This chapter focuses on algorithmic convergence for entropic optimal
transport: the marginals and the temperature are fixed, and one asks how
Sinkhorn iterates, soft transforms and related monotone scaling procedures
approach their regularized fixed point. Statistical convergence is a separate
question, because the empirical marginals then change with the sample size;
this is the topic of Paragraph.
The chapter revisits Sinkhorn convergence through several complementary
lenses. Bregman projections explain the alternating-projection geometry,
Fortet’s order argument gives qualitative fixed-point convergence, and an
order-theoretic M-function viewpoint explains why Sinkhorn-like scaling can
still converge even when the equations are no longer the gradient of a convex
potential. Robust Bregman estimates then give a non-asymptotic dual-gap bound,
while Hilbert’s metric gives a clean linear contraction when the kernel is
uniformly positive. The last sections discuss Gaussian closed forms and
continuous ε-Sinkhorn flows as model cases where the fixed-point
structure becomes explicit.
from pathlib import Path
import sys
from IPython.display import Image as DisplayImage
from IPython.display import display
here = Path.cwd()
myst_dir = None
for candidate in [here, here.parent, here / "myst", here.parent / "myst", here.parent.parent / "myst"]:
if (candidate / "ot4ml_web.py").exists():
myst_dir = candidate.resolve()
sys.path.insert(0, str(myst_dir))
break
if myst_dir is None:
raise RuntimeError("Could not locate myst/ot4ml_web.py")
repo_root = myst_dir.parent
thumbnails = repo_root / "notebooks-figures" / "thumbnails"
def show_book_figure(name, width=760):
display(DisplayImage(filename=str(thumbnails / f"{name}.png"), width=width))
Sinkhorn can be read as alternating Bregman projections. The main geometric
message is simple: each row or column rescaling is the KL projection onto one
affine marginal constraint. The convergence mechanism then follows from the
Pythagorean identity for Bregman divergences.
For simplicity, this section is written for discrete measures. The same ideas
carry over to general measures, and the robust-rate section below expresses
the constants through cost and potential oscillations rather than through the
number of grid points.
The projection viewpoint explains Sinkhorn as repeated enforcement of one
marginal constraint at a time. It is not specific to entropy, although KL is
the case where the projections reduce to elementary row and column scalings.
For the quadratic generator
Φ(P)=21∥P∥F2 on
Rn×m, one recovers half the squared Euclidean distance,
BΦ(P∣Q)=21∥P−Q∥F2. For the negative entropy
Φ(P)=∑i,jPi,jlogPi,j on the nonnegative orthant,
extended by +∞ outside it, one obtains
BΦ(P∣Q)=KL(P∣Q). For P≥0 and Q>0,
this identity is understood through the lower-semicontinuous extension, with
0log0=0.
Bregman divergences are useful because their geometry can encode constraints.
A Legendre-type generator blows up, or has an infinite derivative, at the
boundary of its domain. For negative entropy, positivity is therefore built
into the divergence, so one projects onto affine marginal constraints without
separately handling non-negativity.
Adding a linear cost to a Bregman penalty merely shifts the reference point in
dual coordinates. The usual Gibbs--KL reformulation is exactly the entropy
specialization.
On the transport polytope, scaling Ka,bϵ is equivalent to scaling
the Gibbs kernel K=e−C/ϵ because the factors ai and bj can
be absorbed into the Sinkhorn scalings. The unique entropic optimizer is the
KL projection of this tilted Gibbs reference onto the coupling constraints:
Given two closed convex constraint sets C1 and C2, the
cyclic method projects first onto C1, then onto C2, and
repeats. Full iterates satisfy the second constraint and half-iterates satisfy
the first; both are attained together only in the limit.
The following algorithm records the general cyclic iteration. The two
nonnegative constraint defects vanish on their respective sets and provide a
practical stopping test.
The convergence mechanism is the classical one of Bregman projections
Bregman, 1967. General convex constraints determine a
feasible limit, while affine constraints give the stronger closest-point
characterization.
Proof
For three interior points, the Bregman three-point formula is
Let Z(2ℓ)=P(ℓ) and
Z(2ℓ+1)=P(ℓ+1/2). For every
Q∈C1∩C2, applying this inequality at each half-step
shows that BΦ(Q∣Z(r)) decreases and that
∑rBΦ(Z(r+1)∣Z(r))<+∞. Compactness and strict
convexity imply ∥Z(r+1)−Z(r)∥→0. Hence every cluster point belongs
to both closed sets. If Pˉ is one such point, then
BΦ(Pˉ∣Z(r)) decreases to zero along a subsequence and
therefore along the whole sequence. Thus Z(r)→Pˉ.
