et al., 2019.
The conditional-OT formulation of Barboni, Peyré and Vialard
Barboni et al., 2024 adds the width mean-field
limit to this continuous-depth picture. This should be read alongside the broader
conditional-transport literature reviewed in Section
Conditional Wasserstein Distances, especially fibered gradient flows
Peszek & Poyato, 2023, function-space conditional OT
Hosseini et al., 2025, and conditional OT
flow-matching constructions
Chemseddine et al., 2025Kerrigan et al., 2024. From the viewpoint of
Generalized Dynamic Wasserstein Flows, it is a concrete instance of a
generalized dynamic Wasserstein flow: the conditional Wasserstein distance has a
geodesic dynamic structure obtained by integrating the usual Benamou-Brenier
action over the conditioning variable. The point of the construction is to keep
track of two independent symmetries: neurons can be relabelled inside each
layer, but mass should not move from one depth to another. Conditional
Wasserstein geometry implements exactly this rule. It transports neurons fiber
by fiber in parameter space, while the depth variable remains fixed.
We follow the three limiting levels of the model. A finite ResNet is
first a labelled particle system arranged by layers. Sending the width to
infinity turns each layer into a probability law of neurons. Sending the depth
step to zero then turns the sequence of layer laws into a conditional measure
indexed by depth, on which training becomes a Wasserstein gradient flow.
The starting point is the ordinary architecture: depth is discrete, width is
finite, and each layer carries a labelled collection of neurons. Fix a parameter
space Θ⊂Rq, a residual feature
ψ:Θ×Rd→Rd, a data law ζ on input-label
pairs (z,y), and a loss ℓ. With L layers, step size τ=1/L,
widths nr, and parameters θr,i∈Θ, a finite ResNet is
the composition of the residual updates
The first mean-field limit removes neuron labels inside each fixed layer. The
residual depth grid stays discrete, but the widths tend to infinity. Each
empirical law αr is replaced by an arbitrary probability measure in
P2(Θ), and each residual block becomes a mean-field residual block
The second limit turns the layer index into a conditioning variable. The model
is no longer described by one neuron law, nor even by a finite list of them, but
by a family of neuron laws indexed by depth. The state is therefore a
conditional probability law
or, equivalently, a probability measure on [0,1]×Θ whose first
marginal is Lebesgue measure. The general conditional Wasserstein distance is
defined in Section Conditional Wasserstein Distances. Here the
condition is continuous depth, s∈[0,1], the condition law is
λ(ds)=ds, and the fiber space is the neuron parameter space
Θ. For two conditional neuron laws
α(ds,dθ)=αs(dθ)ds and
β(ds,dθ)=βs(dθ)ds, the relevant distance is the
depthwise quadratic Wasserstein metric
Once depth is continuous, the forward pass is a controlled ODE and the control
is the conditional neuron law. A mean-field infinite-depth and infinite-width
ResNet is described by a measurable family
s↦αs∈P2(Θ). Each slice is the neuron law of one
infinitesimal residual block, and the feature ψ(θ,z) now acts as a
vector field on the state variable. The forward pass is
Training is now steepest descent for an objective on conditional laws. More
generally, let (S,λ) be a probability space and let f be a differentiable functional on measures
α(ds,dθ)=αs(dθ)λ(ds) with fixed first
marginal λ. For signed perturbations
ξ(ds,dθ)=ξs(dθ)λ(ds) satisfying
∫Θdξs=0 for λ-a.e. s, we use the fiberwise
first-variation convention
for λ-a.e. condition s, whenever the first variation is differentiable
in the parameter variable. In the ResNet case one takes f=fRes and S=[0,1].
The equation is fiberwise in its transport geometry, but not decoupled as a
training dynamics: changing αs affects the terminal loss through the
forward ODE and the corresponding adjoint equation. Thus each depth performs a
Wasserstein steepest descent in its own neuron space, while all depths interact
through the state trajectory.
The finite network is recovered by discretizing both the condition variable and
the fiber measures. With the discrete depth marginal λL, finite-depth
finite-width ResNets are particle approximations of the conditional flow above.
If two networks have the same depth grid and the same widths, and if their
empirical layer laws are
which corresponds to a particular feasible coupling and therefore upper bounds
the squared conditional Wasserstein distance. Optimizing over permutations inside
each equal-weight layer gives the Wasserstein matching term above. In this sense,
the shallow mean-field flow is the one-fiber case, whereas infinitely deep
ResNets require a continuum of Wasserstein flows indexed by depth and coupled
through the network state.
