This chapter keeps the idea of comparing measures while changing the geometry
of the comparison. The constructions below relax mass conservation, average
lower-dimensional projections, quotient nuisance symmetries, linearize
transport around a reference measure, replace the trace cost by spectral
gauges, or constrain motion to conditional fibers. They are useful when
standard Wp is too rigid or too expensive, but each modification also
changes which metric, geodesic, or stability properties survive.
from pathlib import Path
import sys
from IPython.display import Image as DisplayImage
from IPython.display import display
here = Path.cwd()
myst_dir = None
for candidate in [here, here.parent, here / "myst", here.parent / "myst", here.parent.parent / "myst"]:
if (candidate / "ot4ml_web.py").exists():
myst_dir = candidate.resolve()
sys.path.insert(0, str(myst_dir))
break
if myst_dir is None:
raise RuntimeError("Could not locate myst/ot4ml_web.py")
repo_root = myst_dir.parent
thumbnails = repo_root / "notebooks-figures" / "thumbnails"
def show_book_figure(name, width=760):
display(DisplayImage(filename=str(thumbnails / f"{name}.png"), width=width))
Unbalanced OT allows mass creation and destruction by penalizing marginal
mismatch. It is essential when histograms are not normalized, when
observations contain outliers, or when only part of the source should match
the target Liero et al., 2018Chizat et al., 2018Chizat et al., 2018.
where ψ1,ψ2 are convex entropy functions. Exact conservation
(π1,π2)=(α,β) is replaced by a cost for changing the
marginals. Writing ψs=τψˉs exposes the relaxation scale:
Large τ makes marginal mismatch expensive and approaches balanced OT when
the total masses are compatible. Small τ makes creation and destruction
cheap; after rescaling by τ, the zero-transport part reveals the pure
divergence geometry.
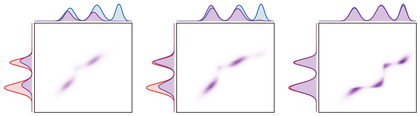
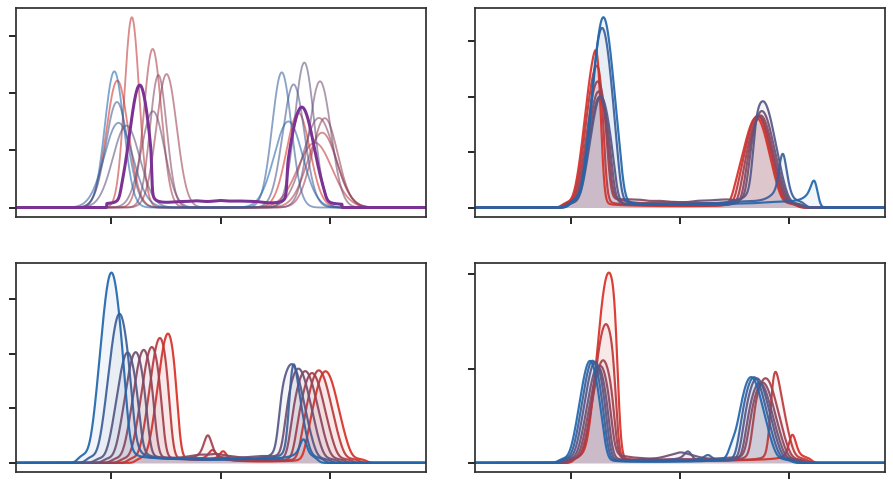
The two immediate numerical displays make the penalty roles explicit.
Div fixes a KL marginal penalty and varies
τ: the transported marginals, shown in violet, are allowed to differ from
the prescribed red and blue marginals, and the gaps are precisely the created or
destroyed mass. Div then keeps the
geometry, entropic plan regularization and relaxation strength fixed, and
changes only the marginal divergence. This isolates the effect of the penalty:
KL gives smooth rescaling, Burg discourages complete deletion of prescribed
modes, while total variation produces sharper active-mass selection.
Figure Div fixes a KL marginal penalty and varies τ: the transported marginals, shown in violet, are allowed to differ from the prescribed red and blue marginals, and the gaps are precisely the created or destroyed mass.
show_book_figure("unbalanced-mass-relaxation")
KL unbalanced OT on one-dimensional Gaussian-mixture densities. The central
matrix is the transported coupling. The side curves compare the prescribed
marginals with the transported marginals; increasing τ makes marginal
mismatch more expensive, so more mass is moved rather than created or
destroyed.
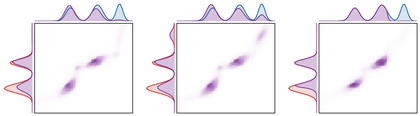
The entropy used in the marginal relaxation also changes the qualitative
behavior. A KL penalty leads to smooth multiplicative rescaling. The
reverse-KL, or Burg, penalty blows up when a transported marginal vanishes
where the prescribed marginal is positive, so it discourages complete deletion
of small modes. Total variation has a linear kink and behaves closer to
partial transport: mass is either kept active or created and destroyed at
nearly constant marginal price.
Figure Div then keeps the geometry, entropic plan regularization and relaxation strength fixed, and changes only the marginal divergence.
show_book_figure("unbalanced-divergence-choice")
Effect of the marginal divergence in unbalanced entropic OT. The geometric
cost, entropic plan regularization ϵ, and relaxation strength τ
are fixed; only the marginal penalty changes. KL allows smooth mass
variation, Burg keeps transported marginals from vanishing on prescribed
modes, and total variation gives a sharper active-mass selection.
Interactive panel. Use the middle-τ, ϵ, and grid controls to
compare KL unbalanced couplings for the same source and target marginals as in
the book figure.
These figures should be read as pictures of a single relaxed plan π: the
same nonnegative measure determines both the transported coupling and its two
relaxed marginals. The small-τ result below formalizes the opposite regime,
where transport becomes negligible compared with local mass variation.
Proof
For the upper bound, restrict to diagonal plans
π=(Id,Id)♯ρ, whose transport cost is zero and whose two
marginals are both ρ. This gives the desired upper bound after
optimizing over ρ.
For the lower bound, let τn↓0 and let πn be almost
minimizing plans with bounded scaled values
τn−1UWc,τn(α,β). Since the divergences are
nonnegative, ∫cdπn=O(τn), hence ∫cdπn→0. The
bounded scaled values also put the two marginals in compact divergence
sublevel sets. Since a coupling has the same total mass as each marginal, the
couplings are tight on X×X. Up to subsequences,
πn⇀π0.