For affine sets the first-order inequality is an equality. The dual
displacements at successive half-steps lie in the two fixed normal spaces;
telescoping gives
We now apply the general Bregman-projection framework to entropic OT. The two
affine constraints impose the source and target marginals, while negative
entropy turns their cyclic projections into explicit row and column
rescalings. Denote these constraint sets by
For negative entropy, however, the Legendre generator has effective domain
Ω=R+n×m and is +∞ outside Ω. Thus
ProjCiKL already minimizes
over Ci∩Ω: the generator enforces positivity, which need
not be repeated in the projector notation. The cyclic iteration therefore
specializes to
The Lagrange multiplier equation gives
log(p/q)+λ1=0, hence p=uq with u=e−λ>0. The
constraint fixes u=s/∑iqi, which is exactly the scaling formula.
For positive histograms and a strictly positive Gibbs kernel, iterative
proportional fitting keeps the half-steps positive and converges
Ruschendorf, 1995Rüschendorf & Thomsen, 1998. Since the two marginal sets are
affine, Proposition: Convergence of Cyclic Bregman Projections, applied with
P(0)=Ka,bϵ, identifies the limit as the entropic optimizer.
the two projection steps are the usual Sinkhorn updates on the scaling
vectors. In practice one stores the vectors and multiplies by the Gibbs
kernel, often exploiting separable, sparse, low-rank or geometric structure.
The Bregman proof is geometric, but its direct finite-dimensional linear-rate
constants can degrade with dimension and with small ϵ. The robust
dual analysis below gives a dimension-free qualitative message: before any
local linear regime becomes visible, one can still guarantee an O(1/ℓ) dual
gap whose constants depend on the cost range and potential oscillation.
The simplicity of the KL construction relies on negative entropy encoding
nonnegativity through its effective domain. Suppose instead that Φ is
Legendre on the full space Rn×m. Positivity must then be
included explicitly in the marginal constraints:
Thus
U(a,b)=Ca,+1∩Cb,+2. These sets are
convex but no longer affine, and their BΦ-projectors generally have no
closed-form scaling formula. The affine clause of
Proposition: Convergence of Cyclic Bregman Projections no longer applies: ordinary cyclic projections
may converge to a feasible point without computing
ProjU(a,b)BΦ(P(0)).
For the Euclidean generator
Φ(P)=21∥P∥F2, projection onto
Ca,+1 is a rowwise simplex projection:
The column formula is analogous. These thresholds are not multiplicative
scalings, but sorting or selection computes them efficiently
Blondel et al., 2018.
To recover the closest-point projection onto the intersection, Dykstra’s
algorithm alternates the same Bregman projectors while carrying correction
variables in dual coordinates. Under the standard finite-dimensional
assumptions, it converges to
ProjCa,+1∩Cb,+2BΦ(P(0))Dykstra, 1985Censor & Reich, 1998Bauschke & Lewis, 2000. Benamou, Carlier, Cuturi,
Nenna, and Peyré developed this construction systematically for regularized
transport Benamou et al., 2015. Through Fenchel duality,
Bregman--Dykstra is block-coordinate ascent on the marginal dual potentials;
the correction variables store the dual memory absent from plain cyclic
projection Bregman et al., 1999.
For the quadratic generator and the product reference ξ=a⊗b,
for positive ai,bj. The difference is the fixed inverse product-marginal
weighting in the second quadratic norm. Both models yield positive-part
thresholding and potentially sparse plans. The section on
Other Convex Regularizers
develops their dual laws and alternating dual-maximization algorithms.
This section isolates the order structure shared by generalized Sinkhorn
updates. It first introduces the abstract language of topical maps, then
applies it to the generalized soft transforms of
Other Convex Regularizers, and finally derives a monotone
fixed-point argument valid beyond KL regularization.
For the ϕ-divergence regularized transport problem, the one-sided block
updates are expressed using the Legendre transform ϕ∗ defined in
(47). They are the generalized soft c-transforms of
(121), and their alternating dual-maximization
scheme is (124). After
choosing a consistent extremal minimizer whenever a scalar update is not
unique, one full cycle acting on the first potential is
For the KL generator, this is the usual double Sinkhorn map.
Proof
Since ϕ is extended by +∞ on (−∞,0), its Legendre
transform ϕ∗ from (47) is convex and nondecreasing. For
fixed x, let Hgx(u) denote the scalar objective in the first line of
(121). If g≤g′, then
u↦Hg′x(u)−Hgx(u) is nondecreasing because
s↦ϕ∗(s+δ)−ϕ∗(s) is nondecreasing for every
δ≥0.
Let I=argminHgx and
I′=argminHg′x. Comparing the two optimality
inequalities shows that minI′≤minI; the same argument gives
maxI′≤maxI. Finally,
Hg+sx(u)=Hgx(u+s)+s, so either extremal selection is additively
anti-homogeneous. The second one-sided transform is symmetric. Their
composition is topical, and
Proposition: Topical Maps are Variation-Nonexpansive gives the final estimate.
Topicality gives nonexpansiveness, not a strict contraction. For KL,
positivity of the Gibbs kernel supplies the stronger Hilbert-metric
contraction proved in Sinkhorn Convergence: Linear Hilbert Metric Rate; no comparable strict factor
follows from the order properties alone for a general ϕ.
