Generalized OT Problems
This chapter changes the optimization problem rather than only the ground distance. Barycenters average several measures, multi-marginal OT couples many measures at once, low-rank and capacity constraints restrict the admissible plans, inverse OT learns the cost from observed transport, and weak or martingale OT acts on conditional laws. These models remain close to Kantorovich optimization, but the unknown can now be a family of couplings, a factored plan, a learned cost, or a coupling subject to nonlinear conditional constraints.
OT Barycenters¶
Barycenters ask how to average probability measures rather than points. This section explains the variational definition, the special closed forms in one dimension and for Gaussians, and the entropic algorithms used in practice.
Frechet Means¶
The natural formulation is a Frechet-mean problem on the space of probability measures: the unknown is the barycenter measure itself, and its support is not prescribed. It uses the continuous Kantorovich value defined in (40).
Unlike a coupling, the barycenter is a new probability measure on . Since the weights are nonnegative, problem (1) is convex in : Proposition Proposition: Convexity in the Marginals and Concavity in the Cost shows that the continuous Kantorovich value is jointly convex in its two marginals. Agueh and Carlier introduced this problem, following earlier ideas of Carlier and Ekeland Agueh & Carlier, 2011Carlier & Ekeland, 2010. For the quadratic cost on , a barycenter exists under the finite-second- moment assumption. It is unique if at least one positive-weight input is absolutely continuous; more general criteria ensure uniqueness through an essentially unique multi-marginal barycentric map. Discrete existence, consistency, and fixed-point constructions are studied in Anderes et al., 2016Esteban et al., 2016Le Gouic & Loubes, 2016.
Fixed-support discrete barycenters¶
For computation, one often turns the preceding infinite-dimensional problem into a finite one by prescribing possible barycenter locations. Assume the inputs are discrete,
Choose candidate barycenter sites and restrict the unknown to . For each input , the cost then becomes a finite Kantorovich problem with cost matrix
Thus its value is , in the notation of the discrete Kantorovich problem (9).
This construction is a finite-dimensional restriction, not an exact discrete reduction of the general barycenter problem. In the ordinary two-marginal Kantorovich problem, once both marginals are discrete, the two supports are known and the whole problem is exactly the matrix optimization (9) on their product support. For barycenters, the input supports do not determine the support of the unknown barycenter: a minimizer may place mass outside the chosen sites and outside the union of the input supports. Once the candidate support is fixed, however, the nonnegative weights and Proposition Proposition: Joint Convexity of Discrete OT show that problem (4) is convex in : the discrete Kantorovich value is jointly convex in its two histograms.
For quadratic costs, the multi-marginal formulation of Section Multimarginal OT shows that, for discrete inputs, one may choose a barycenter supported on weighted averages of one support point from each input. This exact candidate set can contain points, but Corollary Corollary: Sparse Discrete Barycenters shows that there exists a barycenter for which at most of them carry positive mass. Prescribing the support before solving (4) is nevertheless a numerical approximation, because the active weighted averages are not known in advance.
Figure Div moves beyond this degenerate case and compares barycenter grids obtained from one-dimensional quantile averaging and two-dimensional entropic transport under the same bilinear corner weights.

Wasserstein barycenter grids for four corner measures. The left panel uses the one-dimensional formula for one Gaussian law and three asymmetric two-Gaussian mixtures, and displays densities reconstructed from the averaged quantiles. The right panel computes entropic Wasserstein barycenters on a common pixel grid for the cat, two-disk, cross and clover silhouettes, using the normalized squared ground cost, and a Sinkhorn tolerance of . The barycenters are rendered as density images with values clamped at their quantile rather than by threshold contours. Colors interpolate between the four corners and encode the same bilinear weights in both panels.
The interactive demo below keeps the exact one-dimensional formula visible: the two coordinates set bilinear weights on the four corner laws, the middle panel averages their quantile functions, and the right panel reconstructs the resulting barycenter density.
Interactive panel. Use the barycentric coordinate controls to move through the four input laws and compare quantile and entropic barycenter constructions.
One-Dimensional Case¶
On the line, barycenters become linear after the quantile change of variables. This gives the rare case where the barycenter is explicit rather than the solution of a high-dimensional optimization problem.
Proof
The one-dimensional formula for gives
The minimization decouples pointwise in . For each fixed , the minimizer of is the weighted average . This function is nondecreasing because it is a positive weighted sum of nondecreasing quantile functions, hence it is a valid quantile function.
Gaussian Case¶
Gaussian barycenters show that the same separation as in the Gaussian Wasserstein formula persists: means average linearly, while covariances average according to the Bures--Wasserstein geometry.
Proof
Let denote the Gaussian measure with the same mean and covariance as . For every competitor and every Gaussian input , the Gelbrich contraction of Theorem Theorem: Gelbrich theorem gives
Summing with weights shows that moment-matched Gaussian projection cannot increase the barycenter objective. Since a barycenter exists, projecting any minimizer produces a Gaussian barycenter. The input with positive-definite covariance is absolutely continuous, so the uniqueness criterion following Definition Definition: Optimal-Transport Barycenter implies that the barycenter itself is this Gaussian measure.
For a Gaussian candidate, the Gaussian Wasserstein formula separates the objective as
The first term is uniquely minimized at . The second is the Bures barycenter problem. Uniqueness of the Wasserstein barycenter makes its covariance minimizer unique, and the presence of a positive-definite input makes this minimizer positive definite Esteban et al., 2016Bhatia et al., 2019. At such a minimizer, set
The differential of in a symmetric direction is . Hence first-order optimality is . Multiplying on the left and right by gives the covariance equation. In dimension one, , whose minimizer is .
If all input covariances are singular, the same contraction argument still gives a Gaussian barycenter, but the uniqueness step can fail and non-Gaussian barycenters may coexist. Thus nondegeneracy is essential when asserting that every barycenter is Gaussian.
Figure Div illustrates the nonlinear covariance interpolation characterized above; increasing anisotropy makes the simultaneous rotation and rescaling of the Bures--Wasserstein barycenter especially visible.

Bures--Wasserstein barycenters of centered Gaussian covariance matrices. Each panel shows a grid of barycenter ellipses for four corner covariances, without separate input panels: the corner ellipses are the four input covariances themselves. The right grid uses more anisotropic inputs, making the nonlinear rotation and scaling of covariance barycenters more visible.
The interactive Gaussian demo compares the Bures covariance barycenter with a plain Euclidean covariance average under the same weights. The difference is most visible for rotated, anisotropic covariances: the Euclidean average blends matrix entries, whereas the Bures barycenter follows the geometry induced by quadratic Gaussian transport.
Interactive panel. Use the corner-covariance and interpolation controls to see how Gaussian barycenter ellipses interpolate covariance geometry.
Sliced and Radon Barycenters¶
Slicing gives a scalable surrogate for high-dimensional barycenters by applying the one-dimensional quantile formula in every projection direction. For measures on , one replaces by the sliced distance introduced in Definition Definition: Sliced Wasserstein Distance and interpreted through the Radon transform in Section Sliced Wasserstein Distances:
The constraint that all projected measures come from the same is the nontrivial part. A cheaper Radon-domain approximation drops this consistency constraint and minimizes directly over one-dimensional projected laws :
For each , this is a one-dimensional barycenter, hence its quantile is the weighted average of the projected quantiles. For two inputs and , define
Thus is the directionwise quantile field, and when has a density we denote it by . The relaxed value is a lower bound on the sliced-barycenter value. If the minimizing family is Radon-consistent, meaning that for a common probability measure and almost every , then is an exact sliced barycenter. In general, independently computed one-dimensional barycenters do not satisfy the range conditions of the Radon transform. One therefore reconstructs a density in a least-squares sense, usually through a regularized Radon pseudoinverse.
Let denote a density of . We use the one-dimensional Fourier transform in given by
whenever Fourier inversion is valid.
Proof
Use the compatible -dimensional Fourier convention
The Fourier-slice theorem gives . Plancherel’s identity therefore turns the least-squares objective, up to the positive factor , into
Every has the two signed-polar representations and . Pointwise least squares consequently gives
Inverse -dimensional Fourier transformation and signed polar coordinates give (27); the factor accounts for the normalization of and the two signed representations. If , the Fourier-slice theorem makes both terms in the last display equal to , proving exact recovery.
Formula (27) is the filtered back-projection representation of the Radon pseudoinverse used in tomography Herman, 1980; is its ramp multiplier. Since this multiplier amplifies high frequencies, one typically chooses a bandwidth and an even low-pass window with , and replaces the ramp by
The numerical reconstruction below uses the super-Gaussian window . Choose so that the positive part below has nonzero mass, and define the nonnegative, unit-mass reconstruction
For the endpoints, set when , . In the figure, the small threshold only suppresses finite-angle inversion ghosts. The resulting regularized density is generally only a least-squares approximation to the independently averaged slices. This fast construction was introduced for sliced and Radon Wasserstein barycenters in Bonneel et al., 2015, but it is not the exact constrained sliced barycenter. With all directions, the Radon transform is injective by the Cramér--Wold theorem Cramér & Wold, 1936; inconsistency comes from failure of Radon range conditions such as antipodal symmetry and moment consistency; with finitely many directions, the sampled Radon operator is also non-injective.