Lower semicontinuity of the transport cost yields ∫cdπ0=0, so
π0 is concentrated on the diagonal. Its two marginals are therefore equal
to a common measure ρ. Lower semicontinuity of the marginal divergences
gives
In the dominated case, the minimization over ρ=rλ decouples into
the scalar envelope mψˉ1,ψˉ2. For KL, no
singular part is admissible when α and β are dominated by
λ. The pointwise objective is
rlog(r/a)−r+a+rlog(r/b)−r+b. Its optimality condition is
log(r/a)+log(r/b)=0, hence r=ab, and the minimum is
a+b−2ab=(a−b)2.
Proof
Use the variational formula for the dual of a divergence and introduce the
marginal variables through continuous potentials:
The Liero--Mielke--Savare formulation rewrites marginal penalties as a local
transport cost and then homogenizes it. Assuming first that the reference
measures and transported marginals have mutually absolutely continuous parts,
one can factor the objective as
with the usual recession convention at r=0 or s=0. If
α=Fπ1+α⊥ and β=Gπ2+β⊥ are the Lebesgue
decompositions of the reference marginals with respect to the transported
marginals, then
The cases u=0 or v=0 encode the recession terms and therefore mass that is
created or destroyed rather than transported.
Proof
Since Hc(r,s)≤Lc(r,s) by choosing scale one, every competitor in the
reverse formulation gives a homogeneous competitor of no larger cost. Hence
HW≤UW.
Conversely, fix a feasible semi-coupling (λ,u,v) in
(15). For a positive measurable scale θ,
set π=θλ. Disintegrate λ with respect to its
first spatial marginal. If uˉ(x) and θˉ(x) are the conditional
averages of u and θ, then
α=uˉ(p1)♯λ and
π1=θˉ(p1)♯λ. Convexity of the
perspective (a,m)↦aψ1(m/a) and conditional Jensen give
The pointwise infimum over θ>0 is Hc(u,v). A measurable
η-minimizing scale exists by the normal-integrand selection theorem; the
recession conventions cover vanishing weights. Letting η↓0 and
then minimizing over semi-couplings gives
UW≤HW.
Assume now that X=Y and ψ1=ψ2=ψ. The homogeneous formulation
lifts the problem to the cone space
C[X]:=(X×R+)/∼, where all points (x,0) are
identified at the apex. For an exponent p≥1, define
This is a cone metric when the Gaussian kernel
k(x,y)=e−d(x,y)2/2 is positive definite. In particular, this holds on
subsets of Hilbert spaces. Positive definiteness is an additional
hypothesis on a general metric space.
Dψ=TV, p=1, and c(x,y)=d(x,y) give the partial-transport
cone cost
Its weighted base marginals are α,β, and its cone action is exactly
∫Hc(x,y)(u,v)dλ, so
CW≤HW. Conversely, disintegrate a cone plan over
(x,y) and set u=E[rp∣x,y] and
v=E[sp∣x,y]. Jensen’s inequality for the convex function Hc
produces a feasible semi-coupling of no larger action. Hence
HW≤CW.
For the triangle inequality, two plans that share the same weighted middle
projection need not share the same ordinary cone marginal. Homogeneity is the
essential correction: common radial rescaling preserves weighted projections
and action. After normalization and addition of harmless apex mass, two nearly
optimal plans for (α,β) and (β,ζ) can be given the same
ordinary middle lift
for a sufficiently large finite M. The ordinary gluing lemma and Minkowski’s
inequality then prove the triangle inequality. Radial normalization by
(rp+sp)1/p also restricts minimizing plans to bounded radii and fixed
mass; compactness and lower semicontinuity yield an optimizer. A zero-action
optimizer is concentrated on the cone diagonal, so its two weighted
projections coincide and α=β.
The exponent ω<1 is the visible difference with balanced Sinkhorn:
marginal corrections are damped because violating the marginals is allowed.
The KL case in Div is obtained from these
damped updates. The interactive panel above exposes the two most important
regularization scales. Increasing τ pushes the transported marginals closer
to the prescribed ones; increasing ϵ spreads the coupling itself.
Balanced entropic potentials have a gauge ambiguity, whereas KL marginal
penalties make the unbalanced potentials unique up to null sets. The natural
metric is therefore the ordinary L∞ distance on potentials, or,
equivalently, the Thompson metric on positive scalings,
Total variation gives a sharp active-mass selection and connects unbalanced OT
with the classical partial-transport problem. The latter fixes in advance the
amount of transported mass. For
Thus only a submeasure of α is transported onto a submeasure of β;
the remaining mass is left unmatched. The corresponding Lagrangian form is
obtained by adding total-variation penalties. For a price λ>0 for
discarding or creating one unit of mass, denote by
POTλTV(α,β) the value
Assume c≥0. Allowing transported marginals larger than the available
marginals does not improve the value: excess transported mass can be trimmed,
which decreases the transport cost and cannot increase the sum of the two
total-variation penalties. Hence an optimal plan may be chosen with
π1≤α and
π2≤β. If m=π(X×Y), the penalty then reduces to
so the precise relation is a one-dimensional Lagrange duality in the transported
mass.
Proof
Write V(m)=POTm(α,β). Compactness gives an optimizer.
Convex combinations of subcouplings show that V is convex, while rescaling a
plan shows that it is nondecreasing. If m0<m1, choose submeasures of mass
m1−m0 from the residual source and target measures of an optimizer at
m0, couple them, and add this coupling. This proves
V(m1)−V(m0)≤∥c∥∞(m1−m0), so V is Lipschitz.
Grouping every penalized competitor by its total transported mass gives the
displayed scalar infimum. Equality forces simultaneous optimality in the
fixed-mass and scalar problems. The converse is precisely the subgradient
inequality. Since the extended convex function is Lipschitz on [0,M] and
nondecreasing, a nonnegative subgradient exists at every mass after including
the interval’s normal cone.
Proof
When both endpoint masses equal m, the inequalities
π1≤α, π2≤β and the mass constraint force
π1=α, π2=β. Thus partial couplings are exactly balanced
couplings, and normalization by m gives the formula. On a larger class,
α=mδx+rδy and β=mδx+rδz are distinct but
share the zero-cost partial plan mδ(x,x).