The following order argument traces back to Fortet’s proof of the Schrodinger
system Fortet, 1940Essid & Pavon, 2019Léonard, 2019. It
is not based on an optimization principle: a subsolution generates an
increasing orbit, while a fixed point provides an upper barrier.
Proof
Because Aϕ is additively homogeneous, shifting a subsolution
preserves its defining inequality. Shift it below a fixed point. Topicality
then gives
The one-sided transforms inherit the modulus of continuity of the cost. If
δ(x,x′)=supy∣c(x,y)−c(x′,y)∣, then order reversal and additive
anti-homogeneity give
The orbit is therefore uniformly bounded and equicontinuous. Arzela--Ascoli
upgrades pointwise convergence to uniform convergence. The same order and
shift properties also make each one-sided transform nonexpansive in the
uniform norm, so Aϕ is continuous and the limit is a fixed
point. The supersolution argument reverses all inequalities.
The subsolution and supersolution conditions are invariant under additive
shifts, but a shift cannot turn an arbitrary initialization into either one.
The proposition therefore isolates the genuinely order-theoretic convergence
mechanism; unrestricted initialization requires an additional compactness,
ascent, or contraction argument.
The preceding projection and monotonicity arguments establish convergence but
do not provide a quantitative rate. The Hilbert-metric analysis in
Sinkhorn Convergence: Linear Hilbert Metric Rate will give geometric, or linear, convergence, the
canonical asymptotic behavior of a strictly contractive fixed-point iteration;
however, the gap between its global contraction factor and one typically
becomes exponentially small in the cost oscillation divided by ϵ.
We therefore first establish a slower O(1/ℓ) dual-gap rate whose constant
grows only as 1/ϵPeyré, 2026Altschuler et al., 2017Dvurechensky et al., 2018. This
robust dependence is crucial when Sinkhorn approximates unregularized discrete
OT: Corollary Corollary: Approximating Unregularized OT by Regularized Dual Costs chooses
ϵ=δ/(2log(nm)), so the temperature decreases with the requested
accuracy and with the number of support points.
Proof
Subtracting minC does not change the dual gaps or the Sinkhorn orbit up to
gauge, so assume 0≤Cij≤R. For a vector h, define the quotient
norm
Every soft transform, including an optimal one, has oscillation at most R.
Thus both dual blocks have quotient radius at most U=R/2. Vectorizing the
coupling gives the constraint operator
A(P)=(P1m,P⊤1n), for which
∥A∥1→1=2. Every exact half-step has total mass one, so the primal
mass bound is X=1. The robust cyclic-projection theorem
Peyré, 2026 therefore gives
Pinsker’s inequality from Theorem Theorem: Pinsker Inequality controls the marginal
residual by the KL ascent, while the quotient-radius bound controls the dual
gap by the same residual. Their combination yields
Moreover Lϵ,ℓ=Eϵ−Δ(ℓ). Apply the preceding
proposition and allocate δ/2 to each of the regularization and
optimization errors.
The same identities give computable diagnostics. If r=P1m, the KL
projection onto the row constraint satisfies
KL(Proj(P)∣P)=KL(a∣r);
the column identity is analogous. Each observed dual ascent is therefore a
marginal KL defect, and Theorem Theorem: Pinsker Inequality turns it into an
ℓ1 residual. The residual is not itself the remaining dual gap: a
certificate also needs the quotient-radius estimate used above.
Hilbert’s projective metric measures positive scaling vectors modulo global
multiplication. A positive kernel contracts this geometry, yielding a global
linear rate for Sinkhorn scaling rays.
Multiplying either vector by a positive scalar leaves H unchanged.
It is therefore a metric only on projective classes.
Proof
The logarithm identifies the projective cone with
Rn/span(1n). The variation seminorm vanishes
exactly on constant vectors, hence induces a norm on this quotient. Completeness
follows from finite dimensionality.
Proof
The Birkhoff--Hopf theorem contracts Hilbert’s metric by
tanh(Δ(A)/4), where
Δ(A)=supu,v>0H(Au,Av) is the projective diameter. For a
positive matrix, output cross-ratios give
Δ(K)=logη(K). Hence
tanh(Δ(K)/4)=(η(K)−1)/(η(K)+1)Birkhoff, 1957.
The contraction is already visible on the three-state probability simplex.
With the column-vector convention, every positive column-stochastic matrix
K maps Δ3 into its interior, and
The control K1 acts as ρI on the zero-sum tangent plane. Since the
restriction of A has eigenvalues ±i3, the non-Perron
eigenvalues of Kρ,δ are
ρ±i3δ. Thus K2 contracts isotropically while
turning gradually. The third panel instead uses the positive doubly
stochastic, non-normal kernel
Its non-Perron eigenvalues are approximately .9222 and .7978. Their
unequal moduli make the images progressively slender, while non-normality adds
shear and a gradual transient turn. Writing
gives r1=ρ, r2=ρ2+3δ2≃.9003, and
r3≃.9222. This Euclidean asymptotic rate
is distinct from the global Birkhoff factor λ(Ki) in Hilbert’s metric.