Figure Div follows the resulting density, projected-density and quantile fields through a cat-to-heart interpolation.
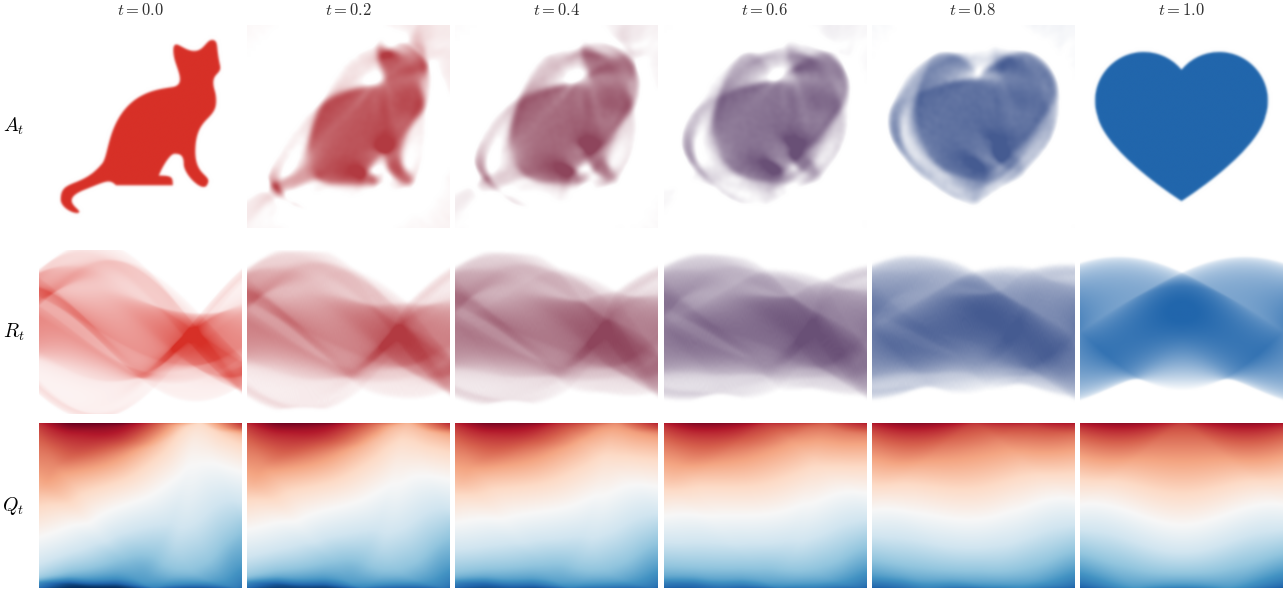
Radon-domain sliced barycentric interpolation between the cat and heart densities. The columns correspond to . The first row shows the endpoint densities and the intermediate reconstructions defined in (32) from the windowed pseudoinverse (31). The second row shows the projected-density fields (labeled in the figure), obtained by converting the directionwise quantile barycenters back into one-dimensional densities. The third row shows the quantile fields defined in (23).
Interactive panel. Move the interpolation time and projection angle to compare image-space densities, Radon profiles, and quantile interpolation in the sliced barycenter construction.
Sinkhorn for Barycenters¶
A key difference with the regularized two-marginal OT problem is that there is no canonical reference measure , because the barycenter is unknown. To reduce complexity, one usually fixes a candidate support for the barycenter and solves the discrete problem (4); this introduces a discretization error but keeps the number of unknowns manageable.
One can then use the entropy-only convention of (2) and approximate (4) by
for some . This is a smooth convex minimization problem, which can be tackled using gradient descent Cuturi & Doucet, 2014. An alternative is to use a descent method, typically quasi-Newton, on the semi-dual Cuturi & Peyré, 2016; this is useful when adding extra regularization on the barycenter, for instance to impose smoothness.
A simple but effective approach developed in Benamou et al., 2015 observes that (33) has the same minimizers as the weighted KL projection problem
subject to
Here . The barycenter is implicitly encoded in the common row marginal
The two objectives differ only by constants depending on , not on the couplings or barycenter. Assume below that every is finite and every is positive; zero-weight target atoms can be deleted before the iteration. The optimal couplings then have scaling form
and the generalized Sinkhorn iterations are
The geometric mean enforces the fact that all couplings share the same barycenter marginal.
The scaling cycle has an exact dual-optimization interpretation; it is not merely a sequence of marginal normalizations. Write and , with all operations understood componentwise. The proposition below shows that these potentials maximize the concave dual (41). With fixed, the objective separates over , and its exact maximizer in each is
which is precisely the -update. Conversely, with fixed, exact maximization over the coupled block under gives
Thus a complete generalized Sinkhorn cycle is exact two-block coordinate ascent on the dual, or equivalently alternating minimization of its negative. Indeed, the constraint follows from , while the first-order conditions require for every . In the primal formulation (34), the same cycle alternates weighted KL projections onto the target-column constraints and the common-row-marginal constraint Benamou et al., 2015.
Proof
Introduce Lagrange multipliers in (34):
The explicit constraint may be dropped here: nonnegativity of the couplings, together with and , already forces . We may therefore minimize the Lagrangian over . Strong duality allows one to exchange the minimum and maximum. Finiteness of the minimum with respect to gives the vector constraint , while minimizing with respect to gives the Legendre transform of :
The separable conjugate is
because for ,
Substituting this conjugate gives the displayed dual, including its additive constant. Coordinate maximization in gives the update; block maximization in all under gives the weighted geometric mean and then the update.
Classical applications include two-dimensional image interpolation, three-dimensional shape interpolation, and barycenters on surfaces where the ground cost is the square of the geodesic distance Solomon et al., 2015.
Wasserstein-Over-Wasserstein and Barycenters¶
The barycenter formula does not require a finite list of inputs. The Wasserstein-over-Wasserstein viewpoint of Section Wasserstein Over Wasserstein allows one to replace the discrete family by a law over probability measures. Such population Wasserstein barycenters were studied for random probability measures by Bigot and Klein, in general geodesic settings by Le Gouic and Loubes, and on Riemannian manifolds by Kim and Pass Bigot & Klein, 2018Le Gouic & Loubes, 2016Kim & Pass, 2017. Assume, for instance, that is lower semicontinuous and that there exists at least one with
together with the usual compactness or coercivity hypotheses ensuring existence of minimizers. For instance, these assumptions are automatic when is compact and is continuous. The barycenter correspondence is then
When this set is a singleton, we denote its element by
which defines a nonlinear flattening map from laws over measures back to measures on . When , this is exactly the finite barycenter problem above. This map should be contrasted with the linear collapsed, or barycentric, mixture of Definition Definition: Collapsed, Or Barycentric, Mixture, which simply averages the input measures themselves. The two operations agree in degenerate linear situations, but in general is a geometric average in transport space, whereas is an ordinary mixture in the ambient linear space of measures.
The next result records the corresponding law of large numbers. It is useful when a dataset is itself made of probability measures, for instance populations of histograms, posterior distributions or shapes. We state it in the compact setting, where no moment or tightness side conditions are needed; non-compact extensions require the usual integrability assumptions. Consistency of Wasserstein barycenters and related statistical constructions is developed in Boissard et al., 2015Le Gouic & Loubes, 2016Zemel & Panaretos, 2019; streaming and large-scale uses of many input measures appear for instance in Staib et al., 2017Srivastava et al., 2015Srivastava et al., 2018.
Proof
Set . Since is compact metric, is compact metric for weak convergence, and so is . The space is separable for the uniform norm. Applying the scalar strong law to a countable dense family of test functions and then using uniform approximation gives, almost surely, for every ,
This is exactly (50).
For the collapsed mixtures, take and define . This function is continuous on . Hence
which proves (51).
It remains to prove the nonlinear barycenter consistency. The map is continuous on . Therefore the map , where , is continuous from the compact space to . Its image
is compact in . The convergence of to is uniform over : given , cover by finitely many -balls in , use weak convergence for the centers, and bound the error on the balls by the total variation of . Hence the empirical objectives
converge uniformly on to
Let . Compactness gives a subsequence . Uniform convergence, continuity of , and optimality of give, for any ,
so . If this set is the singleton , every converging subsequence has the same limit, and therefore the whole sequence converges to , proving (52).
Thus, (50) is the classical law of large numbers on Wasserstein space, and (51) is its linear image under the collapse map. By contrast, (52) is nonlinear: it recomputes a Wasserstein barycenter from the empirical law over measures. The number of input measures should not be confused with the number of samples used to approximate each input measure, studied in Section Sample Complexity. In applications one often observes empirical measures, each made of roughly atoms, hence about points in total. Balancing the error due to finitely many input laws against the error due to finitely sampled input laws is a separate statistical and computational tradeoff.