Thus TV penalization is the Lagrangian envelope of constrained partial OT:
increasing λ selects larger transported masses, while small λ
makes deletion and creation cheaper. The constrained theory, including active
regions and free boundaries, was developed
by Caffarelli--McCann and
Figalli Caffarelli & McCann (2010)Figalli (2010). Modern computational and
learning applications include partial Wasserstein and partial
Gromov--Wasserstein variants, for instance in
Chapel--Alaya--Gasso Chapel et al. (2020).
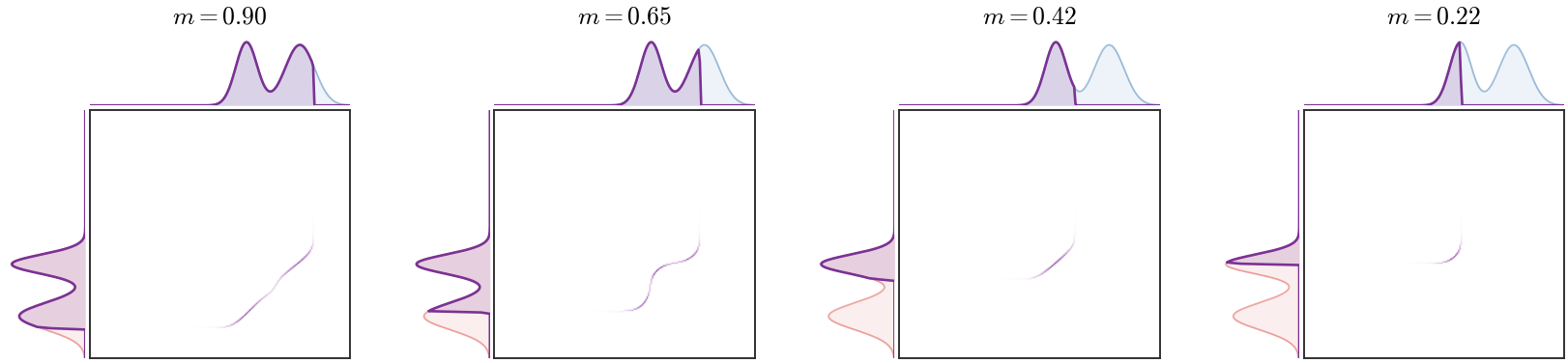
Figure Div shows this active-region mechanism for two one-dimensional two-Gaussian mixtures, with the source mixture shifted to the left and the target mixture shifted to the right.
show_book_figure("partial-ot-active-mass")
Partial optimal transport with prescribed transported mass. The central image is
the optimal subcoupling, with contrast normalized independently in each panel to
keep the low-mass plans readable. The pale red and blue side curves are the
original source and target densities, while the violet curves are the active
truncated marginals. As the transported mass decreases, only the lowest-cost
overlapping parts remain matched and the remaining mass is left unmatched.
Interactive panel. Decrease the transported mass to see how partial OT
selects active submarginals and leaves the rest unmatched.
The same mechanism becomes a geometric active-region selection in higher
dimension. Div shows a two-dimensional
shape example: the partial plan selects the closest pieces of the two supports,
while leaving distant regions unmatched.
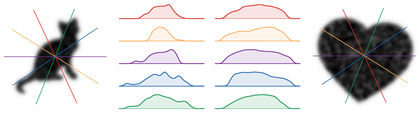
Two-dimensional partial optimal transport between a red cat-shaped indicator
measure and a blue annulus indicator measure. Both supports are sampled by
farthest-point sampling. Saturated points are the active source and target
marginals of the optimal partial plan, while pale points are available mass left
unmatched. As the prescribed mass decreases, the active regions contract to the
nearest compatible pieces of the two shapes.
Interactive panel. Vary the transported mass to see which source and target points remain active when partial transport discards outlying mass.
The idea was proposed by Marc Bernot, and its first published use for
Wasserstein barycenters and texture mixing is due to Rabin, Peyré, Delon and
Bernot Rabin et al., 2011. It is cheap, differentiable after sorting, and
often effective in imaging and learning. For measures on Rd and
θ∈Sd−1, let Pθ(x)=⟨θ,x⟩.
The projected measures live on the real line, where Wasserstein distances are
explicit through sorting or quantiles. Averaging over directions defines the
sliced distance.
Since each projected problem can be solved by sorting or quantiles,
SWp is much cheaper to approximate numerically than
high-dimensional OT. It metrizes the
same weak-plus-moment topology as Wp, but its geometry is not
bi-Lipschitz equivalent to Wp in high dimension
Nadjahi et al., 2019.
Figure Div turns this Radon viewpoint into a concrete comparison: each planar density produces a family of one-dimensional projected laws, which can then be compared by ordinary one-dimensional Wasserstein distances.
Sliced Wasserstein projections between two planar densities. Fixed directions
are drawn on both densities, and the middle panels show smoothed
one-dimensional density estimates of the projected measures. Sliced OT
averages one-dimensional Wasserstein discrepancies over many such directions.
The interactive demo separates two uses of a slice: comparing projected measures and
lifting the sorted one-dimensional matching back to the plane. The lifted plan
is always feasible in the original space, but it need not be the quadratic
optimal plan.
Interactive panel. Use the projection angle and number of directions to see how sliced Wasserstein distances reduce high-dimensional transport to one-dimensional matchings.
Proof
Non-negativity and symmetry follow from the one-dimensional Wasserstein
distance. For the triangle inequality, apply the triangle inequality of
Wp in every direction and then Minkowski’s inequality in
Lp(Sd−1).
If SWp(α,β)=0, the projected measures agree for
almost every direction. Continuity of characteristic functions extends the
equality to all directions, and Cramér--Wold gives α=β.
Let π be any coupling of α and β. Projecting π gives
Integrating the projected bound and optimizing over π proves the direct
comparison. The beta-integral formula for the first coordinate of a uniform
point on the sphere gives the displayed value of κd,p.
For the topology, Wp convergence implies sliced convergence by this
upper bound. Conversely, if SWp(αn,α)→0, then
The projected-quantile formula gives uniform moment bounds and hence
tightness. Every subsequence has a further subsequence whose projected
Wp distances vanish for almost every direction; Cramér--Wold identifies
every weak limit with α. If Qn,θ and Qθ are the
projected quantiles, then
by smoothing a Kantorovich--Rubinstein test function, representing the smoothed
test through one-dimensional projections, and optimizing the smoothing scale.