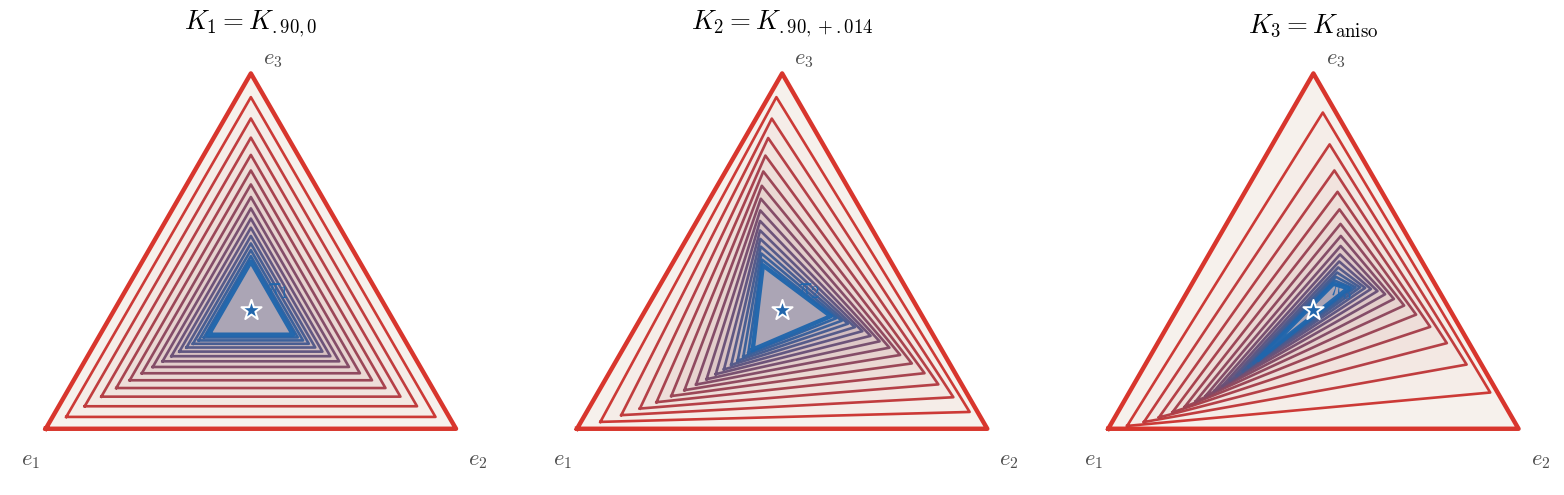
Figure Div contrasts isotropic contraction, rotation, and anisotropic non-normal contraction.
# Isotropic, rotating, and anisotropic positive kernels.
show_book_figure("sinkhorn-birkhoff-simplex-contraction")
Positive Markov kernels contract the three-state simplex and can
simultaneously rotate its image. Color progresses from red at ℓ=0 to
blue at ℓ=15, and the star is the common stationary vector
13/3. The isotropic K1 keeps parallel edges, K2 rotates an
essentially homothetic triangle, and the non-normal K3 both turns and
strongly elongates its image because its tangent modes contract at unequal
rates. The outer boundary is only a geometric reference, since the Hilbert
metric becomes finite after the first positive image.
The theorem applies to positive linear maps between proper cones. Related
nonlinear projective results require order preservation and homogeneity; a
generic affine map is not covered.
Proof
Entrywise multiplication by a fixed positive vector and entrywise inversion
are isometries of Hilbert’s metric. The row map
R(v)=a/(Kv) and column map C(u)=b/(K⊤u) are therefore both
λ-Lipschitz. The full-cycle maps C∘R and R∘C contract by
λ2, which gives the first bounds.
gives the posterior estimates. For the plan bound, write
ξi=log(ui(ℓ)/ui⋆) and
ζj=log(vj(ℓ)/vj⋆). Then
log(Pij(ℓ)/Pij⋆)=ξi+ζj. Both plans have mass one,
so zero lies between the minimum and maximum of ξ⊕ζ; its sup norm
is bounded by its oscillation, which is
∥ξ∥V+∥ζ∥V.