The minimizing-movement viewpoint is intrinsically first order: a JKO step
produces the next measure by trading off proximity to the previous measure and
decrease of the energy. Momentum adds a memory of velocity. The state is
therefore no longer only a measure, but a measure together with a tangent, or
equivalently phase-space, variable. This makes a direct implicit JKO
construction less natural than for first-order flows. We instead use an
explicit construction, in the same spirit as optimization and machine-learning
practice: momentum reduces zig-zagging across stiff directions, helps iterates
keep a coherent direction through shallow valleys, and can accelerate
convergence when the geometry is favorable Qian, 1999Sutskever et al., 2013.
Let F:RN→R be a smooth finite-dimensional objective. Polyak’s
heavy-ball method Polyak, 1964 augments gradient descent with
a velocity variable. With step size h>0 and damping γ>0, one convenient
velocity form is
If Sk approximates X˙(kh), this is a semi-implicit, or
symplectic-Euler, discretization: the velocity update is explicit, while the
position uses the newly updated velocity. Its limiting system is
This ODE interpretation is due to Su, Boyd and Candes
Su et al., 2016; see also the variational perspective of
Wibisono, Wilson and Jordan Wibisono et al., 2016,
the inertial dynamics with Hessian damping of Attouch, Peypouquet and Redont
Attouch et al., 2016, and high-resolution ODE
limits Shi et al., 2018.
This is the same empirical lift as in (23), and is the
particle viewpoint underlying mean-field analyses of wide neural networks and
Wasserstein gradient methods
Chizat & Bach, 2018Mei et al., 2018Rotskoff & Vanden-Eijnden, 2022.
The configuration space is used with the empirical metric
which is the metric induced by W2 on equally weighted empirical
measures with fixed labels. Hence the Wasserstein gradient of f is lifted to
the particle gradient through
Equivalently,
x¨i(t)+γx˙i(t)=−∇∇f(αt)(xi(t)). This is an explicit
inertial particle method for the measure energy f: the Wasserstein
steepest-descent field acts as an acceleration rather than as an instantaneous
velocity.
Proof
By (305) and the definition
vα=−∇∇f(α), one has
∇xiF(X)=−vαX(xi)/n. Hence
Because momentum is part of the state, the mean-field object is not merely a
measure on positions. It is a law on phase space (x,s), whose spatial
marginal is the current distribution of particles. Here s is a Lagrangian
particle velocity; it should not be confused with the Eulerian momentum measure
m=ρv used in the Benamou--Brenier convex formulation
(28). This deterministic kinetic viewpoint is the
analogue of the phase-space formulation used for interacting particle systems;
in learning, heavy-ball mean-field limits have recently been used to analyze
wide networks trained with momentum Wu et al., 2022.
Proof
Test the empirical measure against
φ∈Cc∞(Rxd×Rsd), differentiate
n−1∑iφ(xi(t),si(t)), and substitute the particle equations.
Rewriting the result as an integral against ηtn and integrating by
parts gives the Liouville equation. Passing formally to the mean-field limit
gives the smooth equation.
For numerical stability, the numerical illustration below uses the smoothed
distance ∥x−y∥2+δ2 with a small δ in the
energy-distance kernel k(x,y)=−∥x−y∥. It compares the first-order flow
with the undamped Newton lift
x¨=vαt(x)=−∇∇f(αt)(x), initialized with zero velocity.
The initial measure is a single Gaussian located to the left of a
two-Gaussian target mixture. Both the transported measure and the target are
discretized by large empirical clouds, and the smooth density views are KDE
renderings of these particles. The trajectory panels display only a
representative subset of initial particles selected by farthest-point sampling.
For numerical stability, Figure Div uses the smoothed distance ∥x−y∥2+δ2 with a small δ.
First-order and Newton Wasserstein particle flows for the squared MMD with
the energy-distance kernel k(x,y)=−∥x−y∥. The first row follows the
overdamped Wasserstein gradient flow. The second row follows the
infinite-momentum Newton dynamics x¨=−∇∇f(αt)(x), so the same
Wasserstein force is read as an acceleration rather than a velocity. Both rows
use the same large empirical source cloud and the same empirical two-Gaussian
target cloud. Dashed gray contours show a KDE of the target particles, colored
panels show KDEs of the evolving transported particles, and the left panels
show farthest-point-subsampled trajectories.