On BR,
The first inequality evaluates the p-cost on a W1-optimal coupling;
the second uses W1≤Wp on each slice and Hölder’s inequality in
the direction variable. They give Bonnotte’s general-p estimate. The sharper
p=1 theorem of Carlier, Figalli, Mérigot and Wang
Carlier et al., 2025 replaces 1/(d+1) by the
optimal exponent 1/d. Combining it with the same two inequalities gives
which is equivalent to the final two-sided formulation. Thus every p admits
a bounded-support lower bound on SWp in terms of Wp;
sharpness is asserted only for p=1.
The infinitesimal comparison is most transparent along smooth Brenier
perturbations. The usual Wasserstein distance sees the full L2(α) norm
of the displacement, while slicing sees only its one-dimensional projections.
The same result also isolates the different behavior of finite atomic curves.
where ∣γ˙t∣SW2 is the metric derivative. Park and Slepčev
prove that the infimum is attained, so (P2(Rd),ℓSW2) is a
geodesic space. Every path length dominates the endpoint distance, while
Proposition Proposition: Metric Properties of Sliced Wasserstein bounds the sliced length of a
W2-geodesic. Therefore
Neither inequality identifies the intrinsic geometry with a rescaled
Wasserstein geometry. Proposition Proposition: First-Order Comparison: Strictness and Atomic Equality shows
that the sliced metric derivative equals d−1/2 times the Wasserstein
metric derivative along finite atomic curves with fixed weights. By contrast,
the Gaussian deformation in the same proposition is strictly slower for
SW2. Its sliced speed depends continuously on time, so strictness persists
on a short interval. Integrating along that W2-geodesic gives, for every
sufficiently small t=0,
There is no reverse comparison by a constant depending only on dimension.
Example 3.2 of Park and Slepčev considers two nearby parallel line segments
moving in opposite directions. Most projected motions cancel after slicing:
for every δ>0, the construction produces a compactly supported atomless
curve (αtδ)t such that, for small t≥0,
Thus ℓSW2 and W2 are not globally bi-Lipschitz equivalent,
even after inserting the factor d−1/2.
The atomic equality remains stable in its natural regime. If η is a fixed
finite atomic measure with positive masses and separated atoms, Theorem 5.5 of
Park and Slepčev gives
along β=η. By contrast, under suitable common-support and density
bounds in the diffuse regime, their Theorem 5.2 shows that both SW2 and
ℓSW2 are locally equivalent to H˙−(d+1)/2, while the
infinitesimal geometry of W2 around a positive density is of
H˙−1 type. These results settle the comparison: the intrinsic sliced
metric agrees asymptotically with d−1/2W2 near finite atomic measures,
but it is genuinely different globally and around diffuse measures.
Gaussian projections remain Gaussian, so quadratic sliced transport reduces
to the one-dimensional Gaussian formula in every direction. This gives an
exact angular representation and makes its relation with the Bures covariance
geometry explicit.
Indeed, (Pθ)♯α is the one-dimensional Gaussian with mean
θ⊤mα and variance
θ⊤Σαθ. The one-dimensional Gaussian formula,
followed by the spherical identity
∫θθ⊤dσ(θ)=Id/d, proves the displayed
expressions. For positive-definite covariances, let A be the Bures transport
matrix, so that AΣαA=Σβ. Cauchy--Schwarz for the
Σα-inner product gives
Integration yields the fidelity bound above because
tr(ΣαA)=tr[(Σα1/2ΣβΣα1/2)1/2]. The singular case follows by continuity.
Equality forces Aθ to be collinear with θ in every direction,
hence A=rId and Σβ=r2Σα.
The spherical formula is exact, but for generic anisotropic covariances it has
no Bures-like matrix-square-root simplification and is evaluated by angular
quadrature or Monte Carlo. In dimensions d>1, nonidentical measures cannot
satisfy SW2=W2 under normalized spherical averaging; the two
distances coincide in dimension one.
Two isotropic covariances saturate the normalized upper bound:
To obtain the cross term, rotational invariance allows
u=e1 and v=χe1+1−χ2e2. Writing
(θ1,θ2)=R(cosφ,sinφ), with φ uniform and
E[R2]=2/d, reduces the calculation to an elementary angular
integral.
Aligned rank-one covariances saturate the normalized upper bound, whereas
centered, orthogonal, equal-scale covariances satisfy
SW2=1−2/πW2/d. Thus sliced transport retains the
relative angle but attenuates it through angular averaging rather than the
linear Bures factor χ. The corresponding Gaussian sliced-Wasserstein
flow is revisited in the Gaussian closure catalogue.
The exponent used to aggregate projection directions need not coincide with
the transport exponent. A second exponent q controls this aggregation:
finite q pools information from many directions, whereas q=∞ retains
only the most discriminating one. Independently, replacing lines by
k-dimensional subspaces preserves more correlations at the price of solving
higher-dimensional projected OT problems. These two choices fit into one
family.
Metricity and the direct comparison with Wp carry over from ordinary
slicing. The topological statement requires slightly more care when q<p:
although an abstract Lq norm need not control an Lp norm, projected
Wasserstein profiles have enough continuity and moment control to rule out
concentration in a vanishing set of subspaces. The next proposition separates
the roles of p, q, and k.
Proof
Write
DU(α,β)=Wp((U⊤)♯α,(U⊤)♯β).
Non-negativity and symmetry are inherited from Wp, while Minkowski’s
inequality in Lq(σd,k), or the supremum triangle inequality for
q=∞, proves the triangle inequality. The reverse triangle inequality
for Wp shows that U↦DU(α,β) is continuous. Indeed,
Thus SWp,q,k(α,β)=0 implies DU=0 for every U: this is
immediate for q=∞, while for finite q it follows from continuity and
the full support of σd,k. Choosing a frame whose first column is any
prescribed θ∈Sd−1 shows that all one-dimensional
projections of α and β agree; Cramér--Wold gives α=β.
Every U⊤ is 1-Lipschitz, so DU≤Wp, and monotonicity of
Lq norms proves the first comparison. To compare dimensions, let
V∈St(d,ℓ) and R∈St(ℓ,k). Since
(VR)⊤=R⊤V⊤, projection contraction gives DVR≤DV.
Moreover, VR is uniformly distributed on St(d,k) when V
and R carry their invariant measures. Integration proves monotonicity in
k; the supremum case follows by extending each k-frame to an ℓ-frame.