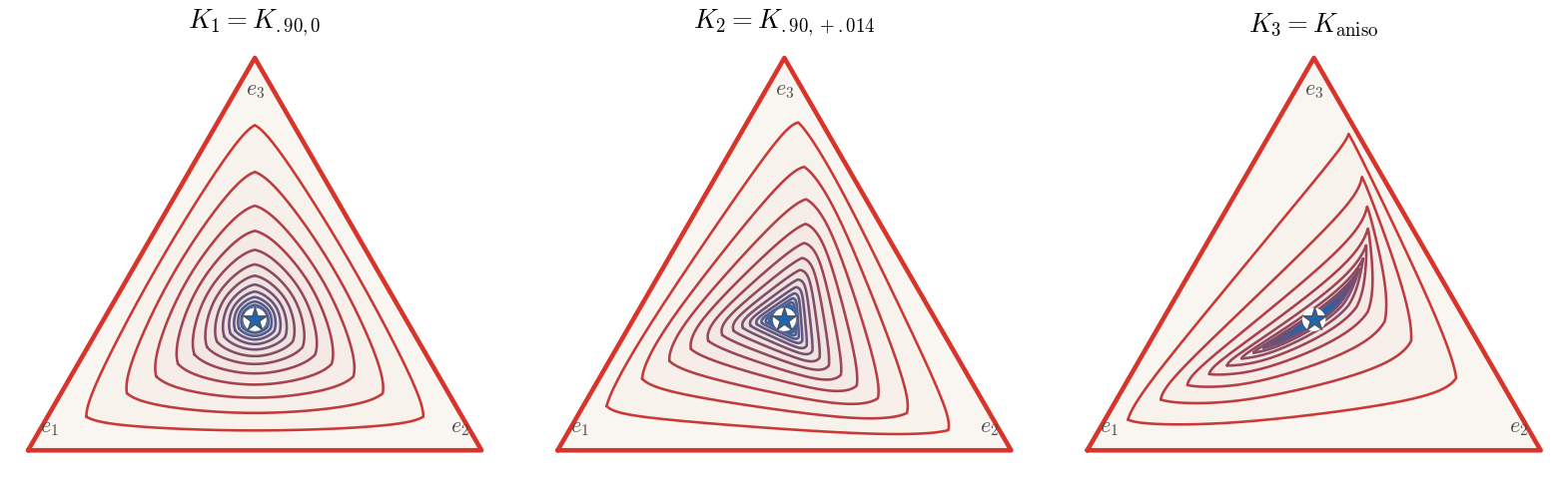
The projective contraction can be visualized simultaneously for every possible
left-scaling ray. Using the row and column maps from the proof, define the
full-cycle map
The figure reuses the three kernels Ki from
Div, with the same uniform
Sinkhorn marginals a=b=13/3 in every panel. This isolates the passage from the linear action
Kiℓ to the nonlinear balancing map Fu,iℓ. The
symmetric control remains aligned, K2 turns the curved images, and the
unequal tangent rates of K3 produce a pronounced anisotropic collapse. The normalized
Sinkhorn fixed ray and stationary Markov vector both equal 13/3 in
this doubly stochastic example, although they need not coincide in general.
Figure Div reuses the three kernels Ki from Figure Div, with the same uniform Sinkhorn marginals a=b=13/3 in every panel.
# The same three kernels under complete Sinkhorn cycles.
show_book_figure("sinkhorn-projective-scaling-simplex")
Complete Sinkhorn cycles curve, turn and contract the simplex of normalized
left scalings. Panel i reuses Ki from the preceding linear figure and
the common marginals a=b=13/3. Color is the densely sampled boundary
of Fu,iℓ(Δ3), progressing from the red triangle
at ℓ=0 to the blue curve at ℓ=15; the star is
ui⋆=13/3. Reciprocal scaling bends all sixteen
boundaries; K2 adds a gradual turn, whereas the non-normal K3 combines
turning with a much stronger collapse across one tangent direction.
For these invertible kernels the curves are the actual boundaries of the
nested image sets. The Hilbert estimate begins after the first positive cycle.
Thus the global rate becomes exponentially pessimistic as
ϵ↓0. Sharper continuous analyses obtain polynomial rates
under additional semiconcavity or log-concavity assumptions
Chizat et al., 2026. In practice, monitor the marginal not just
normalized: the source residual at P(ℓ) and the target residual at
P(ℓ+1/2) are the two meaningful posterior diagnostics.
Gaussian marginals provide an explicit finite-dimensional model of Sinkhorn’s
behavior. The soft c-transform preserves quadratic potentials, the optimal
entropic coupling is Gaussian, and the value can be written with matrix square
roots Janati et al., 2020. This is the entropic counterpart of the
Gaussian W2 and Bures formula.
Proof
The exponent is the sum of a quadratic polynomial in y and the logarithm of
the Gaussian density of β. Completing the square in y evaluates the
integral as a positive constant times the exponential of a quadratic
polynomial in x. Taking −ϵlog therefore gives a quadratic
polynomial.
Proof Sketch
For any coupling, replace (X,Y) by the Gaussian vector with the same mean
and covariance. The quadratic cost is unchanged, and Gaussian laws maximize
entropy at fixed covariance, so the relative entropy cannot increase. It is
therefore enough to optimize over Gaussian couplings.
Writing the cross-covariance as
K=Σα1/2SΣβ1/2, the block covariance constraint
is equivalent to the singular values of S being at most one. The cost
depends on K through −2tr(K), while
The first-order condition is
2σi=ϵs/(1−s2), whose positive solution is the displayed
si.