Interactive panel. Compare the same energy-distance force interpreted as
an overdamped Wasserstein velocity or as a Newton acceleration. The browser
simulation keeps the source cloud, target mixture, representative trajectories
and −∣x−y∣ interaction visible with a smaller empirical discretization than
the publication figure.
For the numerical illustration, we add the quadratic confinement
V(x)=∥x∥2/2. In one dimension the overdamped equation is the
Ornstein--Uhlenbeck Fokker--Planck equation
∂tρt=∂xxρt+∂x(xρt), whose stationary
law is the centered Gaussian N(0,1). The Newton lift is discretized
directly in phase space:
Both equations are solved by finite differences on fixed grids, with a mild
grid smoothing only to evaluate the logarithmic derivative in the Newton row.
The first row of Figure Div
shows only the spatial density of the Wasserstein gradient flow. The second
and third rows show, for the Newton equation, respectively the spatial
marginal and the full phase-space density; the latter uses white for zero mass
and black for high mass.
Finite-difference entropy and inertial entropy flows in one dimension. The
initial spatial density is a three-Gaussian mixture with different widths and
overlapping components. The top row solves the confined entropy Wasserstein
gradient flow, i.e. the OU/Fokker--Planck equation, whose stationary density
is the dashed centered Gaussian. The two lower rows solve the undamped Newton
lift on a grid in (x,s), initialized with a narrow centered speed
distribution: its spatial marginal is shown in color and the full phase-space
density below in grayscale.
Interactive panel. Vary damping and time in a one-dimensional qualitative
companion to the finite-difference entropy/Newton comparison.
Otto, F. (2001). The geometry of dissipative evolution equations: the porous medium equation. Communications in Partial Differential Equations, 26(1–2), 101–174.
Ambrosio, L., Gigli, N., & Savaré, G. (2006). Gradient Flows in Metric Spaces and in the Space of Probability Measures. Springer.
Benamou, J.-D., Carlier, G., Mérigot, Q., & Oudet, E. (2016). Discretization of functionals involving the Monge–Ampère operator. Numerische Mathematik, 134(3), 611–636.
Peyré, G. (2015). Entropic approximation of Wasserstein gradient flows. SIAM Journal on Imaging Sciences, 8(4), 2323–2351.
Gallouët, T. O., & Monsaingeon, L. (2017). A JKO splitting scheme for Kantorovich–Fisher–Rao gradient flows. SIAM Journal on Mathematical Analysis, 49(2), 1100–1130.
Maury, B., Roudneff-Chupin, A., & Santambrogio, F. (2010). A macroscopic crowd motion model of gradient flow type. Mathematical Models and Methods in Applied Sciences, 20(10), 1787–1821.
Santambrogio, F. (2018). Crowd motion and population dynamics under density constraints. GMT Preprint 3728.
Carlier, G., Chizat, L., & Laborde, M. (2024). Displacement smoothness of entropic optimal transport. ESAIM: Control, Optimisation and Calculus of Variations, 30, 25. 10.1051/cocv/2024013
Carlier, G., Jimenez, C., & Santambrogio, F. (2008). Optimal transportation with traffic congestion and Wardrop equilibria. SIAM Journal on Control and Optimization, 47(3), 1330–1350.
Carrillo, J. A., Chertock, A., & Huang, Y. (2015). A finite-volume method for nonlinear nonlocal equations with a gradient flow structure. Communications in Computational Physics, 17(01), 233–258.
Gianazza, U., Savaré, G., & Toscani, G. (2009). The Wasserstein gradient flow of the Fisher information and the quantum drift-diffusion equation. Archive for Rational Mechanics and Analysis, 194(1), 133–220.
Maas, J. (2011). Gradient flows of the entropy for finite Markov chains. Journal of Functional Analysis, 261(8), 2250–2292.
Erbar, M. (2010). The heat equation on manifolds as a gradient flow in the Wasserstein space. Annales de l’Institut Henri Poincaré, Probabilités et Statistiques, 46(1), 1–23.
McCann, R. J. (1997). A convexity principle for interacting gases. Advances in Mathematics, 128(1), 153–179.
Tong, A., Huang, J., Wolf, G., van Dijk, D., & Krishnaswamy, S. (2020). TrajectoryNet: A Dynamic Optimal Transport Network for Modeling Cellular Dynamics. Proceedings of the 37th International Conference on Machine Learning, 119, 9526–9536. https://proceedings.mlr.press/v119/tong20a.html