Toward Central Limit Theorems on Wasserstein Space¶
The same hierarchy suggests a central-limit refinement of the preceding law of large numbers, but the nonlinear geometry makes this substantially more delicate. For the linear collapse , testing against a fixed reduces the question to the classical scalar central limit theorem for the random variable . For the nonlinear barycenter , however, there is no canonical vector difference inside . One has to choose a local linearization. When the population barycenter is sufficiently regular so that the optimal map from to exists, this amounts to asking whether converges in a Hilbert space such as . In nonsmooth settings one must instead work with optimal-plan or logarithmic-map coordinates. Even after such a linearization, an infinite-dimensional CLT requires tightness of the rescaled tangent variables and a genuine Radon Gaussian random element; in a Hilbert space, the associated covariance must be trace class. A cylindrical Gaussian limit alone is therefore not a probability law on the tangent space. This obstruction explains why Wasserstein-space CLTs are more rigid than the weak laws above.
There are nevertheless important settings where such results can be proved. In one dimension, the quantile representation linearizes , so barycenter fluctuations can be studied through empirical averages of quantile functions. Another finite-dimensional case is the family of non-degenerate Gaussian measures in fixed dimension, where reduces to the Bures geometry of means and covariance matrices. Agueh and Carlier Agueh & Carlier, 2017 formulate this Wasserstein-barycenter CLT precisely in tangent coordinates and prove it in a few special cases, including the one-dimensional non-atomic setting and finite laws supported on non-degenerate Gaussian measures. Entropic barycenters give a smoother variant for which central-limit theorems for empirical barycenters are also available Carlier et al., 2021. These results should be read as nonlinear analogues of the statistical limits discussed in Chapter Paragraph, not as a generic Hilbert-space CLT valid on all of .
Multimarginal OT¶
Multi-marginal OT couples more than two measures at once. It is the natural language for barycenters, matching with teams and several-body costs, but its tensor dimension is the main computational obstacle.
Definition and Basic Structure¶
The multi-marginal formulation replaces a coupling between two measures by a joint distribution with several prescribed marginals. Given measures on spaces and a lower-semicontinuous cost bounded from below, the problem reads
where is the set of probability measures whose -th marginal is . This is still a linear program in the discrete setting, but its ambient tensor has size .
Monge Structure and Splitting-Set Twist¶
As in the two-marginal case, one would like to know when the optimal joint law is induced by deterministic maps from one marginal. The relevant non-degeneracy assumption is stronger than pairwise twist, because the other variables have to be recovered simultaneously. The condition below is the standard multi-marginal analogue used in the Monge-structure theory of Gangbo--Swiech and Pass Gangbo & Swiech, 1998Pass, 2011Pass, 2012Pass, 2015.
Proof
Let be optimal dual potentials. Complementary slackness gives a Borel contact set of full -measure on which . After disintegrating with respect to the first marginal, fix a point where is differentiable and where the conditional plan is concentrated on the fiber
For this fixed , the fiber is a splitting set: indeed, the constant can be absorbed into one of the functions , . Equivalently, set and for . Dual feasibility gives , with equality on . If , the function
touches from above at . Differentiating at this contact point gives
All points in the fiber therefore have the same value of . Twist on splitting sets makes the fiber a singleton for -a.e. . Disintegrating with respect to its first marginal gives Dirac conditional measures, hence measurable maps . If and are two optimal plans, their average is also optimal. The conditional measure of this average over is the average of the two Dirac conditionals, and it must again be a Dirac mass by the preceding argument. Hence the two Dirac masses coincide for -a.e. , proving uniqueness.
Coulomb Cost and Density-Functional Theory¶
A second canonical example, besides barycenters, comes from electronic structure. For electrons in , the repulsive Coulomb interaction is the multi-body cost
with the value on the collision set. Proposition Proposition: Multi-Marginal Monge Structure therefore does not apply verbatim: the Coulomb cost is neither finite nor differentiable on the whole product space. Any finite-energy plan gives zero mass to exact collisions, so the cost is smooth at almost every point charged by the plan, but this removes only the singularity; one must still establish differentiability of the dual potential and twist on the relevant splitting sets. Away from collisions,
For , the map from to this vector is injective, so the ordinary two-marginal twist argument can be recovered under the required existence, duality and differentiability hypotheses. For , however, the displayed total force does not by itself determine the entire tuple ; twist on splitting sets, and hence a Monge representation, is not automatic. The previous proposition thus supplies a mechanism to verify in special Coulomb models, not a general existence theorem for co-motion maps.
If is an electron density with and is the associated probability density, the strictly-correlated-electrons relaxation of density-functional theory is the equal-marginal problem
Since the cost and constraints are permutation invariant, symmetrizing any admissible plan does not change its value, so one may equivalently minimize over symmetric plans. This functional gives the smallest possible electron--electron repulsion compatible with the prescribed one-particle density; it appears as the strong-interaction limit in density-functional theory and was connected to optimal transport in Gori-Giorgi et al., 2009Buttazzo et al., 2012Cotar et al., 2013Di Marino et al., 2015. The deterministic ansatz writes a plan through co-motion maps
so that the position of one electron determines the positions of the others. The following cyclic version is the most common structural form of this ansatz in the strictly-correlated-electrons literature.
Proof
Since , all iterates preserve , so every marginal of is . The plan is an average of coordinate permutations of , hence has the same marginals and is invariant under coordinate permutations. The Coulomb cost is symmetric in its arguments, so its integral is unchanged by each . The last identity follows by evaluating on the graph .
The Monge-structure proposition above explains the general mechanism that can force graph solutions, while the cyclic co-motion proposition records the additional equal-marginal symmetry used by co-motion maps. For the Coulomb cost, however, the singular repulsion and permutation symmetry make the structure delicate: co-motion maps are optimal in special geometries, but they are not universally optimal, and counterexamples are known Colombo & Stra, 2015Bindini et al., 2020. Thus the DFT problem is both a central application and a warning that multi-marginal OT is richer than a naive deterministic matching problem.
Figure Div shows the same phenomenon in a deliberately small one-dimensional model.
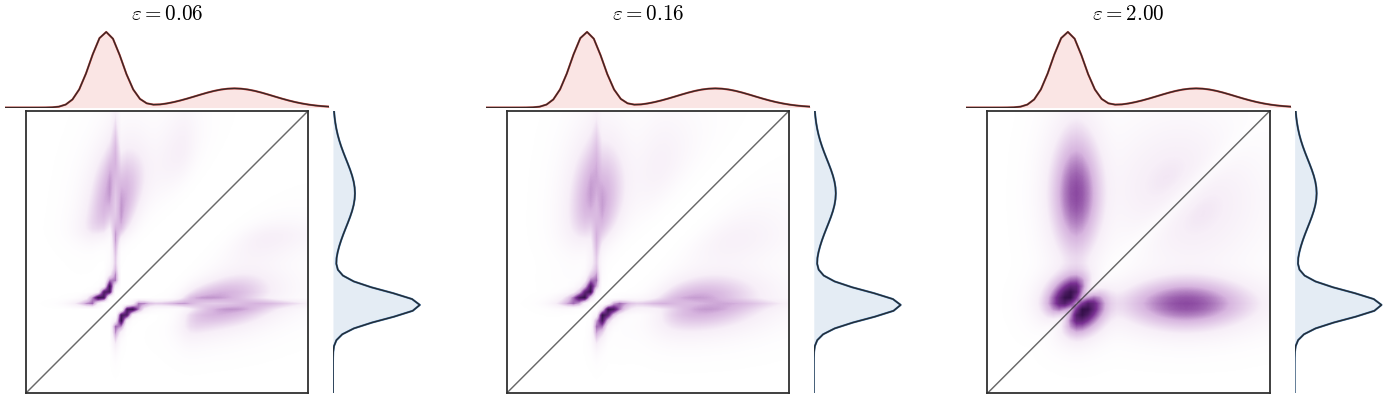
Entropic three-marginal Coulomb transport in one dimension. The three marginals are equal and the pairwise cost is a softened Coulomb repulsion. Each panel shows the marginal of the tensor Sinkhorn solution: small regularization pushes mass away from the collision diagonal, while larger regularization blurs the repulsive structure toward the independent reference.
Interactive panel. Adjust the entropic temperature and repulsion strength to see the pairwise marginals of a three-marginal Coulomb plan move away from the diagonals.
Multi-Marginal Formulation of Barycenters¶
Wasserstein barycenters are the central example. For the squared Euclidean cost, one can introduce a latent barycenter point and eliminate it explicitly, leading to the multi-marginal cost
Proof
For any candidate barycenter and couplings , glue the couplings along their common marginal to obtain a joint law of . Conditioning on and minimizing over gives
Taking the infimum over the couplings gives that the barycenter value is at least the multi-marginal value. Conversely, from an optimal multi-marginal plan , set . The couplings between and each are feasible for the barycenter problem and attain exactly the multi-marginal cost.