Proof Sketch
The raw Gaussian entropic value is the squared mean displacement plus two
trace terms and the spectral sum
∑iψϵ(σi(Σα,Σβ)). Applying the
same formula to the self-costs (α,α) and (β,β) replaces
the cross singular values by the eigenvalues of Σα and
Σβ.
In the debiased polarization formula, the trace terms cancel:
The polarization of the squared mean terms leaves
∥mα−mβ∥2. Finally,
τϵ(r)→1 and
ϵlog(1−τϵ(r)2)→0, so
ψϵ(r)→−2r. The covariance limit is therefore
which is the Bures--Wasserstein covariance formula.
The controls below expose exactly the quantities in the formula: ϵ
sets the singular-value shrinkage, anisotropy changes the eigenvalues, and the
angle changes the covariance misalignment.
Interactive panel. This exploratory panel exposes the Gaussian formula directly. Use epsilon, anisotropy, and angle to see how entropic shrinkage changes the covariance term.
the derivative of the full-cycle map at the fixed point is
Tϵ′(q⋆)2=A⋆−4.
This scalar calculation illustrates the general Gaussian convergence picture
of Chizat, Delalande and Vaskevicius Chizat et al., 2026: the rate
improves when ϵ is large or the covariance scales overlap well, and
deteriorates in the small-temperature limit where the entropic coupling
approaches a deterministic Brenier map.
This section studies a simultaneous high-resolution, many-iteration limit. It
is not a continuous-time interpolation of a fixed-temperature algorithm: the
grid is refined while the temperature and the fictitious time step both vanish
as 1/k.
For the quadratic torus cost c(x,y)=dTd(x,y)2/2, Berman’s
scaling discretizes both marginals on a grid of mesh 1/k, sets
ϵk=1/k, and assigns duration 1/k to each Sinkhorn update
Berman, 2020. The m-th log-potential is observed at time
t=m/k. In this coupled limit, Sinkhorn becomes a parabolic Monge--Ampere flow.
To make the scaling explicit, let α(k) and β(k) be the
positive grid discretizations and define
Taking logarithms, dividing by the time step 1/k, and passing to the smooth
limit gives the stated PDE with its mean-zero gauge correction.
No explicit ϵ remains in the normalized limiting PDE: it records the
vanishing temperature before rescaling. The Kahler analogue is the parabolic
complex Monge--Ampere equation.
The positive-definite Jacobian makes T an orientation-preserving local
diffeomorphism. Since it is homotopic to the identity, it has degree one and
is a diffeomorphism of the torus. Both measures have mass one, so change of
variables gives ec=1. The identity is then exactly the Jacobian equation
for T#α=β. The converse reverses the argument.
Gaussian marginals give a finite-dimensional test case for the continuous
flow. The theorem above is stated on the flat torus, but the same local Laplace
calculation can be read formally on Rd for confining Gaussian densities.
Write α=N(mα,Σα) and
β=N(mβ,Σβ), and restrict the potential to the
quadratic ansatz for which
Thus the parabolic Monge--Ampere equation reduces, on the Gaussian ansatz, to a
Riccati evolution for the linear part of the transport. The image mean is
qt, and the image covariance is
which is equivalent to BΣαB=Σβ. The stationary map is
therefore the Gaussian Brenier map, and the endpoint covariance is governed by
the same Bures--Wasserstein geometry as in Section Entropic Optimal Transport Between Gaussians.
This Gaussian reduction should be viewed as the finite-dimensional covariance
shadow of the vanishing-temperature continuous Sinkhorn limit, not as the
fixed-temperature Gaussian Sinkhorn formula itself.
as long as 1+ut′′>0. This scalar case is useful for visualization because
the potential curves can be plotted directly and the positivity condition is
exactly the monotonicity of x↦x+ut′(x).
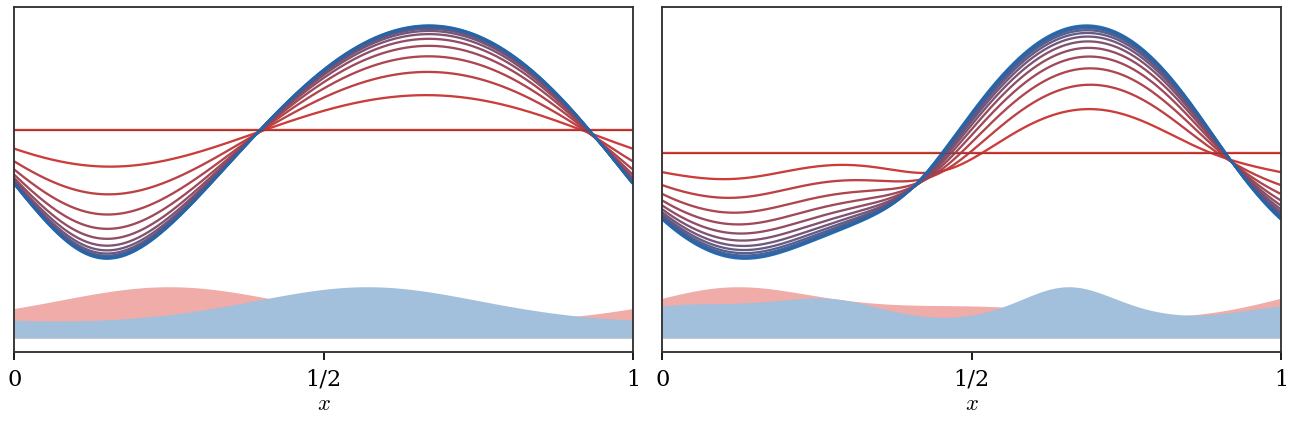
Figure Div shows this evolution from the zero initialization for two smooth pairs of marginals.