Integrating in U and minimizing in π gives
∥D⋅∥Lpp≤κd,k,pWpp. Monotonicity of Lq norms
proves the case q≤p; for q≥p, combine this estimate with
DU≤Wp. Finally, average
over U and ω∈Sk−1. Since Uω is uniform on
Sd−1, this gives SWp≤SWp,p,k. For q≥p, this also
transfers the compact-support reverse estimates for ordinary sliced
Wasserstein.
It remains to prove the topological assertion. Define
Mp(η)=(∫∥x∥pdη(x))1/p. For the Dirac mass at the origin,
Consequently, if SWp,q,k(αn,α)→0, the triangle inequality
gives a uniform bound on Mp(αn). The functions
Dn,U=DU(αn,α) are therefore uniformly equicontinuous because
On the compact Stiefel manifold, equicontinuity and full support upgrade
Lq convergence to uniform convergence. Choosing a frame whose first column
is θ then shows uniformly that
The preceding constructions compare projected measures. Min-SW uses a
projection differently: it lifts the one-dimensional monotone coupling back
to the ambient space and retains the lift with the smallest quadratic cost.
Consider equal-weight empirical measures
α=n−1∑iδxi and
β=n−1∑iδyi. For a direction θ along which both
projected point families have distinct coordinates, let
σθ,τθ∈Sn be their sorting permutations:
The cost of (104) is an upper bound on
W2(α,β)2, and Min-SW minimizes this upper bound over
θ. This inexpensive feasible-plan construction was introduced by
Mahey, Chapel, Gasso, Bonet and Courty
Mahey et al., 2023.
Projected ties make the extension beyond this generic empirical setting less
immediate. At a tie, the sorting permutations are not unique. Breaking ties
by labels is not invariant under a relabeling of the atoms, while a
lexicographic rule depends on an auxiliary coordinate system; both choices can
be discontinuous under perturbations. For a non-discrete measure, a projection
fiber may carry an entire conditional distribution, so there are no labels to
sort. Tanguy, Chapel and Delon
Tanguy et al., 2025 avoid arbitrary tie
breaking by optimizing over all compatible lifts. Set
Both minima are attained for α,β∈P2(Rd)Tanguy et al., 2025. Unlike the particular
lift (109), the inner minimization may correlate the
conditional laws on
Pθ−1(s)×Pθ−1(t); it chooses the least costly
transverse coupling compatible with the prescribed projected coupling. When
the empirical projections have no ties,
Cθ(α,β)={πθ} and
(110) reduces to (104).
For comparison, fixing θ before comparing the measures restores a
metric on equal-weight n-point clouds whose θ-projections are
injective: it is n−1/2 times the Euclidean distance between the two tuples
ordered along θ. The constrained fixed-direction extension is likewise
a metric on the class of measures with atomless θ-projections
Tanguy et al., 2025. It is the subsequent
pair-dependent minimization over θ that destroys the triangle
inequality. In dimension one no such directional choice remains, and
Min-SW2=W2.
The right-hand side of (111) and the diameter estimate are
absolute upper bounds, not multiplicative comparisons with W2. Beyond
the exactness criterion above, the cited theory does not provide a universal
converse of the form Min-SW2≤CW2.
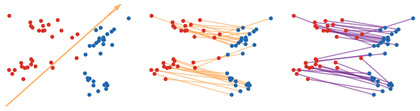
Figure Div illustrates the resulting gap: the direction selected by Min-SW produces a valid lifted planar coupling, but that coupling need not be the quadratic optimal plan.
show_book_figure("min-sliced-transport-plan")
Min-SW lifted plan. A deterministic angular sweep selects a projection,
after which the red and blue atoms are sorted and matched in one dimension.
The middle panel lifts this matching back to the plane. Its cost upper-bounds
W22, but the resulting feasible plan need not equal the quadratic optimal
plan shown on the right.
Interactive panel. Rotate the slicing direction to see how one-dimensional
sorting induces a lifted feasible plan in the original plane.
Many comparison problems contain nuisance transformations: two shapes, images
or point clouds should be considered close after translating, rotating or
otherwise reparametrizing one of them. Quotient Wasserstein distances encode
this idea by computing transport after optimizing over a group action. This
construction is the metric analogue of passing from objects to shapes modulo
symmetries, and connects OT with shape spaces, metamorphosis models and
global-invariance variants of transport
Trouvé & Younes, 2005Zemel & Panaretos, 2019Alvarez-Melis et al., 2019.
Proof
Isometry of the action gives
Wp(g♯α,g♯β)=Wp(α,β), which proves the second
formula above. Non-negativity and symmetry are inherited from Wp. For
the triangle inequality, choose g1,g2∈G and write
The triangle inequality for Wp, followed by the infimum over
g1,g2, gives the result. If the infimum is attained and the quotient
distance is zero, there exist g,h∈G such that
Wp(g♯α,h♯β)=0, hence
g♯α=h♯β, which is exactly equality of the two orbits.
For compact groups, continuity of the action and compactness give the required
attainment. Without attainment, distinct orbits at zero orbit distance must be
identified to obtain a genuine metric space.
The most common example is the Euclidean group
E(d)=O(d)⋉Rd. For measures on Rd,
quotienting by rotations and translations gives the Wasserstein-Procrustes
problem
Replacing O(d) by SO(d) enforces orientation
preservation.
This is the case p=2 of the quotient distance; for a general exponent p,
one replaces the quadratic cost by the pth power of the Euclidean distance.
Although the translation group is noncompact, the quadratic problem is well
behaved: for fixed R and π, the optimal translation aligns Rxˉ with
yˉ. The remaining rigid step is therefore an orthogonal Procrustes
problem over the compact group O(d).
For empirical measures, this couples a transport problem with a rigid
registration problem. Classical iterative closest point methods alternate
nearest-neighbor assignment and rigid least squares Besl & McKay, 1992.
Wasserstein-Procrustes replaces these hard many-to-one nearest-neighbor
correspondences by a mass-preserving OT plan. This makes the registration
less tied to sampling density and better suited to ambiguous correspondences.
Two complementary machine-learning formulations clarify the scope of this
construction. Grave, Joulin and Berthet Grave et al., 2019
formulate unsupervised alignment of high-dimensional embeddings as a
Wasserstein-Procrustes problem. In their equal-weight setting, one jointly
estimates an orthogonal matrix and a permutation; they use a convex-relaxation
initialization and a stochastic large-scale solver, with bilingual lexicon
induction as the main application. Alvarez-Melis, Jegelka and Jaakkola
Alvarez-Melis et al., 2019 place the same idea in a broader framework: the
coupling and a latent global transformation are optimized jointly over a
flexible invariance class because cross-space costs are otherwise ill-defined.