If is any barycenter, choose optimal couplings between and each and glue them along the common marginal. Since the barycenter and multi-marginal values are equal, the conditional minimization inequality above must be an equality. Thus almost surely for the induced optimal multi-marginal plan.
Proof
Write a discrete multi-marginal plan as a nonnegative tensor and let collect its marginals:
After vectorizing , Proposition Proposition: Rank-Controlled Sparse Minimizers applies to the multi-marginal linear program. Its constraint operator has rank
Indeed, a family belongs to the annihilator of its image precisely when
Varying one index at a time shows that every is constant, say , and the remaining condition is . The annihilator therefore has dimension , proving the rank formula.
Consequently, one may choose an optimal multi-marginal tensor with at most positive entries. Proposition Proposition: Multi-Marginal Formula for Quadratic Barycenters gives . Each positive tensor entry produces at most one atom under , and collisions can only reduce the support size.
This linear support bound, rather than the cardinality of the full product grid, is the standard sparsity estimate for discrete Wasserstein barycenters Anderes et al., 2016.
Entropic Regularization of Multi-Marginal OT¶
As in the two-marginal case, adding an entropic penalty with respect to the product measure leads to scaling algorithms:
The optimizer has the generalized Gibbs form
and generalized Sinkhorn iterations alternately update one potential so that the -th marginal is correct. This formula is direct but, without additional structure, it is mostly a conceptual baseline. In the discrete case, even storing the Gibbs tensor or the coupling requires entries, and the unstructured multi-marginal Sinkhorn complexity inherits this exponential dependence on the number of marginals Lin et al., 2019.
Treewidth and Graphical Structure¶
The important exception is when the cost factors over a sparse interaction graph. Let be a finite undirected graph with and suppose, for simplicity, that
The relevant complexity parameter is not merely the number of edges, but the largest intermediate interaction created when variables are summed out.
The last condition is the running-intersection property. A tree decomposition equipped with factors assigned to its bags is also called a junction tree. Equivalently, choose an order in which to eliminate the vertices of . Just before eliminating a vertex, connect all of its remaining neighbors, thereby adding fill-in edges. The induced width of the order is the largest number of remaining neighbors encountered. Treewidth is the minimum induced width over all elimination orders, and the corresponding bags consist of each eliminated vertex together with those neighbors. This equivalent viewpoint explains why treewidth controls exact summation.
The same construction applies to higher-order factors indexed by subsets : form the primal interaction graph by connecting every pair of variables occurring in a common factor, then compute the treewidth of that graph.
Junction-Tree Contractions Inside Sinkhorn¶
The treewidth reduction replaces each full tensor contraction in Sinkhorn by exact sum-product messages. In the discrete setting, define the edge Gibbs matrices and current unary factors
Under (86), the current scaled coupling is represented implicitly as
When is a tree, let denote the neighbors of . The directed sum-product messages satisfy
Cutting the edge separates the tree into two components: is the total contribution of the component containing , conditional on the boundary state . Conditioning first on gives the message recursion. A leaf-to-root pass followed by a root-to-leaf pass computes every directed message and hence every current marginal,
For the block currently selected by cyclic scaling, the exact coordinate update is
with componentwise products and quotients. This changes only the unary factor . Updating all blocks at once would instead define a Jacobi scheme. Thus the expensive denominator of one generalized Sinkhorn block update is evaluated by messages rather than by enumerating all multi-indices.
For a general tree decomposition, choose one host bag for each unary factor, assign each edge factor in (88) to a bag containing both endpoints, and denote the product assigned to bag by . For adjacent bags , set . Junction-tree messages take the form
After a collect-distribute pass, the calibrated bag belief is
For any , summing over gives ; the running-intersection property ensures that every bag containing gives the same result.
Redundant adjacent bags may be contracted, so one can assume that the decomposition is reduced. If its width is , every bag contains at most variables and every separator contains at most . Consequently, if , one collect-distribute inference pass for fixed scalings costs
More precisely, the time is bounded by
and the stored messages occupy
beyond the original factors and scaling vectors. The message-memory bound assumes streamed bag contractions; materializing every dense belief (93) instead requires working memory.
These are fixed-scaling inference bounds, not the cost of an entire Sinkhorn solve. They also yield a sharper block implementation. Assign each constrained marginal to a host bag . After updating , only the messages along the unique path from to the host bag of the next updated marginal must be refreshed. A path of length costs , hence at most per block update. This is the junction-tree iterative-scaling mechanism analyzed in Haasler et al., 2020Fan et al., 2021. For a tree interaction graph, direct edge messages give for a full pass, or with equal support sizes. A cycle admits full junction-tree passes, while the complete graph still costs in time.
The structured implementation never forms or as full tensors. It stores the original local factors and separator messages, evaluates bag products on the fly, and replaces the explicit contraction in Algorithm: Multi-marginal Sinkhorn by (90) or (92), and returns the coupling through its factors and scalings. Materializing every entry of would itself require operations, so the saving applies when only marginals, costs, samples, or other low-order statistics are needed. For small , the same recursions are evaluated in the log domain with log-sum-exp operations. This connects entropic multi-marginal OT with exact inference in probabilistic graphical models and Schrodinger bridge computations Haasler et al., 2021Haasler et al., 2020Fan et al., 2021Altschuler & Boix-Adsera, 2023.
A representative fluid-mechanics example is the time discretization of Brenier’s generalized incompressible Euler problem: kinetic action couples neighboring time slices and periodic incompressibility closes the chain into a cycle, hence a graph of treewidth two. Entropic Bregman/Sinkhorn schemes exploit this circular structure through low-order contractions Benamou et al., 2015Benamou et al., 2019.
Practical barycenter solvers therefore exploit separability of the cost, low-rank structure, convolutional kernels, or a fixed barycenter support.
Low-Rank Optimal Transport¶
Low-rank OT reduces the size of a transport plan by forcing the coupling itself to pass through a small latent measure. This is useful when the mass exchange is expected to be organized by a few hidden clusters or prototypes, and it is distinct from approximating the Sinkhorn kernel by a low-rank matrix. The idea was introduced statistically through factored couplings by Forrow, Hütter, Nitzan, Rigollet, Schiebinger and Weed Forrow et al., 2019, and developed algorithmically for arbitrary costs by Scetbon, Cuturi and Peyré Scetbon et al., 2021.
The latent interpretation is immediate. The vector is the law of an intermediate variable ; is a coupling of the source index with ; is a coupling of the target index with the same . Formula (99) is the law of obtained by sampling , then sampling and conditionally independently given . Equivalently, OT is replaced by a succession of two transports through an abstract intermediate measure on an -point space. The locations only label the latent atoms and do not enter the original cost.
Proof
The marginal constraints follow by direct summation:
and similarly . Since is a sum of nonnegative rank-one matrices , its nonnegative rank is at most .
Conversely, suppose with and . Set and . Components with do not contribute and can be removed. Define , and . Since has total mass one, . Moreover , , and both column marginals are equal to . Finally,
For a cost matrix , the low-rank constrained OT value is
The minimization is over triples satisfying Definition Definition: Low-Rank Factored Couplings.
This problem is non-convex. Scetbon, Cuturi and Peyré regularize the joint variables by the sum of their entropies and optimize them by constrained mirror descent Scetbon et al., 2021. To isolate the simpler block mechanism used in Figure Div, fix a positive latent law and optimize only the two sub-couplings:
For fixed , this differs only by constants from adding the negative entropies of and to the factorized transport cost. Each block subproblem is a strictly convex entropic OT problem with an effective cost, although the joint objective remains non-convex because of its bilinear -- term.
Each update exactly minimizes one factor block while keeping the other fixed, so the objective decreases monotonically. Positivity makes each block minimizer unique and keeps it in the relative interior of its transport polytope. Compactness and exact cyclic block-coordinate descent imply that every accumulation point is a coordinatewise minimizer, hence a stationary point of the constrained problem. The non-convexity does not guarantee a globally optimal rank- coupling.
Figure Div visualizes both the intermediate latent measure and the improvement of the factored coupling as the prescribed rank increases.