Continuous ε-Sinkhorn flow in one dimension. The curves are snapshots of
the gauge-fixed potential ut, initialized at u0=0, under the parabolic
Monge--Ampere equation obtained from Berman’s high-resolution,
vanishing-temperature Sinkhorn scaling. Time is encoded from red to blue; the
faint bottom silhouettes show the source density in red and the target density
in blue.
Interactive panel. Adjust the entropic scale and flow time to watch the log-domain continuous Sinkhorn relaxation approach the fixed-point dual potentials.
The preceding convergence mechanisms mostly used variational structure:
Sinkhorn is alternating KL projection, coordinate ascent on a dual objective, or
a contraction in a projective metric. There is another, more algebraic,
convergence mechanism which keeps the scaling form but discards the existence
of an objective. In Galichon’s equilibrium-flow viewpoint, and in related work
on substitutability and inverse isotonicity, one studies nonlinear
market-clearing equations whose Jacobian has a substitute sign structure
Galichon & Jacquet, 2024Galichon et al., 2022.
This is the nonlinear analogue of the classical theory of nonsingular
M-matrices and M-functions
Moré & Rheinboldt, 1973Plemmons, 1977. The relevance for
OT is that Sinkhorn is the canonical scaling example, but the same monotone
clearing proof also covers fixed-point equations that are not first-order
conditions of any convex regularized transport problem.
This is the Jacobi version: all coordinates are cleared against the old values
of the other coordinates. In two-block scaling problems, all coordinates in
u decouple when v is fixed, and all coordinates in v decouple when u is
fixed. The more common alternating Sinkhorn sweep is the Gauss--Seidel
composition of these two block clearings; the order argument below is stated
for the parallel map to keep the notation short. The same construction extends
to any finite number of blocks.
The M-function assumption says that cross-effects have the sign of substitutes,
and that own effects dominate them strongly enough to prevent a global reversal
of order. Galichon, Samuelson and Vernet formulate this idea through
nonreversingness and unified gross substitutes; for single-valued maps this is
the inverse-isotone structure used below. A degenerate M0-function keeps the
same order structure but allows a null gauge direction, which is exactly what
happens for balanced Sinkhorn before a potential normalization is imposed.
Proof
Let T be the coordinate-clearing map. If z∈D is a subsolution, then
Qℓ(zℓ,z−ℓ)≤0=Qℓ(Tℓ(z),z−ℓ). Diagonal
isotonicity and uniqueness of the scalar zero give zℓ≤Tℓ(z) for
every ℓ, hence z≤T(z). Since Q is a Z-function,
so T(z) is again a subsolution. Since every subsolution lies below every
supersolution by inverse isotonicity, T(z)≤z, and therefore
T(z)∈D. The supersolution argument is the same with all inequalities
reversed. The lower and upper iterates are thus monotone and trapped in the
compact interval D. Their limits exist, and passing to the limit in
Qℓ(zℓk+1,z−ℓk)=0 gives Q(z⋆)=0. If z and z′ were
two zeros in D, inverse isotonicity applied in both directions gives z=z′.
Proof
The off-diagonal sign gives the Z-property by integrating the partial
derivatives along coordinatewise increasing segments. The displayed inequalities
imply that each DQ(z) is a strictly weighted column diagonally dominant
Z-matrix, hence a nonsingular M-matrix; in particular its inverse is nonnegative
for each fixed zPlemmons, 1977. For two points
z,z′∈D, set
The matrix A has the same Z-sign pattern and the same strict weighted
diagonal dominance, so it is again a nonsingular M-matrix and A−1≥0.
Since Q(z)−Q(z′)=A(z−z′), the implication Q(z)≤Q(z′) gives
z−z′=A−1(Q(z)−Q(z′))≤0. This is inverse isotonicity. The positive
diagonal entries also give diagonal isotonicity.
The Jacobian has positive diagonal entries and nonpositive off-diagonal
entries. Its column sums vanish, reflecting the gauge invariance
(u,v)↦(u+c1,v+c1). Thus balanced Sinkhorn is naturally
an M0-system. Fixing one log-scaling coordinate turns the reduced Jacobian
into a principal minor of the weighted bipartite graph Laplacian. Under
connected support, automatic here because K>0, it is a nonsingular M-matrix. This complements
the variational and Hilbert-metric proofs above, and also connects Sinkhorn
scaling with choice models Qu et al., 2023.