The rigid quadratic model and block updates below are the isometric Procrustes
specialization of this global-invariance viewpoint.
This is an extrinsic counterpart of the Gromov--Wasserstein viewpoint
developed in Gromov--Wasserstein. Procrustes alignment searches only
over ambient rigid motions, whereas GW is invariant under intrinsic
measure-preserving isometries. The following comparison makes this relation
precise.
Proof
Fix g,h∈E(d). For every coupling
π∈Π(α,β), the push-forward
π=(g×h)♯π, where
(g×h)(x,y)=(g(x),h(y)), couples g♯α and
h♯β. Rigid motions preserve pairwise Euclidean distances, so the
GW objective has the same value at π and π. Applying the
same argument to g−1 and h−1 proves
Taking the infimum over g,h∈E(d) proves the claim.
Thus a good Wasserstein-Procrustes registration certifies small GW distortion.
The converse need not hold: GW may be small because of an intrinsic
correspondence that is not induced by an ambient rigid motion. The Mémoli
profile lower bound in Proposition: Memoli Profile Lower Bound gives the
complementary intrinsic lower certificate.
The empirical problem naturally suggests an alternating minimization. Given a
current rigid motion (R(k),t(k)), first compute the OT coupling between
the registered source cloud and the target cloud,
or by the same formula with R∈SO(d) if orientation should be
preserved. The first step is an ordinary discrete OT problem with the current
registered cost matrix; the next proposition shows that the second step is an
orthogonal Procrustes problem with an explicit singular-value formula.
Proof
For fixed R, differentiating with respect to t gives
t=yˉ−Rxˉ. Substituting this value centers the variables and leaves
The two quadratic terms independent of R are fixed, so the problem is
equivalent to maximizing
∑i,jPij⟨R(xi−xˉ),yj−yˉ⟩=tr(R⊤MP). Von Neumann’s trace inequality gives the maximum for
R=UV⊤. Under the constraint R∈SO(d), the same argument
applies with the additional determinant constraint on U⊤RV, which
gives the displayed diagonal correction.
Equations (122)--(123)
give a block-coordinate method. The objective is not jointly convex, so the
scheme should be read as a registration heuristic for the quotient problem
rather than as a global solver. The exact block update moves the rigid motion
fully; for visualization or continuation, one may damp the displayed motion
between two successive poses.
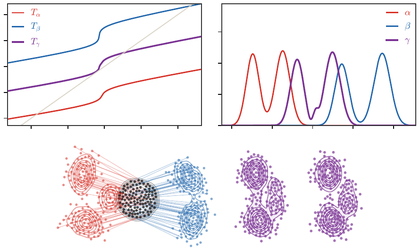
Figure Div follows this block-coordinate scheme through a deliberately large translation, showing how the transport correspondences and the rigid registration stabilize together.
Wasserstein-Procrustes alignment of two bunny silhouettes under a strong
translation and a moderate rotation. The target silhouette is shown in black.
The moving source silhouette is sampled by farthest-point sampling and colored
from red to blue at iterations (1,2,3,5,10). Each step solves an equal-weight
OT assignment, then updates the rigid motion by the closed-form Procrustes
formula; faint segments show selected correspondences of the current OT
assignment. The displayed motion is damped only to make the registration path
visible, while the underlying update is the block-coordinate method above.
Interactive panel. Step through the alternating OT assignment and rigid
Procrustes updates. Changing the true deformation, damping, noise level and
number of points shows when the block-coordinate registration is stable and
when correspondences start to lock onto the wrong silhouette parts.
Linear OT starts from the multivariate analogue of quantile coordinates. The
one-dimensional quantile function represents a probability measure by the
monotone map sending a fixed reference law to it; in dimension d>1,
Brenier’s theorem gives the corresponding construction after choosing an
absolutely continuous reference probability ρ, typically the uniform law
on a convex body or a standard Gaussian.
This construction is canonical only after fixing ρ: changing the
reference law changes the coordinates used to represent α. The same
transport-based quantile map has been used in several complementary
statistical directions. Conditional vector quantile regression replaces
scalar conditional quantiles by conditional Brenier maps
Carlier et al., 2016Carlier et al., 2017; Monge--Kantorovich
ranks and depth use transports to a spherical reference
Chernozhukov et al., 2017; center-outward distribution and quantile
functions build multivariate ranks and signs from the forward and inverse maps
Hallin et al., 2021; and scalable nonlinear vector quantile
regression learns such conditional maps with flexible models
Rosenberg et al., 2023.
Linear OT replaces a nonlinear transport distance by a Hilbert norm between
reference maps. It is useful when one reference measure is fixed and many
nearby distributions must be compared cheaply. Let Tα be the Brenier
map pushing ρ to α, understood as an element of
L2(ρ;Rd) and hence defined only ρ-almost everywhere. The linear
OT embedding is
If one of the two targets equals the reference, the linearized distance is
exact: for instance,
LOTρ(ρ,α)=∥Tα−Id∥L2(ρ)=W2(ρ,α). For two arbitrary targets, the coupling
(Tα,Tβ)♯ρ is admissible but not generally optimal, so
LOTρ is a tangent-space approximation of the Wasserstein
geometry. Introduced for the analysis of image populations
Wang et al., 2013, LOT has subsequently been used for continuous
image-pattern analysis Kolouri et al., 2016, provable
classification of transformed distributions Moosmüller & Cloninger, 2023,
collider-event analysis Cai et al., 2020, and scalable Wasserstein
dimensionality reduction Cloninger et al., 2025. Uniqueness of the
Brenier maps also shows that LOTρ is a genuine distance
on the class of targets for which these maps are defined.
For a family (αs)s with weights (λs)s, the linearized
barycenter is obtained by averaging maps,
This is exact in one dimension, where quantile functions linearize
W2, and it is especially useful when many barycenters with changing
weights must be evaluated quickly.
Figure Div makes the LOT embedding explicit: map averaging is exact in one-dimensional quantile coordinates, whereas in two dimensions its linearized barycenter can differ from the genuine McCann midpoint.
show_book_figure("dualnorms-linear-ot-embedding")
Linear OT coordinates. Fixing a reference measure ρ turns each target
into a map Tα from ρ to α, or equivalently into the
displacement field Tα−Id. In one dimension this is exactly the
quantile parametrization of W2. In two dimensions, averaging the maps
gives the linearized barycenter, which is compared with the genuine McCann
midpoint.