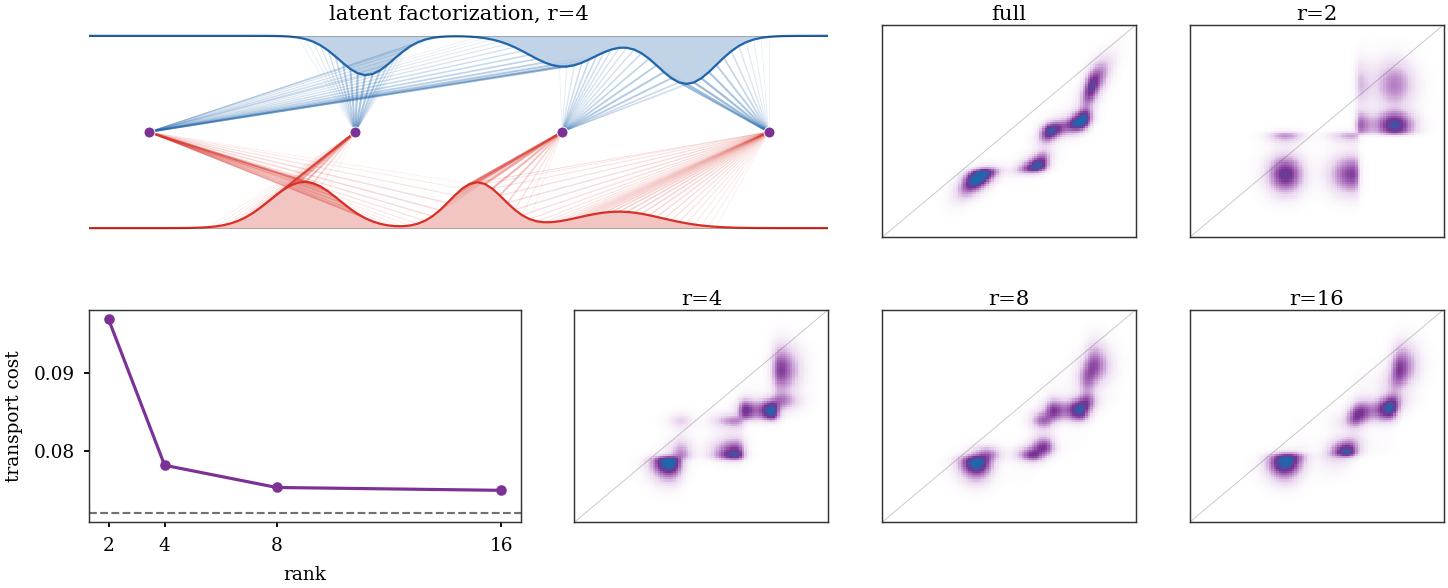
Low-rank entropic OT on a one-dimensional Gaussian-mixture example. The first view shows factorization through four latent atoms; the matrix panels compare the full entropic coupling with fixed-latent-mass low-rank couplings of increasing rank. This is deliberately not a favorable example for low rank: with a small entropic parameter, one-dimensional quadratic OT is close to a sparse Monge graph rather than to a genuinely low-rank matrix.
Interactive panel. Vary the latent rank and entropic scale to see the same one-dimensional problem as a two-stage transport through a small intermediate measure. The right matrix should approach the full entropic plan as the rank increases.
Capacity-Constrained Optimal Transport¶
Classical Kantorovich transport only fixes the marginals: if a pair is cheap, the optimizer may concentrate as much mass as the marginal constraints allow on this pair. Capacity-constrained OT adds a local congestion rule on the coupling itself. It is useful when edges, facilities or matchings have limited throughput, and it also gives a clean mathematical way to interpolate between a sparse OT plan and the independent product coupling. The systematic study of the continuous problem, including existence and the geometry of active saturated regions, was developed by Korman and McCann Korman & McCann, 2015.
Let , and let be a finite-valued measurable capacity. The capacity-constrained transport value is
The product coupling is feasible whenever . Thus the constraint is not meant to promote the product plan; rather, it prevents the optimizer from using any pair more than the prescribed density ratio. Separately, we adopt the convention : the symbol removes both the density bound and the absolute-continuity requirement, and hence recovers the full Kantorovich problem. At the opposite extreme, forces the independent coupling itself, because a density bounded by one and integrating to one must equal one almost everywhere. Values close to one therefore enforce diffuse plans close to this reference.
For discrete measures and , a capacity is an upper matrix . The density-ratio discretization of (104) is , and the finite-dimensional problem is the linear program
Feasibility is now a genuine issue: the upper matrix must contain enough mass in every row-column cut to support the prescribed marginals. The usual transport polytope is recovered when , while small capacities select a smaller capped transportation polytope. For index sets and , write , , and .
Proof
If is feasible, then
and proves necessity. Conversely, build a flow network with capacity from the source to row , capacity from row to column , and capacity from column to the sink. A cut containing row set and column set has capacity
The cut condition makes every such capacity at least one. The max-flow/min-cut theorem therefore gives a unit flow, whose row-to-column edge values form the required matrix .
Entropic smoothing gives a direct Sinkhorn-like algorithm. Assume the cut condition above. With , the regularized problem is
Equivalently, up to additive constants, the objective is . The problem is therefore the KL projection of onto the intersection of three convex sets: the row constraints, the column constraints and the box . Alternating KL projections with Dykstra correction factors Dykstra, 1985Bauschke & Lewis, 2000, in the same spirit as the Bregman projection formulation of Sinkhorn Benamou et al., 2015, gives a simple capacity-constrained scaling scheme.
On the active support, all iterates and correction factors are positive, so every division is defined. Finite-dimensional KL-Dykstra convergence shows that, whenever the capped polytope is nonempty, the iterates converge to the unique regularized minimizer. Deleting zero-capacity edges is essential: otherwise the correction step creates undefined products of zero and infinite factors.
Figure Div shows how lowering the entrywise cap progressively spreads a one-dimensional coupling while preserving both prescribed marginals.

Capacity-constrained entropic OT between two one-dimensional Gaussian-mixture histograms. The same source and target marginals are coupled with a density-ratio cap . Large capacity leaves a nearly Monge-like graph, whereas small capacity saturates many entries and forces the coupling to spread.
Interactive panel. Vary the density-ratio cap and the entropic regularization to see how the upper bound turns a graph-like one-dimensional coupling into a saturated spread-out plan.
For the empirical self-coupling in Div, the cap is chosen to prescribe a minimum number of outgoing connections per source point. With uniform weights , imposing is equivalent to the conditional bound . Since each row has total mass , this forces each source row to use at least target atoms, up to the small extra spreading introduced by entropic smoothing.
For the empirical self-coupling in Figure Div, the cap is chosen to prescribe a minimum number of outgoing connections per source point.
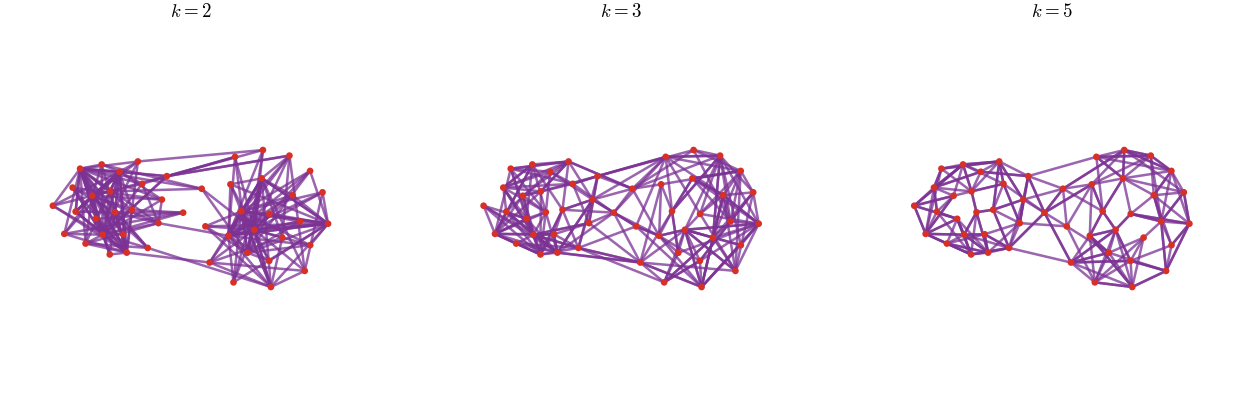
Capacity-constrained local self-couplings on a two-dimensional empirical Gaussian mixture. The source and target are the same semi-regular uniform empirical measure, but the diagonal is removed to avoid the trivial identity plan. The three panels use off-diagonal caps with , equivalently because . They therefore impose at least one, three and five outgoing connections per source atom.
Interactive panel. Change the admissible number of outgoing connections to see how the capacity bound turns a dense self-coupling into a local transport graph.
Metric Learning and Inverse OT¶
Metric learning differentiates a forward transport loss through a parameterized cost, whereas inverse OT starts from an observed plan and asks which cost makes it optimal. The first viewpoint is often bilevel; the second admits a direct convex formulation for affine cost families, provided the intrinsic cost invariances are removed.
Differentiating OT Losses¶
Inverse OT and metric learning repeatedly differentiate a forward OT value with respect to the input law and to the ground cost. The two resulting objects are precisely the two certificates of optimality: a Kantorovich potential for perturbations of the marginal and an optimal coupling for perturbations of the cost. The main caveat is non-uniqueness. In the unregularized case, the correct objects are one-sided directional derivatives, or equivalently subgradients in the measure variable and supergradients in the cost variable. Entropic regularization selects a unique plan and, for positive finite histograms, gives ordinary derivatives on the simplex interiors.