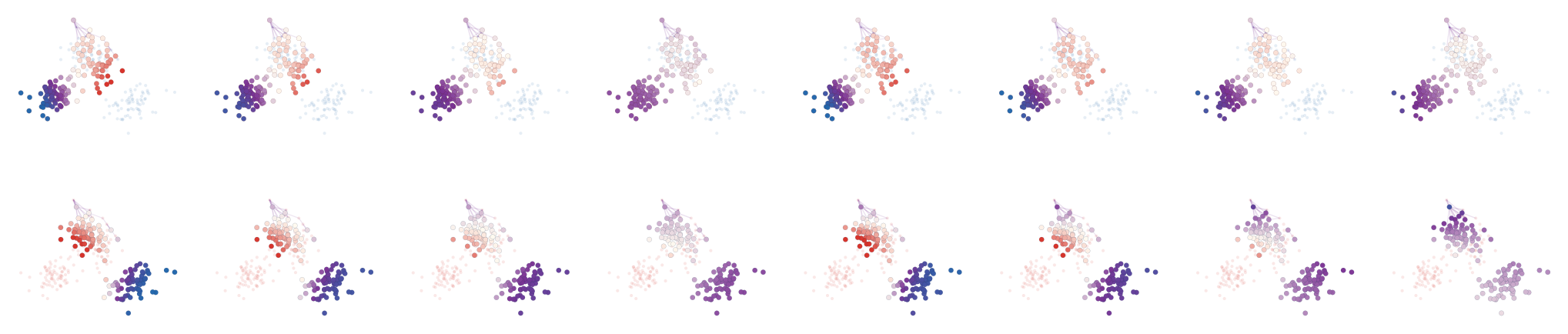
Figure Div shows this mechanism on two empirical Gaussian mixtures in R2.
Non-variational lossy Sinkhorn scaling on two Gaussian-mixture point clouds.
The outside coefficients are σi=ρσˉi and
τj=ρτˉj, and columns increase the common scale ρ.
Colors show centered log-scalings, logr−⟨logr⟩
on the source row and logs−⟨logs⟩ on the target row; faint
violet links mark the largest entries of the induced effective plan. The first displayed case
uses uniform outside coefficients, while the second uses spatially varying outside
coefficients and directional loss factors. The updates are
Sinkhorn-like row and column clearings, but ηij=1 breaks the
cross-partial symmetry required by a convex potential.
Interactive panel. Change the two monotone update temperatures to watch the source and target logarithmic scalings stabilize under a non-variational Sinkhorn-like iteration.
Bregman, L. M. (1967). The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Computational Mathematics and Mathematical Physics, 7(3), 200–217.
Ruschendorf, L. (1995). Convergence of the iterative proportional fitting Procedure. Annals of Statistics, 23(4), 1160–1174.
Rüschendorf, L., & Thomsen, W. (1998). Closedness of sum spaces and the generalized Schrödinger problem. Theory of Probability and Its Applications, 42(3), 483–494.
Blondel, M., Seguy, V., & Rolet, A. (2018). Smooth and Sparse Optimal Transport. Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, 84, 880–889. https://proceedings.mlr.press/v84/blondel18a.html
Dykstra, R. L. (1985). An iterative procedure for obtaining I-projections onto the intersection of convex sets. Annals of Probability, 13(3), 975–984.
Censor, Y., & Reich, S. (1998). The Dykstra algorithm with Bregman projections. Communications in Applied Analysis, 2, 407–419.
Bauschke, H. H., & Lewis, A. S. (2000). Dykstra’s algorithm with Bregman projections: a convergence proof. Optimization, 48(4), 409–427.
Benamou, J.-D., Carlier, G., Cuturi, M., Nenna, L., & Peyré, G. (2015). Iterative Bregman projections for regularized transportation problems. SIAM Journal on Scientific Computing, 37(2), A1111–A1138.
Bregman, L. M., Censor, Y., & Reich, S. (1999). Dykstra’s Algorithm as the Nonlinear Extension of Bregman’s Optimization Method. Journal of Convex Analysis, 6(2), 319–333.
Lemmens, B., & Nussbaum, R. (2012). Nonlinear Perron-Frobenius Theory (Vol. 189). Cambridge University Press. 10.1017/CBO9781139026079
Essid, M., & Pavon, M. (2019). Traversing the Schrödinger Bridge Strait: Robert Fortet’s Marvelous Proof Redux. Journal of Optimization Theory and Applications, 181, 23–60.
Léonard, C. (2019). Revisiting Fortet’s proof of existence of a solution to the Schrödinger system. arXiv Preprint arXiv:1904.13211.
Peyré, G. (2026). Robust Sublinear Convergence Rates for Iterative Bregman Projections. arXiv Preprint arXiv:2602.01372. https://arxiv.org/abs/2602.01372
Altschuler, J., Weed, J., & Rigollet, P. (2017). Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration. Advances in Neural Information Processing Systems, 30, 1964–1974.