The next control keeps the exact one-dimensional setting. The reference
density defines the coordinate system, the target maps are quantile maps from
that reference, and the barycenter is obtained by averaging those maps before
pushing the reference forward.
Interactive panel. Use the reference and deformation controls to inspect how linear optimal transport embeds measures through maps from a fixed template.
The usefulness of these coordinates depends on controlling how much they distort the underlying Wasserstein geometry. The following global estimate is therefore important: LOT always dominates W2, while on compact supports with a uniform reference it remains Hölder-continuous with respect to perturbations measured by W1.
Proof
The first inequality is immediate:
(Tα,Tβ)♯ρ is a feasible coupling between α and
β. The second inequality is the global quantitative stability theorem of
Mérigot, Delalande and Chazal Mérigot et al., 2020. Its proof controls
the difference of Kantorovich potentials by W1 and then uses convexity
and interpolation estimates to control their gradients in L2(ρ).
In one dimension, quantiles make the embedding isometric and the exponent
improves to one. In several dimensions the theorem is global but only Hölder;
it is not a global Lipschitz estimate in W2.
The preceding embedding turns probability measures into displacement fields
in a fixed Hilbert chart, so ordinary principal component analysis can be
applied to deformations rather than to densities. Given training measures
(αi)i=1N, set
and its leading orthonormal eigenvectors ek define the principal linear OT modes.
Equivalently, one diagonalizes the N×N Gram matrix
Gij=N1⟨zi−zˉ,zj−zˉ⟩L2(ρ). If
Gv(k)=λkv(k) with λk>0 and
∥∥v(k)∥∥=1, then
For small excursions around the mean displacement, this gives a practical
tangent-space PCA for probability measures: it captures dominant modes of
deformation while avoiding repeated pairwise OT computations. For large
coefficients, Ta may fail to be the Brenier map from ρ to
αa, and may even leave the regular chart where Ta is a gradient
of a convex function. Thus the curve a↦αa should be read as a
chart-dependent linearized visualization rather than as an intrinsic
Wasserstein geodesic. This LOT-PCA viewpoint was introduced for image
variability analysis in Wang et al., 2013 and developed in
transport-based signal analysis
Thorpe et al., 2017Kolouri et al., 2017; it complements
intrinsic principal-geodesic or geodesic-PCA approaches, which optimize
directly in the curved Wasserstein space
Seguy & Cuturi, 2015Bigot et al., 2017.
Figure Div first shows the exact one-dimensional case.
show_book_figure("linear-ot-1d-pca", width=760)
One-dimensional linear OT PCA for well-separated synthetic two-Gaussian mixtures. The PCA is fit on a large training ensemble, while the dataset panel displays only representative densities and the quantile average in violet. Each mode panel shows densities obtained from (Q_{\bar\alpha}+a e_k), using slightly extrapolated coefficients (a) increasing from red to blue. Since the embedding is the exact quantile parametrization (Q_\alpha\in L^2(0,1)), this is PCA in exact Wasserstein coordinates.
Figure Div then illustrates a regularized numerical approximation of the same construction on MNIST digit-zero images.
Principal components in linear OT coordinates for MNIST digit-zero histograms.
The reference is a Sinkhorn barycenter, and each mode panel displays negative,
zero, and positive excursions in a tangent displacement direction. The panels
use white for zero displayed mass and black for high displayed mass; this is only
a rendering convention. The modes capture rotations, aspect-ratio changes, and
stroke-thickness deformations in the chart around the barycenter.
Interactive panel. Use the reference and deformation controls to inspect how
linear optimal transport turns measures into displacement coordinates.
Spectral OT changes the scalar quadratic cost by measuring the whole
displacement covariance through a matrix gauge. The same object admits a
robust projected formulation: instead of fixing one projection, one maximizes
over the polar set of the gauge. Subspace robust OT is the important
non-convex rank-constrained version of this idea Paty & Cuturi, 2019;
spectral gauges provide its convex minimax counterpart and connect to recent
spectral-gradient viewpoints such as Muon dynamics Peyré, 2026.
The monotonicity condition means that increasing the displacement covariance
in Loewner order cannot decrease the transport penalty.
The special case γ(M)=tr(M) gives the usual quadratic Wasserstein
distance W2. The spectral gauge γ(M)=λmax(M) instead
measures the worst transported variance direction. For A⪰0, define
the quadratic projected transport cost
The equality remains valid when A is singular. Projecting any coupling gives
one inequality; conversely, disintegrate α and β over their
A1/2-images and lift an optimal projected coupling by conditionally
coupling the fibers.
with the usual endpoint conventions. Thus the trace gauge has polar set
{A:0⪯A⪯I}, the Frobenius gauge is self-polar on
S+d, and the spectral gauge has polar set
{A⪰0:tr(A)≤1}.
The coupling set is convex and compact for weak convergence under compact
support. The polar set Bγ is convex and compact, and the map
(π,A)↦tr(AMπ) is affine in each variable and continuous. Sion’s
minimax theorem gives
For fixed A⪰0, W2,A is the Wasserstein pseudodistance
associated with the seminorm x↦∥∥A1/2x∥∥. A supremum of
pseudodistances is symmetric and satisfies the triangle inequality. If
aI∈Bγ and A⪯bI for all
A∈Bγ, then
and, since M⪰0, the associated support function is the same Ky Fan
gauge. Thus Wγk is the convexified spectral counterpart of
SRW2,k, while SRW2,k keeps the
original non-convex rank constraint. More precisely,
Indeed, Bγk contains the rank-k projectors and
(k/d)I, and it is contained in {0⪯A⪯I}. For k=1,
γ1(M)=λmax(M) and
Bγ1={A⪰0:tr(A)≤1}.
Figure Div compares the trace and top-eigenvalue geometries at both levels: the selected transport plans and the displacement interpolations they induce.
show_book_figure("spectral-wasserstein-gauge")
Trace and spectral gauges for displacement covariances. The trace gauge
minimizes the average squared displacement and gives the usual quadratic
transport plan. The λmax gauge penalizes the worst projected
displacement variance; the displayed plan is obtained by approximating the
robust formulation with finitely many directions.
The interactive demo turns the displacement covariance into a visible object. The
trace gauge sums both covariance eigenvalues, while the top-eigenvalue gauge
cares only about the worst transported direction.