Proof
Kantorovich duality writes
This is a supremum of affine functions of , so Danskin’s theorem gives the one-sided directional derivative as the supremum over active maximizers, namely the optimal dual potentials. The condition makes the formula independent of the additive gauge .
For the cost variable,
is an infimum of affine functions of . Danskin’s theorem for a minimum gives the right directional derivative as the infimum of over the active minimizers. If the active dual potential or coupling is unique, the corresponding directional derivative is linear in the perturbation, which is the displayed first variation.
In the discrete case, this proposition says that any optimal dual vector is a subgradient with respect to the source weights , while any optimal plan is a supergradient with respect to the cost matrix , because the value is concave in :
Here denotes the superdifferential of the concave map . When the corresponding objects are unique, these inclusions become the gradients on the tangent space and . Without uniqueness, the exact directional derivative with respect to in a direction is the minimum of over all optimal plans.
Proof
The cost derivative follows directly from the primal envelope theorem, because the entropic optimizer is unique. For the measure derivative, use the continuous entropic dual formula from the Sinkhorn chapter. At an optimal pair, the soft-transform equations imply the row normalization
Differentiating the dual objective with respect to at fixed optimal potentials gives
The second term vanishes by the previous normalization identity, leaving . The gauge ambiguity of again disappears because .
For a finite-dimensional parametrization or , the entropic formula gives the backpropagation rule
where is the entropic optimizer. For the unregularized value , uniqueness of the optimal plan gives . Without uniqueness, the directional derivative in a parameter direction is obtained by minimizing over the optimal face, while any selected optimal plan gives a valid supergradient with respect to the cost. This is the calculus behind ground-metric learning, which was explicitly studied in Cuturi & Avis, 2014 and connects to the broader metric-learning literature Kulis, 2012Bellet et al., 2015. If one uses the entropy-only discrete convention of the Sinkhorn chapter instead of the KL-normalized value, then, for positive source weights,
so its derivative with respect to is represented on the simplex tangent space by , up to an irrelevant additive constant.
Figure Div gives the geometric counterpart of this differentiation rule: changing an anisotropic quadratic cost changes which transport segments are selected.
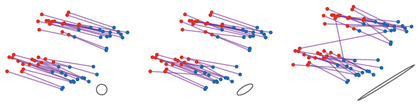
Changing the ground metric changes the optimal coupling. The same red and blue empirical measures are matched with for the Euclidean metric and two increasingly anisotropic Mahalanobis metrics. The small gray ellipse shows the unit ball of the metric: directions in which the ellipse is elongated are cheaper, and this deforms the transport segments selected by the OT plan.
The interactive demo lets the anisotropy and orientation of the Mahalanobis cost move. The transport plan is recomputed exactly for the displayed particles, so the segments show how the learned cost changes the matching.
Interactive panel. Use the metric and deformation controls to see how learning the ground cost changes the apparent transport geometry.
Inverse Optimal Transport¶
Inverse OT asks for a ground cost that explains observed matchings or flows as optimal transport plans. In its most direct form, one observes a plan with marginals and seeks a cost such that is optimal for
This is ill-posed without structure. Adding to a cost shifts every feasible objective by the same marginal-dependent constant, multiplying a cost by a positive scalar does not change its minimizers, and the zero cost rationalizes every feasible plan. An identifiable model must quotient or normalize these gauge and scale freedoms; a sparse observed plan can still be compatible with a nontrivial cone of normalized costs.
A useful statistical methodology is to measure the suboptimality of the observed plan through a Fenchel--Young loss. Write the score as and define the convex regularized prediction value
The Fenchel--Young loss
is nonnegative by Fenchel’s inequality and vanishes exactly when , i.e. when satisfies the regularized optimality conditions for . Entropic regularization is important here because it makes the forward map smoother and provides gradients with respect to , at the price of a statistical bias Andrade et al., 2025Peyré et al., 2026.
In the discrete unregularized case, this loss reduces to the optimality gap of the observed coupling. For and a cost matrix , denote it by
This inverse-OT gap loss is nonnegative and vanishes exactly when is optimal for .
In practice, one restricts the cost to a finite-dimensional model class, often affine:
where is convex and the matrices encode features, graph distances or a Mahalanobis parameterization. This viewpoint appears in low-rank and sparse inverse OT models Dupuy et al., 2019Andrade et al., 2024 and in convex formulations for learning OT costs from observed plans Ma et al., 2020Peyré et al., 2026.
A minimal finite-dimensional model is obtained by learning a bilinear cost on ,
For empirical measures and , this gives the cost matrix
so both maps and are linear. Inverse OT within this model asks which matrix makes an observed matching or coupling look optimal; learning the cost is thus reduced to estimating a linear parameter.
For a fixed matrix , the forward prediction is the optimal face
When this face is a singleton, write its element as ; otherwise denotes a deterministic tie-broken selection. Although is linear, the solution correspondence is polyhedral: changing changes the direction in which the transport polytope is probed, and a tie-broken selection is constant on normal-cone cells. The figure below illustrates this correspondence on the OT4ML point clouds. The construction follows the visual idea of the Python Optimal Transport logo Flamary et al., 2021: red source atoms, blue target atoms and straight segments show the selected optimal bijection. With and , the first two rank-one matrices are
These small transverse terms break the large ties of the pure horizontal or vertical scores while preserving a rank-one cost. The matrix gives the usual quadratic assignment, up to the marginal-only terms discussed below, while reverses the correlation and produces an anti- matching.
Figure Div illustrates this correspondence on the OT4ML point clouds.
Interactive panel. Change the bilinear cost matrix and solve the corresponding equal-weight assignment in the browser; each panel uses an actual Hungarian solve.
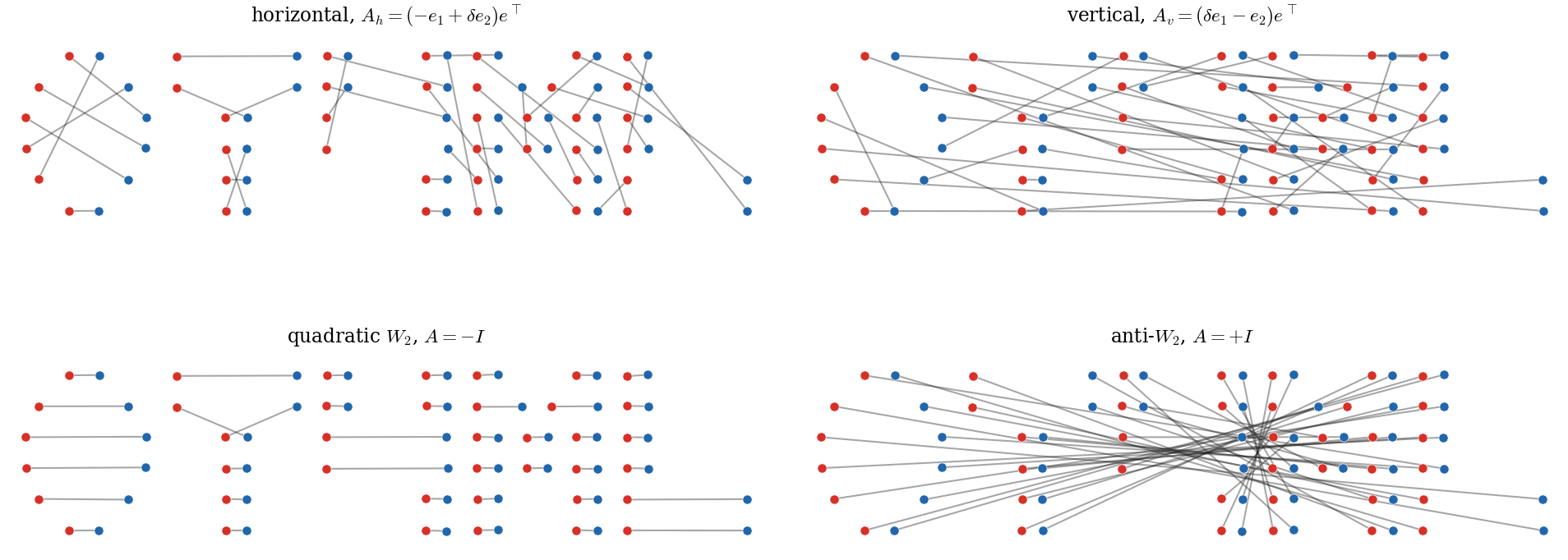
Forward solutions of the bilinear cost on the OT4ML logo point clouds. Each panel solves the equal-weight assignment problem with a different matrix ; the first two use to break rank-one ties. The source atoms are red, the target atoms are blue, and the gray segments give one deterministic optimal bijection.