Interactive panel. Use the spectral weights and deformation controls to see how the gauge changes the geometry used to compare measures.
Many applications compare probability laws while keeping an external condition
fixed: a class label, a time variable, a spatial location, or, later in
Section Conditional Wasserstein Training of Infinite ResNets, the depth of a residual network. The
resulting geometry is a fiberwise, or conditional, version of optimal transport.
It is based on disintegration of measures and is closely related to conditional
and constrained variants of transport used in weak transport and conditional
simulation
Villani, 2009Santambrogio, 2015Backhoff Veraguas et al., 2019Oliver, 2014Barboni et al., 2024.
The recent literature uses this same fiberwise constraint in several
complementary directions. Peszek and Poyato study heterogeneous gradient flows in
the topology of fibered optimal transport, emphasizing fixed-fiber transport and
PDEs with heterogeneities Peszek & Poyato, 2023.
Hosseini, Hsu and Taghvaei develop conditional optimal transport on function
spaces through triangular maps and Kantorovich relaxations, motivated by
amortized Bayesian inference Hosseini et al., 2025.
Chemseddine, Hagemann, Steidl and Wald introduce conditional Wasserstein
distances for Bayesian inverse problems and OT flow matching, with restricted
couplings that compare posterior laws condition by condition
Chemseddine et al., 2025. Kerrigan,
Migliorini and Smyth give a dynamic conditional OT formulation and use it to
build simulation-free conditional flows
Kerrigan et al., 2024. The definition below
isolates the common geometric core: transport is ordinary within each fiber and
forbidden across distinct conditions.
The equality in (158) is not a formal exchange of an
infimum and an integral. The stated hypotheses make the fiberwise value
measurable and permit measurable selection of optimal plans, or measurable
near-optimal selection when minimizers are unavailable. Equivalently,
conditional transport is
ordinary transport on S×Ω with an infinite cost for moving mass
between different values of s.
Thus Lcλ is the general conditional Kantorovich value, whereas
Wp,λ is its metric specialization to
the constant family cs=cp=dp, after taking the pth root.
Equivalently,
the two definitions use exactly the same conditional coupling problem.
Proof
Non-negativity and symmetry follow from the corresponding properties of
Wp on each fiber. If Wp,λ(α,β)=0, then
Wp(αs,βs)=0 for λ-a.e. s, hence
αs=βs for λ-a.e. s and the disintegrated measures
α and β coincide. For the triangle inequality, let
γ∈Pp,λ(S×Ω). Since
Wp(αs,γs)≤Wp(αs,βs)+Wp(βs,γs)
for a.e. s, Minkowski’s inequality in Lp(S,λ) gives
For completeness and separability, identify each measure with the
λ-a.e. equivalence class of the measurable map
s↦αs∈Pp(Ω). The conditional distance is exactly
the metric of Lp(S,λ;Pp(Ω)). Since
(Pp(Ω),Wp) is Polish, so is this metric-valued Lp
space.
Proof
For 0≤r≤t≤1, the fiberwise geodesic property gives
Wp(αr,s,αt,s)=(t−r)Wp(α0,s,α1,s)for λ-a.e. s.
Hence the conditional curve has constant speed and realizes the distance
between its endpoints. In Euclidean space one may take, for each s, an
optimal plan πs∈Π(α0,s,α1,s) and set
αt,s=((1−t)p1+tp2)♯πs, where
p1,p2 are the two coordinate projections. On a general
geodesic space, the same construction uses a measurable family of optimal
dynamical plans; when geodesics are non-unique, different measurable selections
can produce different conditional geodesics.
Liero, M., Mielke, A., & Savaré, G. (2018). Optimal entropy-transport problems and a new Hellinger–Kantorovich distance between positive measures. Inventiones Mathematicae, 211(3), 969–1117.
Chizat, L., Schmitzer, B., Peyré, G., & Vialard, F.-X. (2018). An interpolating distance between optimal transport and Fisher–Rao metrics. Foundations of Computational Mathematics, 18(1), 1–44.
Caffarelli, L. A., & McCann, R. J. (2010). Free boundaries in optimal transport and Monge-Ampère obstacle problems. Annals of Mathematics, 171(2), 673–730.
Figalli, A. (2010). The optimal partial transport problem. Archive for Rational Mechanics and Analysis, 195(2), 533–560.
Chapel, L., Alaya, M. Z., & Gasso, G. (2020). Partial Optimal Transport with Applications on Positive-Unlabeled Learning. arXiv Preprint arXiv:2002.08276.
Lübeck, F., Bunne, C., Gut, G., Sarabia del Castillo, J., Pelkmans, L., & Alvarez-Melis, D. (2022). Neural Unbalanced Optimal Transport via Cycle-Consistent Semi-Couplings. arXiv Preprint arXiv:2209.15621. https://arxiv.org/abs/2209.15621
Klein, D., Uscidda, T., Theis, F., & Cuturi, M. (2024). GENOT: Entropic (Gromov) Wasserstein Flow Matching with Applications to Single-Cell Genomics. Advances in Neural Information Processing Systems, 37. 10.52202/079017-3301
Rabin, J., Peyré, G., Delon, J., & Bernot, M. (2011). Wasserstein barycenter and its application to texture mixing. International Conference on Scale Space and Variational Methods in Computer Vision, 435–446.
Nadjahi, K., Durmus, A., Simsekli, U., & Badeau, R. (2019). Asymptotic Guarantees for Learning Generative Models with the Sliced-Wasserstein Distance. Advances in Neural Information Processing Systems.
Cramér, H., & Wold, H. (1936). Some Theorems on Distribution Functions. Journal of the London Mathematical Society, s1-11(4), 290–294. 10.1112/jlms/s1-11.4.290
Carlier, G., Figalli, A., Mérigot, Q., & Wang, Y. (2025). Sharp Comparisons between Sliced and Standard 1-Wasserstein Distances. arXiv Preprint arXiv:2510.16465. 10.48550/arXiv.2510.16465
Park, S., & Slepčev, D. (2025). Geometry and Analytic Properties of the Sliced Wasserstein Space. Journal of Functional Analysis, 289(7), 110975. 10.1016/j.jfa.2025.110975
Deshpande, I., Hu, Y.-T., Sun, R., Pyrros, A., Siddiqui, N., Koyejo, S., Zhao, Z., Forsyth, D. A., & Schwing, A. G. (2019). Max-Sliced Wasserstein Distance and Its Use for GANs. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10648–10656.