This elementary model already contains the quadratic Wasserstein assignment. Adding to a cost matrix a term depending only on or only on shifts all feasible couplings by the same constant, and therefore does not change the optimizer. Since
the usual quadratic Wasserstein assignment has the same optimizer as the bilinear cost with , up to these marginal-only terms and an irrelevant positive factor. The inverse problem goes in the opposite direction: after observing a coupling, one asks which matrices could have generated it. The next figure generates an observed coupling from this cost on two empirical mixtures of Gaussians, and then evaluates along the anisotropic path
so that recovers the matrix that generated the observed coupling. Equivalently, with equal weights, , and the plotted loss is the Kantorovich gap
Because is affine and the Kantorovich value is a minimum of affine functions over the fixed polytope , this one-dimensional gap is convex and piecewise affine. Its zero set can contain an interval for a small sample, reflecting the fact that the same observed coupling remains optimal for a cone of nearby costs.
Figure Div generates an observed coupling from this cost on two empirical mixtures of Gaussians, and then evaluates along the anisotropic path
Interactive panel. Vary sample size and cost rotation to recompute the empirical Kantorovich gap along the one-parameter inverse-OT path.
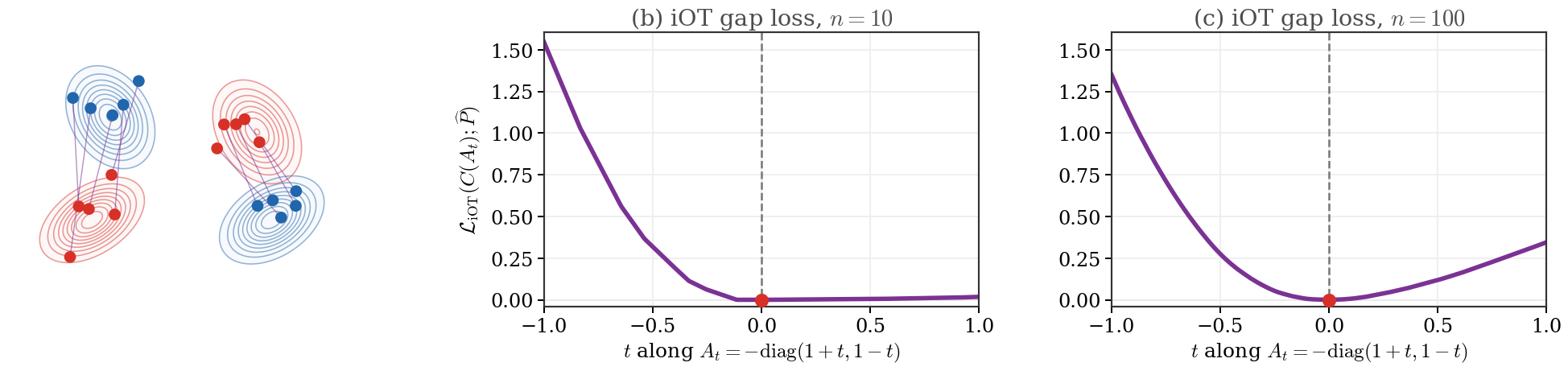
Inverse-OT gap loss for a bilinear cost. Panel (a): two empirical mixtures of two Gaussians are matched with the cost for , which gives the same optimizer as the quadratic cost; red and blue level sets display the two sampling densities. Panels (b,c): the unregularized Fenchel--Young Kantorovich gap along for and , using the same vertical scale. The red dot marks the generating parameter ; the curves are convex and piecewise affine.
The comparison between and illustrates a statistical effect: as the number of sampled points grows, the flat zero region can shrink to a sharper piecewise-affine minimum. A finite-sample linear-programming gap remains polyhedral and has no classical second derivative inside its cells. Curvature is instead a population phenomenon. Peyré, Poon and Tron Peyré et al., 2026 prove local curvature and identifiability modulo the natural cost invariances for smooth positive marginals under a nondegeneracy condition. They also identify affine-map settings, including Gaussian or elliptical examples, as genuinely degenerate cases. Larger samples can reveal population curvature, but do not remove structural non-identifiability by themselves.
Proof
For a fixed cost , Kantorovich duality gives
Since has marginals , every dual feasible pair satisfies
This nonnegative quantity is exactly the primal-dual gap of . It vanishes if and only if reaches the dual value and is therefore optimal. If is affine, , and and are convex, the constraints and objective in the displayed program are convex. If is allowed and minimizes , then is a trivial minimizer; this proves the need for normalization.
The formulation avoids differentiating through a forward OT solver: it learns a normalized cost by making the observed plan nearly satisfy complementary slackness. In statistical settings, is only partially observed or noisy, so one adds sparsity, low-rank, smoothness or metric constraints to select a meaningful representative Dupuy et al., 2019Andrade et al., 2024. For entropic OT, the optimality condition becomes smoother:
which leads to likelihood-based or KL-based convex objectives when is affine, and connects inverse OT with generalized Sinkhorn iterations and transport-regularized inverse problems Karlsson & Ringh, 2017Ma et al., 2020.
Weak Optimal Transport¶
Weak OT relaxes the cost so that it depends on the conditional distribution of destinations rather than only on pointwise pairs. It is useful when a source point is allowed to choose a randomized response and the model only penalizes an aggregate of that response, such as its conditional mean.
Barycentric Projection of a Coupling¶
The first object to isolate is the map obtained by collapsing each conditional law to its barycenter.
The projected target records the distribution of conditional means, not the full second marginal. Thus it is generally different from ; if is induced by a map, then and . This projection is not an optimal map for an arbitrary coupling: a deterministic rotation of a radially symmetric source, for example, projects to the rotation itself, whereas the optimal map from the source to itself is the identity. The useful positive statement is attached to quadratic optimal plans, as in the tangent-space viewpoint on developed by Ambrosio, Gigli and Savare Ambrosio et al., 2006.
Proof
By the cyclic-monotonicity characterization of quadratic optimality, is concentrated on a -cyclically monotone set for . This means that every finite cycle satisfies
After changing the disintegration on an -negligible set, is supported on the section for -almost every . Choose in this full-measure set and independently sample . Applying the cyclic inequality to and taking expectations gives
Thus is concentrated on a cyclically monotone graph. By the cyclic-monotonicity characterization of quadratic optimality, this plan is optimal between its two marginals.
Weak Transport Costs¶
Weak transport costs use the same disintegration but allow the objective to depend on the whole conditional law, or on summaries such as the barycentric projection (142). The framework was introduced through general transport costs and weak transport inequalities, with existence, duality and optimality conditions developed on Polish spaces Gozlan et al., 2017Backhoff Veraguas et al., 2019. For a weak cost , the weak OT value is
The classical Kantorovich problem is recovered when , because the objective then becomes . The genuinely weak behavior starts when is nonlinear in .
Proof
The definition of gives
Integration and the second-marginal constraint prove weak duality. For the converse, lift a kernel to on . Relaxing the graph constraint gives probability measures whose first marginal is and whose intensity satisfies
This relaxation leaves the value unchanged. Disintegrate and replace by its barycenter . The intensity is preserved and convexity of cannot increase the objective. The relaxed feasible set is compact and its integral objective is lower semicontinuous. Fenchel--Rockafellar duality for the affine intensity constraint therefore has no gap. Its continuous multiplier is ; minimization in gives and the constraint contributes . See Backhoff Veraguas et al., 2019 for the Polish-space formulation.
Proof
Let be any coupling and disintegrate it as . By Jensen’s inequality,
Integrating in gives . Taking the infimum over proves the claim.
Figure Div separates the full conditional coupling from its barycentric projection, making explicit which part of each conditional law is retained by the weak cost.
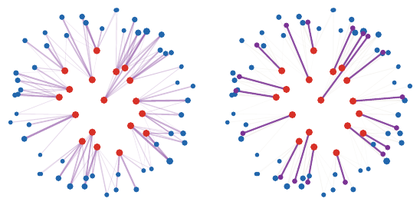
Weak barycentric transport on a small disk-to-annulus coupling. The left panel shows the full conditional laws: each red source atom splits its mass among several blue target atoms, with segment thickness proportional to transported mass. The right panel collapses each conditional law to its barycenter , shown in violet. The barycentric weak cost only sees the red-to-violet displacement, and therefore ignores the conditional spread around each barycenter.
The interactive demo lets each source point split toward several targets. Increasing the split count or spread usually increases the full quadratic cost while the weak barycentric cost can remain much smaller.
Interactive panel. Use the spread and barycentric controls to compare full weak conditional laws with their barycentric projections.
The barycentric cost is the canonical example to keep in mind: admissibility still constrains the full conditional laws to have second marginal , but the objective only charges the displacement from to and ignores the conditional variance around this barycenter. This connects weak OT with martingale transport, Strassen-type convex-order constraints, barycentric projections and learning problems where conditional averages are meaningful objects.
Martingale Optimal Transport¶
Martingale OT is the extreme barycentric version of the weak viewpoint: a source point may split randomly, but the average destination must remain equal to the source point. This turns the barycentric projection from an object used in the cost into a hard constraint.
The terminology comes from probability: if , then (153) is exactly . Hence martingale OT is a Kantorovich problem with the usual two marginal constraints plus a barycentric constraint on the conditional laws. Equivalently, the barycentric projected coupling must be the diagonal coupling . This is stronger than merely asking the projected target to equal , since a nontrivial measure-preserving map could have the same projected marginal without satisfying pointwise. Martingale OT is central in robust finance, where one transports today prices to tomorrow prices without introducing drift, and has led to a rich martingale transport theory Beiglböck et al., 2013Galichon et al., 2014Dolinsky & Soner, 2014Guo & Obłój, 2019.
Stochastic Orders¶
The admissibility of constrained couplings is governed by stochastic order. The basic principle is that inequalities tested against a class of functions are equivalent to the existence of couplings satisfying a pointwise or conditional constraint. Strassen’s theorem is the canonical result of this kind Strassen, 1965.
Proof
A coupling supported on immediately gives the integral inequality for every increasing . Conversely, testing approximate indicators of intervals gives for all continuity points of the distribution functions. If is uniform on and are the generalized quantiles, then and have laws and , and the inequality between distribution functions gives almost surely.
Convex Order and Martingale Feasibility¶
For martingale OT, the pointwise order constraint is replaced by a barycentric constraint on conditional laws. The corresponding order is the convex order. For ,
For finite-first-moment measures, it is enough to test continuous convex functions with at most linear growth. Testing affine functions gives equality of means, while the remaining convex tests say that is more spread out than . Strassen’s martingale theorem says that this spread condition is exactly what is needed to realize from by mean-preserving randomization.
Proof
If is a martingale coupling, then Jensen’s inequality gives, for every convex ,
and integration in gives .
Conversely, assume . First suppose both measures are supported in a compact convex set . Separate from the closed convex set of probability measures on reachable from by martingale kernels supported in . If were not in this set, a continuous separating function would satisfy
For fixed , optimizing over probability measures on with barycenter gives the concave envelope . Thus the right-hand side is . Convex order is equivalently the reverse inequality for concave functions, so
a contradiction. For general measures in , the same separation argument is carried out in the topology, whose continuous test functions have at most linear growth. Compactness is replaced by tightness and uniform integrability of first moments; these properties also make the set of attainable second marginals closed and preserve the martingale constraint under limits. This is the standard extension in Strassen’s theorem Strassen, 1965.
The same theorem gives an exact geometric description of the barycentric weak cost: weak OT transports to the closest measure below in convex order.
Proof
Let , set , and denote its law by . Conditional Jensen shows , while couples and . Hence
Conversely, fix . Strassen’s theorem gives a martingale coupling from to . Glue it conditionally to an optimal coupling between and . Then , and conditional Jensen gives
Taking the two infima proves the identity; see Backhoff Veraguas et al., 2019 for existence and finer structure of the projected measure.
Theorem Theorem: Strassen’s Martingale Theorem explains why convex order is the right admissibility notion for martingale OT: it is exactly the feasibility condition for the martingale constraint. If , then and the martingale OT value is , independently of the cost. If , then the optimization problem is nonempty and the cost selects, among all mean-preserving splittings of each source point, the martingale coupling best adapted to the application. This is the probabilistic meaning of the barycentric constraint: mass may branch, but it cannot drift on average.
For Gaussian measures with the same mean, convex order reduces to the Loewner order on covariance matrices:
Indeed, if , then is obtained from by adding independent centered Gaussian noise. Conversely, testing the convex quadratic functions gives the Loewner inequality.
Figure Div gives a discrete non-Gaussian counterpart: centered conditional kernels provide a feasible martingale plan, while optimizing the transport cost selects a much sparser plan with the same marginals and barycentric constraint.
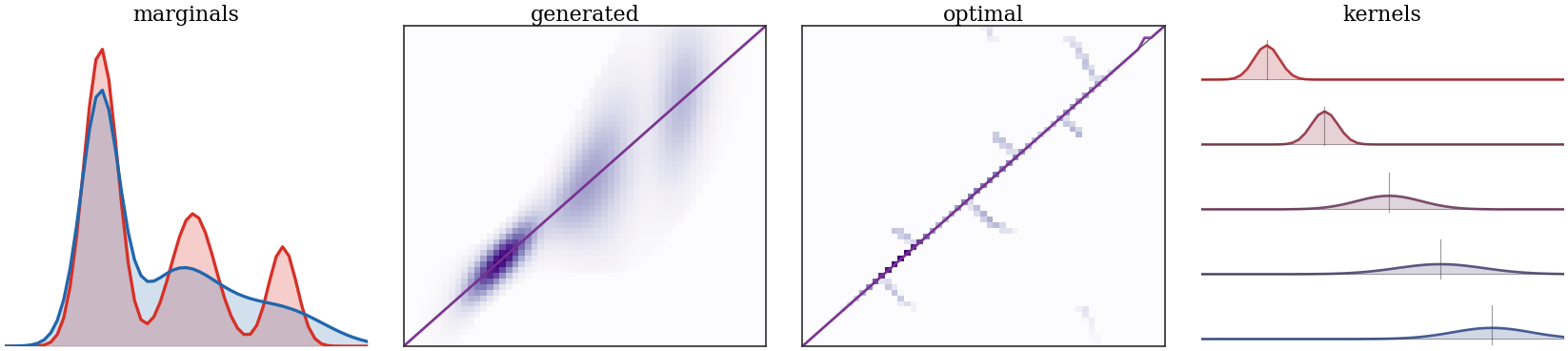
A discrete one-dimensional martingale OT example. The source is a red Gaussian mixture on a grid. A first feasible plan is generated by centered kernels , whose discrete barycenter is . Keeping the same marginals, the third panel solves the martingale OT linear program with row, column, and constraints . The optimized plan is much sparser, while both plans have the identity barycentric projection.
Interactive panel. Change the space-varying kernel width and source skew to see how centered conditional kernels create a more spread target while preserving barycentric centering.
- Agueh, M., & Carlier, G. (2011). Barycenters in the Wasserstein space. SIAM Journal on Mathematical Analysis, 43(2), 904–924.
- Carlier, G., & Ekeland, I. (2010). Matching for teams. Economic Theory, 42(2), 397–418.
- Anderes, E., Borgwardt, S., & Miller, J. (2016). Discrete Wasserstein barycenters: optimal transport for discrete data. Mathematical Methods of Operations Research, 84(2), 389–409.
- Álvarez Esteban, P. C., del Barrio, E., Cuesta-Albertos, J., & Matrán, C. (2016). A fixed-point approach to barycenters in Wasserstein space. Journal of Mathematical Analysis and Applications, 441(2), 744–762. 10.1016/j.jmaa.2016.04.045
- Le Gouic, T., & Loubes, J.-M. (2016). Existence and consistency of Wasserstein barycenters. Probability Theory and Related Fields, 168, 901–917.
- Bhatia, R., Jain, T., & Lim, Y. (2019). On the Bures–Wasserstein distance between positive definite matrices. Expositiones Mathematicae, 37(2), 165–191. 10.1016/j.exmath.2018.01.002
- Rüschendorf, L., & Uckelmann, L. (2002). On the n-coupling problem. Journal of Multivariate Analysis, 81(2), 242–258.
- Herman, G. (1980). Image Reconstruction from Projections: the Fundamentals of Computerized Tomography. Academic Press.
- Bonneel, N., Rabin, J., Peyré, G., & Pfister, H. (2015). Sliced and Radon Wasserstein barycenters of measures. Journal of Mathematical Imaging and Vision, 51(1), 22–45.
- Cramér, H., & Wold, H. (1936). Some Theorems on Distribution Functions. Journal of the London Mathematical Society, s1-11(4), 290–294. 10.1112/jlms/s1-11.4.290
- Cuturi, M., & Doucet, A. (2014). Fast computation of Wasserstein barycenters. Proceedings of the 31st International Conference on Machine Learning, 32, 685–693. https://proceedings.mlr.press/v32/cuturi14.html
- Cuturi, M., & Peyré, G. (2016). A smoothed dual approach for variational Wasserstein problems. SIAM Journal on Imaging Sciences, 9(1), 320–343.
- Benamou, J.-D., Carlier, G., Cuturi, M., Nenna, L., & Peyré, G. (2015). Iterative Bregman projections for regularized transportation problems. SIAM Journal on Scientific Computing, 37(2), A1111–A1138.
- Solomon, J., De Goes, F., Peyré, G., Cuturi, M., Butscher, A., Nguyen, A., Du, T., & Guibas, L. (2015). Convolutional Wasserstein distances: efficient optimal transportation on geometric domains. ACM Transactions on Graphics, 34(4), 66:1-66:11.
- Bigot, J., & Klein, T. (2018). Characterization of barycenters in the Wasserstein space by averaging optimal transport maps. ESAIM: Probability and Statistics, 22, 35–57. 10.1051/ps/2017020